使用 Qdrant 向量数据库对混合搜索结果进行重新排序
混合搜索结合了密集检索和稀疏检索,以提供精确而全面的结果。通过使用 ColBERT 添加重新排序,您可以进一步优化搜索输出,以实现最大相关性。
在本指南中,我们将向您展示如何在 Qdrant 中实现带有重新排序的混合搜索,利用密集、稀疏和后期交互嵌入来创建高效、高精度的搜索系统。让我们开始吧!
概述
让我们首先分解架构
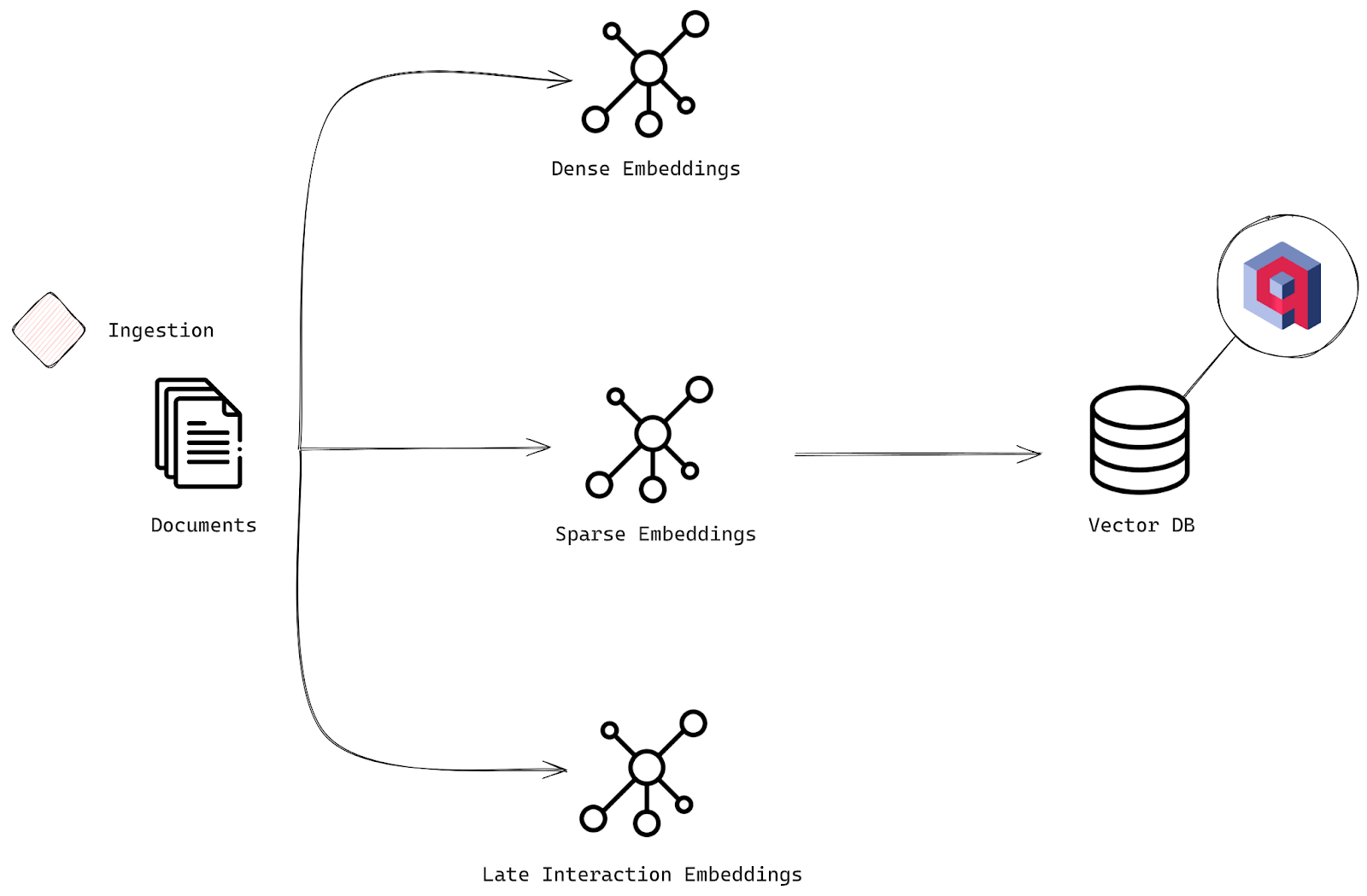
在向量数据库 (VDB) 中处理密集、稀疏和后期交互嵌入
摄取阶段
我们将按以下方式设置高级混合搜索。该过程与我们之前所做的类似,但增加了一些强大的功能
- 文档:就像以前一样,我们从原始输入开始——我们一组需要索引以进行搜索的文档。
- 密集嵌入:我们将为每个文档生成密集嵌入,就像在基本搜索中一样。这些嵌入捕获文本背后更深层次的语义含义。
- 稀疏嵌入:这就是有趣的地方。除了密集嵌入之外,我们还将使用更传统的、基于关键词的方法创建稀疏嵌入。具体来说,我们将使用 BM25,这是一种概率检索模型。BM25 根据文档术语与给定查询的相关程度对文档进行排名,同时考虑术语出现的频率、文档长度以及术语在所有文档中的常见程度。它非常适合关键词密集型搜索。
- 后期交互嵌入:现在,我们加入 ColBERT 的魔力。ColBERT 使用两阶段方法。首先,它使用 BERT 为查询和文档生成上下文嵌入,然后执行后期交互——使用点积高效匹配这些嵌入以微调相关性。此步骤允许进行更深层次的上下文理解,确保您获得最精确的结果。
- 向量数据库:所有这些嵌入——密集、稀疏和后期交互——都存储在像 Qdrant 这样的向量数据库中。这使您能够根据多个相关性层高效地搜索、检索和重新排序文档。
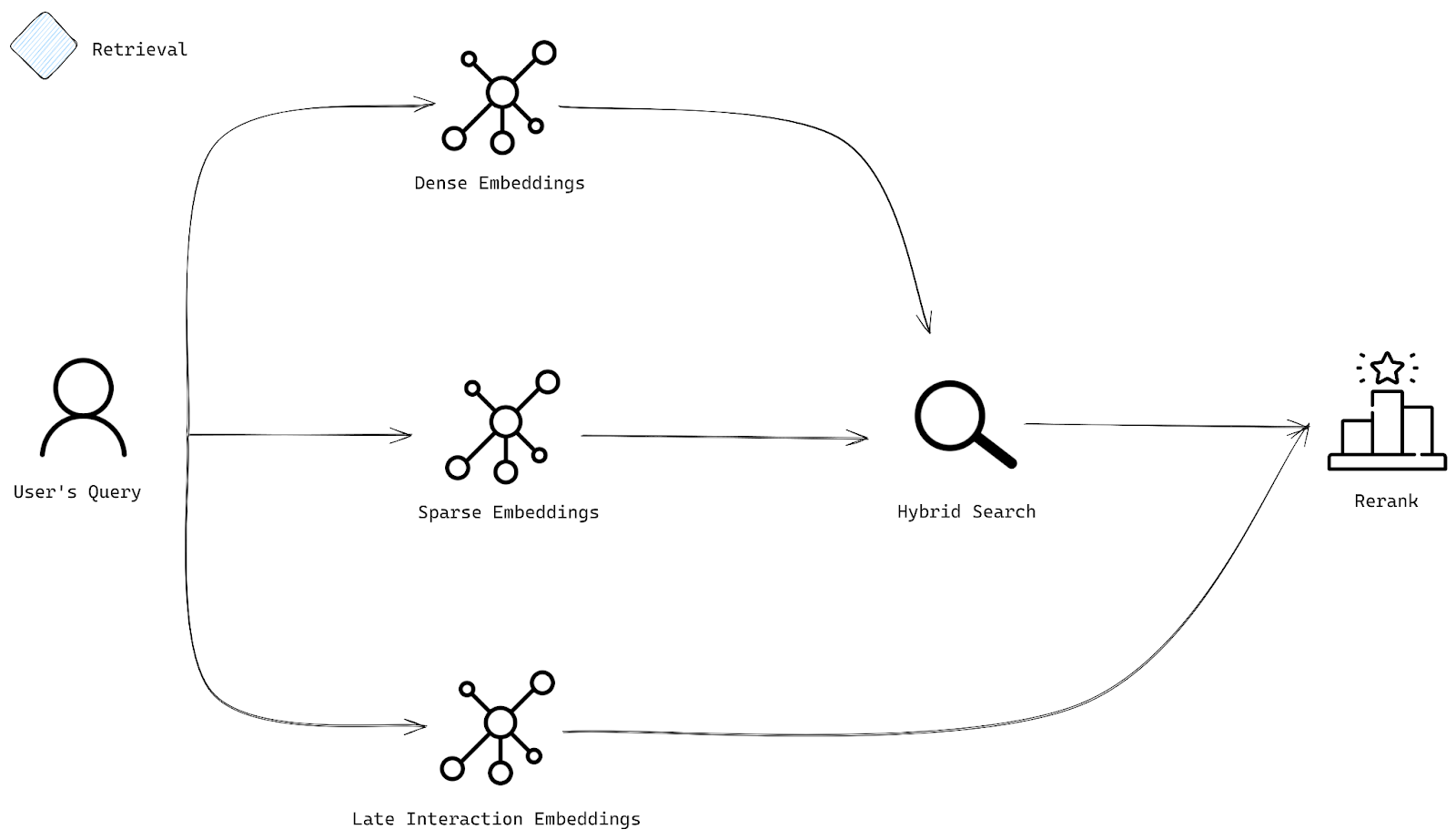
搜索系统中的查询检索和重新排序过程
检索阶段
现在,让我们谈谈用户提交查询后,我们将如何获取最佳结果
- 用户查询:用户输入一个查询,该查询被转换为多种类型的嵌入。我们谈论的是既能捕获更深层含义(密集)又能捕获特定关键词(稀疏)的表示。
- 嵌入:查询被转换为各种嵌入——一些用于理解语义(密集嵌入),另一些用于关注关键词匹配(稀疏嵌入)。
- 混合搜索:我们的混合搜索使用密集和稀疏嵌入来查找最相关的文档。密集嵌入确保我们捕获查询的整体含义,而稀疏嵌入确保我们不会遗漏那些关键、重要的术语。
- 重新排序:一旦我们获得了一组文档,最后一步就是重新排序。这就是后期交互嵌入发挥作用的地方,它通过优先考虑真正符合用户意图的文档,为您提供不仅相关而且根据您的查询进行调整的结果。
实施
让我们在本节中看看它的实际应用。
附加设置
这一次,我们使用的是 FastEmbed——一个轻量级的 Python 库,用于生成嵌入,并且它开箱即用支持流行的文本模型。首先,您需要安装它
pip install fastembed
