如何在 Qdrant 中有效使用多向量表示进行重排
多向量表示是 Qdrant 最强大的功能之一。然而,大多数人没有有效地使用它们,导致大量的 RAM 开销、缓慢的插入和计算资源的浪费。
在本教程中,您将学习如何在 Qdrant 中有效使用多向量表示。
什么是多向量表示?
在大多数向量引擎中,每个文档都由单个向量表示——这种方法对于短文本效果很好,但对于较长的文档却常常力不从心。单向量表示会对 token 级别的嵌入进行池化,这显然会导致一些信息的丢失。
多向量表示提供了一种更细粒度的替代方案,其中单个文档使用多个向量表示,通常在 token 或短语级别。这使得特定的查询词和文档相关部分之间能够进行更精确的匹配。匹配在后期交互模型(如 ColBERT)中特别有效,这些模型保留了 token 级别的嵌入并在查询时执行交互,从而产生相关性评分。
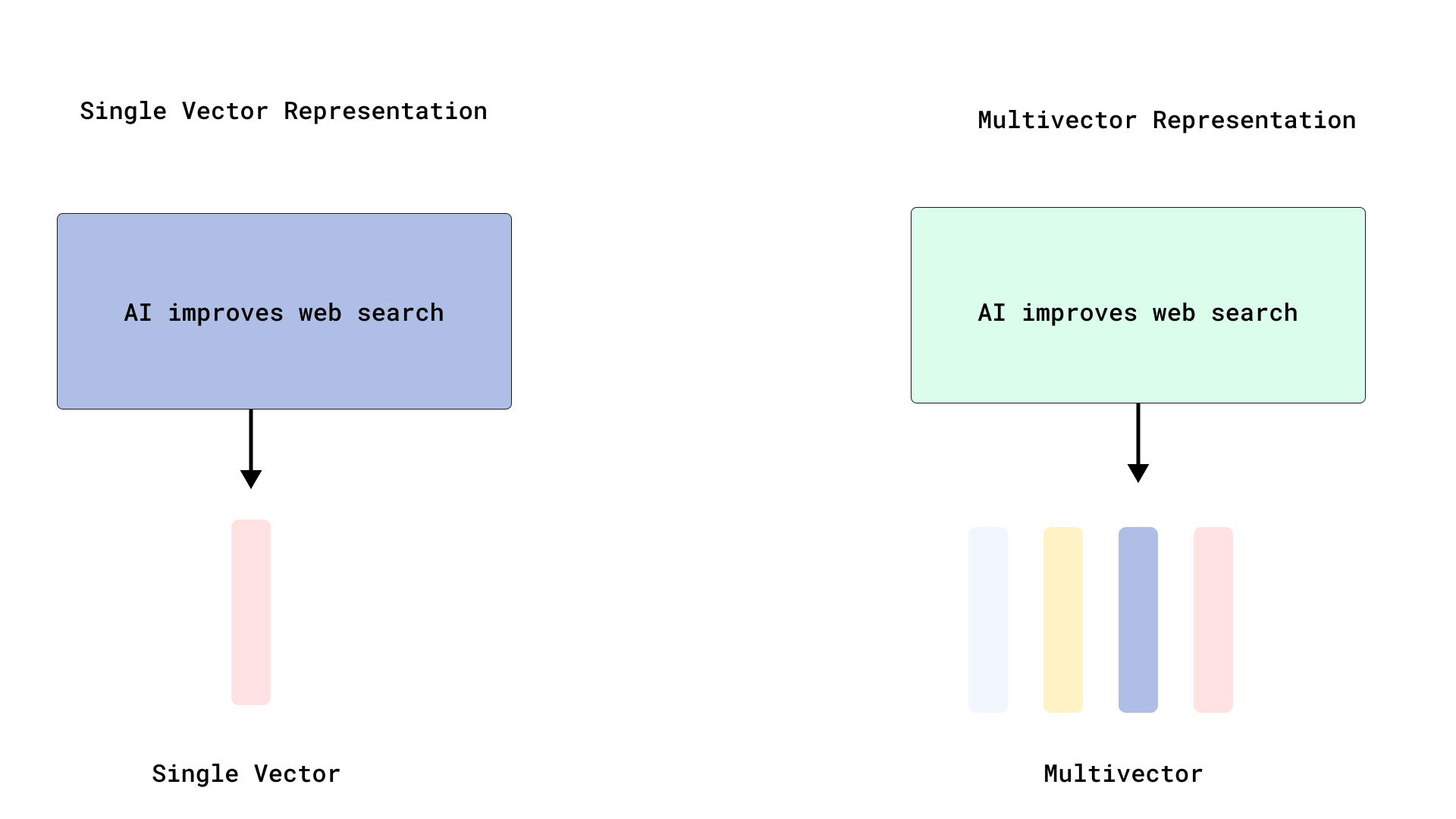
正如您将在教程后面看到的那样,Qdrant 原生支持多向量,因此也支持后期交互模型。
为什么 Token 级别的向量很有用
通过 Token 级别的向量,ColBERT 等模型可以将特定的查询 Token 与文档最相关的部分进行匹配,通过后期交互实现高准确度的检索。
在后期交互中,每个文档都被转换为多个 Token 级别的向量,而不是单个向量。查询也被 Token 化并嵌入到多个向量中。然后,使用相似度函数:MaxSim 来匹配查询向量和文档向量。您可以在此处查看其计算方式。
在传统检索中,查询和文档被转换为单个嵌入,然后计算相似度。这是一种早期交互,因为信息在检索之前就被压缩了。
什么是重排,为什么要使用它?
