使用语义搜索和 Qdrant 导航你的代码库
| 时间:45 分钟 | 级别:中级 |
|---|
你也可以通过 Qdrant 语义搜索来丰富你的应用程序。在本教程中,我们将介绍如何使用 Qdrant 导航代码库,帮助你找到相关的代码片段。作为示例,我们将使用 Qdrant 自己的源代码,它主要由 Rust 编写。
方法
我们希望使用自然的语义查询来搜索代码库,并根据相似的逻辑搜索代码。你可以通过嵌入来实现这些任务
- 用于自然语言处理(NLP)的通用神经编码器,在本例中是
sentence-transformers/all-MiniLM-L6-v2。 - 专用于代码到代码相似性搜索的嵌入。我们使用
jina-embeddings-v2-base-code模型。
为了让我们的代码适用于 all-MiniLM-L6-v2,我们对代码进行预处理,使其更接近自然语言文本。Jina 嵌入模型支持多种标准编程语言,因此无需预处理代码片段。我们可以直接使用代码。
基于 NLP 的搜索依赖于函数签名,但代码搜索可能会返回更小的部分,例如循环。因此,如果我们从 NLP 模型获得特定的函数签名,并从代码模型获得其部分实现,我们会合并结果并突出显示重叠部分。
数据准备
将应用程序源代码分块成更小的部分是一项非简单的任务。一般来说,函数、类方法、结构体、枚举以及所有其他特定于语言的构造都是很好的块候选。它们足够大,可以包含一些有意义的信息,但又足够小,可以由上下文窗口有限的嵌入模型处理。你还可以使用文档字符串、注释和其他元数据来丰富块的附加信息。

解析代码库
虽然我们的示例使用了 Rust,但你可以将我们的方法应用于任何其他语言。你可以使用与语言服务器协议 (LSP) 兼容的工具来解析代码。你可以使用 LSP 构建代码库的图,然后提取块。我们使用了rust-analyzer来完成这项工作。我们将解析后的代码库导出为LSIF格式,这是一种代码智能数据的标准。接着,我们使用 LSIF 数据导航代码库并提取块。有关详细信息,请参阅我们的代码搜索演示。
然后我们将这些块导出到 JSON 文档中,其中不仅包含代码本身,还包含代码在项目中的位置信息作为上下文。例如,请看 common 模块中 IsReady 结构体下 await_ready_for_timeout 函数的描述
{
"name":"await_ready_for_timeout",
"signature":"fn await_ready_for_timeout (& self , timeout : Duration) -> bool",
"code_type":"Function",
"docstring":"= \" Return `true` if ready, `false` if timed out.\"",
"line":44,
"line_from":43,
"line_to":51,
"context":{
"module":"common",
"file_path":"lib/collection/src/common/is_ready.rs",
"file_name":"is_ready.rs",
"struct_name":"IsReady",
"snippet":" /// Return `true` if ready, `false` if timed out.\n pub fn await_ready_for_timeout(&self, timeout: Duration) -> bool {\n let mut is_ready = self.value.lock();\n if !*is_ready {\n !self.condvar.wait_for(&mut is_ready, timeout).timed_out()\n } else {\n true\n }\n }\n"
}
}
你可以在我们的 Google Cloud Storage 存储桶中的structures.jsonl 文件中查看以 JSON 格式解析的 Qdrant 结构。下载它并将其用作我们代码搜索的数据源。
wget https://storage.googleapis.com/tutorial-attachments/code-search/structures.jsonl
接下来,加载文件并将行解析为字典列表
import json
structures = []
with open("structures.jsonl", "r") as fp:
for i, row in enumerate(fp):
entry = json.loads(row)
structures.append(entry)
代码到自然语言的转换
每种编程语言都有自己的语法,这并不是自然语言的一部分。因此,通用模型可能无法直接理解代码。然而,我们可以通过去除代码特定的部分并包含额外上下文(如模块、类、函数和文件名)来规范化数据。我们采取了以下步骤
- 提取函数、方法或其他代码构造的签名。
- 将驼峰式和蛇形命名法分割成单独的单词。
- 获取文档字符串、注释和其他重要元数据。
- 使用预定义的模板从提取的数据构建一个句子。
- 删除特殊字符并用空格替换。
作为输入,期望具有相同结构的字典。定义一个 textify 函数来执行转换。我们将使用 inflection 库来处理不同的命名约定。
pip install inflection
安装所有依赖项后,我们定义 textify 函数
import inflection
import re
from typing import Dict, Any
def textify(chunk: Dict[str, Any]) -> str:
# Get rid of all the camel case / snake case
# - inflection.underscore changes the camel case to snake case
# - inflection.humanize converts the snake case to human readable form
name = inflection.humanize(inflection.underscore(chunk["name"]))
signature = inflection.humanize(inflection.underscore(chunk["signature"]))
# Check if docstring is provided
docstring = ""
if chunk["docstring"]:
docstring = f"that does {chunk['docstring']} "
# Extract the location of that snippet of code
context = (
f"module {chunk['context']['module']} "
f"file {chunk['context']['file_name']}"
)
if chunk["context"]["struct_name"]:
struct_name = inflection.humanize(
inflection.underscore(chunk["context"]["struct_name"])
)
context = f"defined in struct {struct_name} {context}"
# Combine all the bits and pieces together
text_representation = (
f"{chunk['code_type']} {name} "
f"{docstring}"
f"defined as {signature} "
f"{context}"
)
# Remove any special characters and concatenate the tokens
tokens = re.split(r"\W", text_representation)
tokens = filter(lambda x: x, tokens)
return " ".join(tokens)
现在我们可以使用 textify 将所有代码块转换为文本表示
text_representations = list(map(textify, structures))
await_ready_for_timeout 函数的描述如下所示
Function Await ready for timeout that does Return true if ready false if timed out defined as Fn await ready for timeout self timeout duration bool defined in struct Is ready module common file is_ready rs
摄取流水线
接下来,我们将构建一个用于数据向量化的流水线,并为两种嵌入模型设置语义搜索机制。
构建 Qdrant 集合
我们使用带有 fastembed 额外功能的 qdrant-client 库来与 Qdrant 服务器交互并在本地生成向量嵌入。让我们安装它
pip install "qdrant-client[fastembed]"
当然,向量搜索需要一个运行中的 Qdrant 服务器。如果你需要一个,可以使用本地 Docker 容器或使用Qdrant Cloud部署。你可以使用其中任何一种来学习本教程。配置连接参数
QDRANT_URL = "https://my-cluster.cloud.qdrant.io:6333" # https://:6333 for local instance
QDRANT_API_KEY = "THIS_IS_YOUR_API_KEY" # None for local instance
然后使用该库创建一个集合
from qdrant_client import QdrantClient, models
client = QdrantClient(QDRANT_URL, api_key=QDRANT_API_KEY)
client.create_collection(
"qdrant-sources",
vectors_config={
"text": models.VectorParams(
size=client.get_embedding_size(
model_name="sentence-transformers/all-MiniLM-L6-v2"
),
distance=models.Distance.COSINE,
),
"code": models.VectorParams(
size=client.get_embedding_size(
model_name="jinaai/jina-embeddings-v2-base-code"
),
distance=models.Distance.COSINE,
),
},
)
我们新创建的集合已准备好接收数据。让我们上传嵌入
import uuid
# Extract the code snippets from the structures to a separate list
code_snippets = [
structure["context"]["snippet"] for structure in structures
]
points = [
models.PointStruct(
id=uuid.uuid4().hex,
vector={
"text": models.Document(
text=text, model="sentence-transformers/all-MiniLM-L6-v2"
),
"code": models.Document(
text=code, model="jinaai/jina-embeddings-v2-base-code"
),
},
payload=structure,
)
for text, code, structure in zip(text_representations, code_snippets, structures)
]
# Note: This might take a while since inference happens implicitly.
# Parallel processing can help.
# But too many processes may trigger swap memory and hurt performance.
client.upload_points("qdrant-sources", points=points, batch_size=64)
在内部,qdrant-client 使用FastEmbed将我们的文档隐式转换为它们的向量表示。上传的点会立即可用于搜索。接下来,查询集合以查找相关的代码片段。
查询代码库
我们使用其中一个模型来搜索集合。从文本嵌入开始。运行以下查询“如何计算集合中的点?”。查看结果。
query = "How do I count points in a collection?"