以下是我们将从 FastEmbed 中提取的模型
from fastembed import TextEmbedding, LateInteractionTextEmbedding, SparseTextEmbedding
摄取
像以前一样,我们将文档转换为嵌入,但由于 FastEmbed,这个过程甚至更简单,因为您需要的所有模型都方便地集中在一个位置。
嵌入
首先,让我们加载所需的模型
dense_embedding_model = TextEmbedding("sentence-transformers/all-MiniLM-L6-v2")
bm25_embedding_model = SparseTextEmbedding("Qdrant/bm25")
late_interaction_embedding_model = LateInteractionTextEmbedding("colbert-ir/colbertv2.0")
现在,让我们将文档转换为嵌入
dense_embeddings = list(dense_embedding_model.embed(doc for doc in documents))
bm25_embeddings = list(bm25_embedding_model.embed(doc for doc in documents))
late_interaction_embeddings = list(late_interaction_embedding_model.embed(doc for doc in documents))
由于我们正在处理多种类型的嵌入(密集、稀疏和后期交互),因此我们需要将它们存储在支持多向量设置的集合中。我们之前创建的集合在这里不起作用,因此我们将创建一个专门用于处理这些不同类型嵌入的新集合。
创建集合
现在,我们正在 Qdrant 中为我们的混合搜索设置一个新集合,其中包含正确的配置以处理我们正在使用的所有不同向量类型。
以下是操作方法
from qdrant_client.models import Distance, VectorParams, models
client.create_collection(
"hybrid-search",
vectors_config={
"all-MiniLM-L6-v2": models.VectorParams(
size=len(dense_embeddings[0]),
distance=models.Distance.COSINE,
),
"colbertv2.0": models.VectorParams(
size=len(late_interaction_embeddings[0][0]),
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM,
),