重排是双重的
- 使用快速模型检索相关文档。
- 使用更准确但更慢的模型(例如 ColBERT)对它们进行重排。
为什么默认情况下索引每个向量是个问题
在多向量表示中(例如 ColBERT 等后期交互模型使用的表示),一个逻辑文档会产生数百个 Token 级别的向量。在 Qdrant 中使用 HNSW 单独索引每个向量可能会导致
- 高 RAM 使用率
- 由于维护 HNSW 图的复杂性,插入时间较慢
然而,由于多向量通常用于重排阶段(在首次通过密集向量检索之后),通常不需要使用 HNSW 索引这些 Token 级别的向量。
相反,它们可以作为多向量字段存储(不带 HNSW 索引),并在查询时用于重排,这可以减少资源开销并提高性能。
有关这方面的更多信息,请查看 Qdrant 在我们的使用 Qdrant 扩展 PDF 检索教程中的详细分解。
使用 Qdrant,您可以完全控制索引的工作方式。您可以通过将 HNSW m 参数设置为 0 来禁用索引。
from qdrant_client import QdrantClient, models
client = QdrantClient("https://:6333")
collection_name = "dense_multivector_demo"
client.create_collection(
collection_name=collection_name,
vectors_config={
"dense": models.VectorParams(
size=384,
distance=models.Distance.COSINE
# Leave HNSW indexing ON for dense
),
"colbert": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=models.HnswConfigDiff(m=0) # Disable HNSW for reranking
)
}
)
通过禁用多向量上的 HNSW,您可以
- 节省计算资源。
- 减少内存使用。
- 加快向量上传速度。
如何使用 FastEmbed 生成多向量
让我们演示如何使用将 ColBERT 封装到简单 API 中的 FastEmbed 有效使用多向量。
安装 FastEmbed 和 Qdrant
pip install qdrant-client[fastembed]>=1.14.2
分步:ColBERT + Qdrant 设置
确保 Qdrant 正在运行并创建客户端
from qdrant_client import QdrantClient, models
# 1. Connect to Qdrant server
client = QdrantClient("https://:6333")
1. 编码文档
接下来,编码您的文档
from fastembed import TextEmbedding, LateInteractionTextEmbedding
# Example documents and query
documents = [
"Artificial intelligence is used in hospitals for cancer diagnosis and treatment.",
"Self-driving cars use AI to detect obstacles and make driving decisions.",
"AI is transforming customer service through chatbots and automation.",
# ...
]
query_text = "How does AI help in medicine?"
dense_documents = [
models.Document(text=doc, model="BAAI/bge-small-en")
for doc in documents
]
dense_query = models.Document(text=query_text, model="BAAI/bge-small-en")
colbert_documents = [
models.Document(text=doc, model="colbert-ir/colbertv2.0")
for doc in documents
]
colbert_query = models.Document(text=query_text, model="colbert-ir/colbertv2.0")
2. 创建 Qdrant 集合
然后创建一个包含两种向量类型的 Qdrant 集合。请注意,我们保留 dense 向量的索引,但关闭将用于重排的 colbert 向量的索引。
collection_name = "dense_multivector_demo"
client.create_collection(
collection_name=collection_name,
vectors_config={
"dense": models.VectorParams(
size=384,
distance=models.Distance.COSINE
# Leave HNSW indexing ON for dense
),
"colbert": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=models.HnswConfigDiff(m=0) # Disable HNSW for reranking
)
}
)
3. 上传文档(密集向量 + 多向量)
现在上传向量,batch_size=8。我们没有很多文档,但始终建议进行批处理。
points = [
models.PointStruct(
id=i,
vector={
"dense": dense_documents[i],
"colbert": colbert_documents[i]
},
payload={"text": documents[i]}
) for i in range(len(documents))
]
client.upload_points(
collection_name="dense_multivector_demo",
points=points,
batch_size=8
)
通过一次调用进行检索 + 重排查询
现在让我们运行一个搜索
results = client.query_points(
collection_name="dense_multivector_demo",
prefetch=models.Prefetch(
query=dense_query,
using="dense",
),
query=colbert_query,
using="colbert",
limit=3,
with_payload=True
)
- 密集向量快速检索出排名靠前的候选。
- Colbert 多向量使用 Token 级别的
MaxSim以细粒度精度对它们进行重排。 - 返回前 3 个结果。
结论
正确使用多向量搜索是向量数据库最强大的功能之一。通过 Qdrant 的此功能,您可以
- 原生存储 Token 级别的嵌入。
- 禁用索引以减少开销。
- 通过一次 API 调用运行快速检索和准确重排。
- 高效扩展后期交互。
结合 FastEmbed 和 Qdrant 可以构建一个生产就绪的 ColBERT 风格重排管道,而不会浪费资源。您可以在本地完成此操作,或使用 Qdrant Cloud。Qdrant 提供了一个易于使用的 API,可帮助您开始构建搜索引擎,因此,如果您准备好深入了解,请在 Qdrant Cloud 免费注册并开始构建。