hits = client.query_points(
"qdrant-sources",
query=models.Document(text=query, model="sentence-transformers/all-MiniLM-L6-v2"),
using="text",
limit=5,
).points
现在,查看结果。下表列出了模块、文件名和得分。每一行都包含一个指向签名的链接,显示为文件中的代码块。
| 模块 | 文件名 | 得分 | 签名 |
|---|---|---|---|
| toc | point_ops.rs | 0.59448624 | pub async fn count |
| operations | types.rs | 0.5493385 | pub struct CountRequestInternal |
| collection_manager | segments_updater.rs | 0.5121002 | pub(crate) fn upsert_points<'a, T> |
| collection | point_ops.rs | 0.5063539 | pub async fn count |
| map_index | mod.rs | 0.49973983 | fn get_points_with_value_count<Q> |
看来我们找到了一些相关的代码结构。让我们用代码嵌入尝试同样的操作
hits = client.query_points(
"qdrant-sources",
query=models.Document(text=query, model="jinaai/jina-embeddings-v2-base-code"),
using="code",
limit=5,
).points
输出
| 模块 | 文件名 | 得分 | 签名 |
|---|---|---|---|
| field_index | geo_index.rs | 0.73278356 | fn count_indexed_points |
| numeric_index | mod.rs | 0.7254976 | fn count_indexed_points |
| map_index | mod.rs | 0.7124739 | fn count_indexed_points |
| map_index | mod.rs | 0.7124739 | fn count_indexed_points |
| fixtures | payload_context_fixture.rs | 0.706204 | fn total_point_count |
尽管不同模型检索到的得分不可比较,但我们可以看到结果是不同的。代码嵌入和文本嵌入可以捕获代码库的不同方面。我们可以使用这两种模型来查询集合,然后结合结果,通过单个批量请求获得最相关的代码片段。
responses = client.query_batch_points(
collection_name="qdrant-sources",
requests=[
models.QueryRequest(
query=models.Document(
text=query, model="sentence-transformers/all-MiniLM-L6-v2"
),
using="text",
with_payload=True,
limit=5,
),
models.QueryRequest(
query=models.Document(
text=query, model="jinaai/jina-embeddings-v2-base-code"
),
using="code",
with_payload=True,
limit=5,
),
],
)
results = [response.points for response in responses]
输出
| 模块 | 文件名 | 得分 | 签名 |
|---|---|---|---|
| toc | point_ops.rs | 0.59448624 | pub async fn count |
| operations | types.rs | 0.5493385 | pub struct CountRequestInternal |