hnsw_config=models.HnswConfigDiff(m=0) # Disable HNSW for reranking
),
},
sparse_vectors_config={
"bm25": models.SparseVectorParams(modifier=models.Modifier.IDF
)
}
)
这里发生了什么?我们正在创建一个名为“hybrid-search”的集合,并且正在对其进行配置以处理
- 使用余弦距离进行比较的来自模型 all-MiniLM-L6-v2 的密集嵌入。
- 来自 colbertv2.0 的后期交互嵌入,也使用余弦距离,但使用多向量配置来使用最大相似度比较器。请注意,我们在
colbertv2.0向量中设置m=0以防止索引,因为重新排序不需要它。 - 来自 BM25 的稀疏嵌入用于基于关键词的搜索。它们使用
dot_product进行相似度计算。
此设置确保所有不同类型的向量都正确存储和比较,以进行混合搜索。
更新数据
接下来,我们需要将文档及其多个嵌入插入到 hybrid-search 集合中
from qdrant_client.models import PointStruct
points = []
for idx, (dense_embedding, bm25_embedding, late_interaction_embedding, doc) in enumerate(zip(dense_embeddings, bm25_embeddings, late_interaction_embeddings, documents)):
point = PointStruct(
id=idx,
vector={
"all-MiniLM-L6-v2": dense_embedding,
"bm25": bm25_embedding.as_object(),
"colbertv2.0": late_interaction_embedding,
},
payload={"document": doc}
)
points.append(point)
operation_info = client.upsert(
collection_name="hybrid-search",
points=points
)
使用隐式嵌入计算上传
from qdrant_client.models import PointStruct
points = []
for idx, doc in enumerate(documents):
point = PointStruct(
id=idx,
vector={
"all-MiniLM-L6-v2": models.Document(text=doc, model="sentence-transformers/all-MiniLM-L6-v2"),
"bm25": models.Document(text=doc, model="Qdrant/bm25"),
"colbertv2.0": models.Document(text=doc, model="colbert-ir/colbertv2.0"),
},
payload={"document": doc}
)
points.append(point)
operation_info = client.upsert(
collection_name="hybrid-search",
points=points
)
此代码通过创建 PointStruct 对象列表将所有内容整合在一起,每个对象都包含嵌入和相应的文档。
对于每个文档,它添加
- 用于深层语义含义的密集嵌入。
- 用于强大关键词搜索的 BM25 嵌入。
- 用于精确上下文交互的 ColBERT 嵌入。
完成此操作后,使用 upsert 方法将点上传到我们的 “hybrid-search” 集合中,确保一切就绪。
检索
对于检索,是时候将用户的查询转换为所需的嵌入了。以下是操作方法
dense_vectors = next(dense_embedding_model.query_embed(query))
sparse_vectors = next(bm25_embedding_model.query_embed(query))
late_vectors = next(late_interaction_embedding_model.query_embed(query))
混合搜索的真正魔力在于 prefetch 参数。这允许您一次运行多个子查询,结合了密集和稀疏嵌入的强大功能。以下是设置方法,之后我们执行混合搜索
prefetch = [
models.Prefetch(
query=dense_vectors,
using="all-MiniLM-L6-v2",
limit=20,
),
models.Prefetch(
query=models.SparseVector(**sparse_vectors.as_object()),
using="bm25",
limit=20,
),
]
此代码通过运行两个子查询启动混合搜索
- 一个使用来自“all-MiniLM-L6-v2”的密集嵌入来捕获查询的语义含义。
- 另一个使用来自 BM25 的稀疏嵌入进行强大的关键词匹配。
每个子查询限制为 20 个结果。这些子查询使用 prefetch 参数捆绑在一起,允许它们并行运行。
重新排序
现在我们已经获得了初始混合搜索结果,是时候使用后期交互嵌入对它们进行重新排序以实现最大精度了。以下是操作方法
results = client.query_points(
"hybrid-search",
prefetch=prefetch,
query=late_vectors,
using="colbertv2.0",
with_payload=True,
limit=10,
)
使用隐式嵌入计算的查询点
prefetch = [