| collection_manager | segments_updater.rs | 0.5121002 | pub(crate) fn upsert_points<'a, T> |
| collection | point_ops.rs | 0.5063539 | pub async fn count |
| map_index | mod.rs | 0.49973983 | fn get_points_with_value_count<Q> |
| field_index | geo_index.rs | 0.73278356 | fn count_indexed_points |
| numeric_index | mod.rs | 0.7254976 | fn count_indexed_points |
| map_index | mod.rs | 0.7124739 | fn count_indexed_points |
| map_index | mod.rs | 0.7124739 | fn count_indexed_points |
| fixtures | payload_context_fixture.rs | 0.706204 | fn total_point_count |
这是如何使用不同模型并结合结果的一个示例。在实际应用场景中,你可能还需要进行一些重排序和去重,以及对结果进行额外的处理。
代码搜索演示
我们的代码搜索演示使用以下过程
- 用户发送查询。
- 两个模型同时对查询进行向量化。我们得到两个不同的向量。
- 两个向量并行用于查找相关的代码片段。我们期望从 NLP 搜索中获得 5 个示例,从代码搜索中获得 20 个示例。
- 一旦我们检索到两个向量的结果,我们将它们在以下场景之一中合并
- 如果两种方法返回不同的结果,我们优先选择通用模型(NLP)的结果。
- 如果搜索结果之间存在重叠,我们合并重叠的代码片段。
在截图中,我们搜索 flush of wal。结果显示了相关的代码,这是从两个模型合并而来的。请注意第 621-629 行高亮显示的代码。这是两个模型都认同的部分。
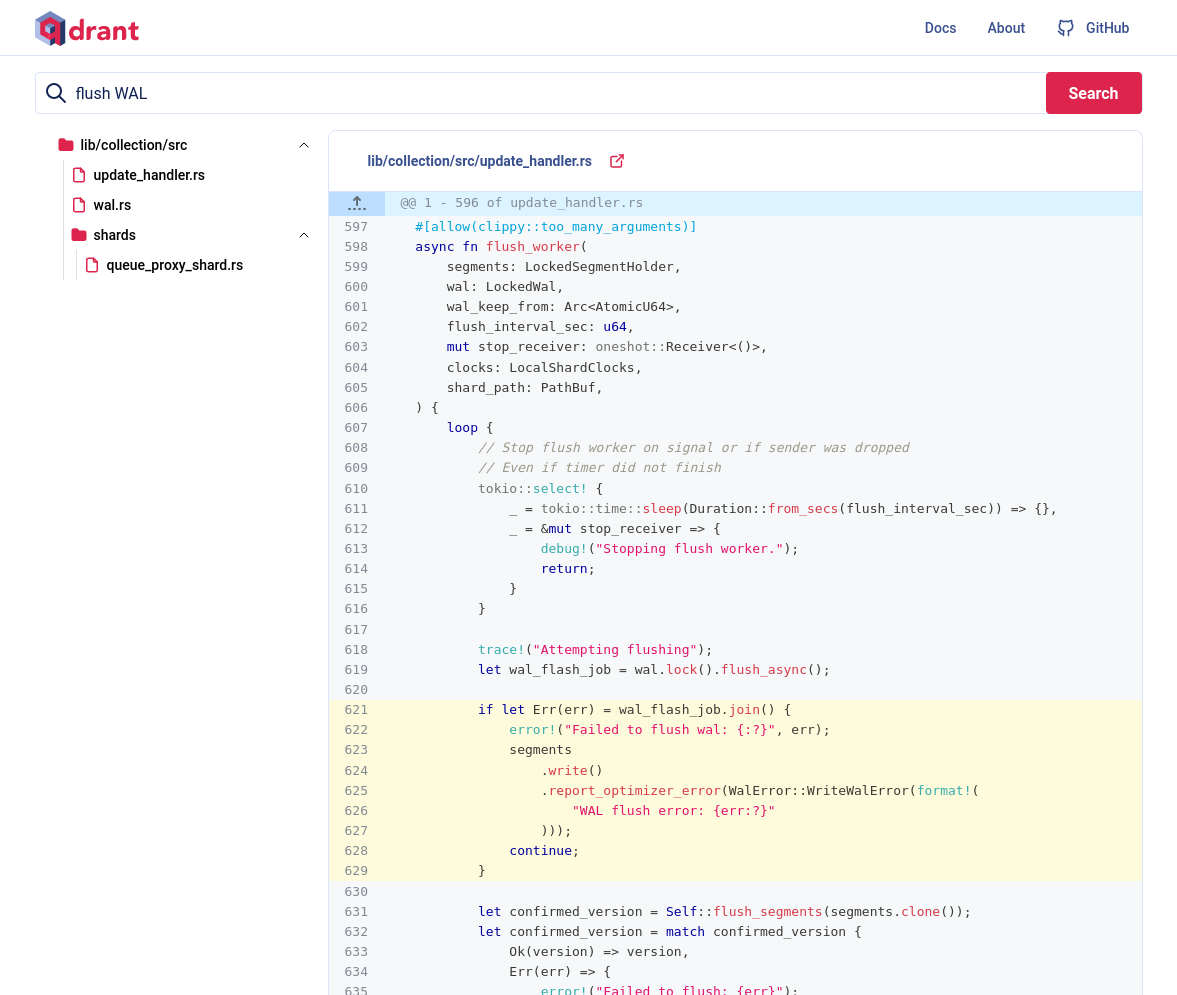
现在你看到了语义代码智能的实际应用。
分组结果
你可以通过按载荷属性对结果进行分组来改进搜索结果。在本例中,我们可以按模块对结果进行分组。如果使用代码嵌入,我们可能会看到来自 map_index 模块的多个结果。让我们对结果进行分组,假设每个模块只显示一个结果
results = client.query_points_groups(
collection_name="qdrant-sources",
using="code",
query=models.Document(text=query, model="jinaai/jina-embeddings-v2-base-code"),
group_by="context.module",
limit=5,
group_size=1,
)
输出
| 模块 | 文件名 | 得分 | 签名 |
|---|---|---|---|
| field_index | geo_index.rs | 0.73278356 | fn count_indexed_points |
| numeric_index | mod.rs | 0.7254976 | fn count_indexed_points |
| map_index | mod.rs | 0.7124739 | fn count_indexed_points |
| fixtures | payload_context_fixture.rs | 0.706204 | fn total_point_count |
| hnsw_index | graph_links.rs | 0.6998417 | fn num_points |
通过分组功能,我们可以获得更多样化的结果。
总结
本教程演示了如何使用 Qdrant 导航代码库。有关端到端的实现,请查阅代码搜索笔记本和code-search-demo。你还可以访问运行中的代码搜索演示,它通过 Web 界面提供了 Qdrant 代码库的搜索功能。