models.Prefetch(
query=models.Document(text=query, model="sentence-transformers/all-MiniLM-L6-v2"),
using="all-MiniLM-L6-v2",
limit=20,
),
models.Prefetch(
query=models.Document(text=query, model="Qdrant/bm25"),
using="bm25",
limit=20,
),
]
results = client.query_points(
"hybrid-search",
prefetch=prefetch,
query=models.Document(text=query, model="colbert-ir/colbertv2.0"),
using="colbertv2.0",
with_payload=True,
limit=10,
)
让我们看看应用重新排序后位置如何变化。请注意,根据后期交互嵌入的相关性,某些文档的排名是如何变化的。
| 文档 | 第一次查询排名 | 第二次查询排名 | 排名变化 | |
|---|---|---|---|---|
| 在机器学习中,特征缩放是标准化自变量或特征范围的过程。目标是确保所有特征对模型贡献相等,尤其是在像 SVM 或 k-最近邻算法中,距离计算很重要。 | 1 | 1 | 无变化 | |
| 特征缩放通常用于数据预处理,以确保特征在同一尺度上。这对于基于梯度下降的算法尤其重要,因为具有较大尺度的特征可能会对成本函数产生不成比例的影响。 | 2 | 6 | 下移 | |
| 无监督学习算法,例如聚类方法,可能会受益于特征缩放,这确保了具有较大数值范围的特征不会主导学习过程。 | 3 | 4 | 下移 | |
| 数据预处理步骤,包括特征缩放,可以显著影响机器学习模型的性能,使其成为建模管道的关键部分。 | 5 | 2 | 上移 |
太棒了!我们现在已经探索了重新排序的工作原理并成功实现了它。
重新排序的最佳实践
重新排序可以显著提高搜索结果的相关性,特别是与混合搜索结合使用时。以下是一些需要记住的最佳实践
- 实施混合重新排序:混合基于关键词(稀疏)和基于向量(密集)的搜索结果,以获得更全面的排名系统。
- 持续测试和监控:定期评估您的重新排序模型,以避免过拟合并及时调整以保持性能。
- 平衡相关性和延迟:重新排序可能计算量大,因此目标是在相关性和速度之间取得平衡。因此,第一步是检索相关文档,然后对其使用重新排序。
结论
重新排序是一个强大的工具,可以提高搜索结果的相关性,特别是与混合搜索方法结合使用时。虽然它可能由于其复杂性而增加一些延迟,但将其应用于较小的、预过滤的结果子集可确保速度和相关性。
Qdrant 提供了一个易于使用的 API,可帮助您开始构建自己的搜索引擎,因此,如果您准备好深入了解,请在 Qdrant Cloud 免费注册并开始构建