使用 FastEmbed 和 Qdrant 构建混合搜索服务
| 时间:20 分钟 | 难度:初级 | 输出:GitHub |
|---|
本教程将向您展示如何构建和部署您自己的混合搜索服务,以浏览来自 startups-list.com 的公司描述,并从中挑选与您的查询最相似的公司。该网站包含每家公司的名称、描述、位置和图片。
正如我们已经在博客中写到的,混合搜索没有单一的定义。在本教程中,我们将介绍结合了稠密和稀疏嵌入的情况。前者是指由 BERT 等知名神经网络生成的嵌入,而后者则更接近传统的全文搜索方法。
我们的混合搜索服务将使用 Fastembed 包来生成文本描述的嵌入,并使用 FastAPI 来提供搜索 API 服务。Fastembed 原生集成了 Qdrant 客户端,因此您可以轻松地将数据上传到 Qdrant 并执行搜索查询。
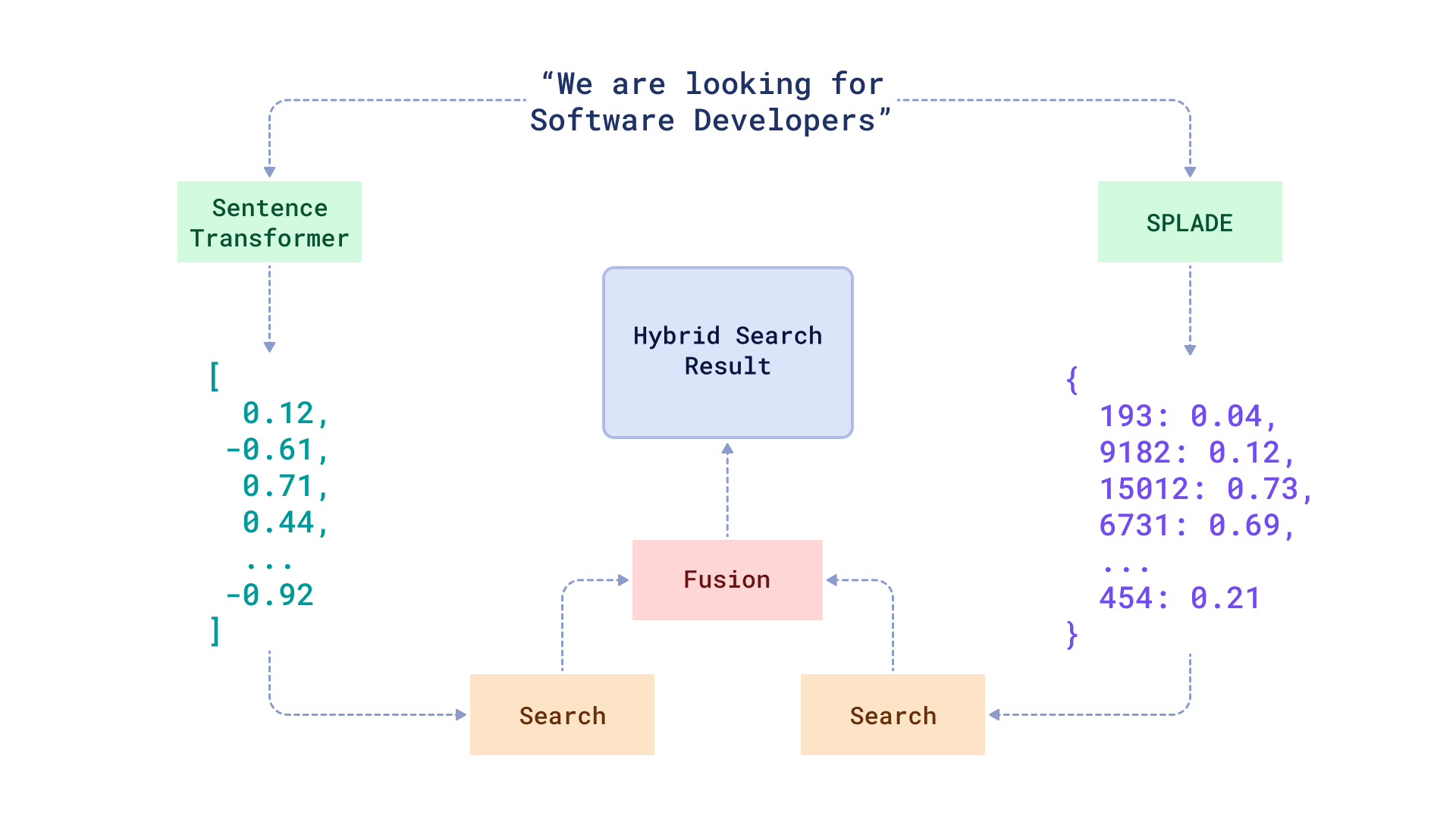
工作流程
要创建一个混合搜索服务,您需要转换原始数据,然后创建一个搜索函数来处理它。首先,您将 1) 下载并使用 BERT ML 模型的修改版本准备一个示例数据集。然后,您将 2) 将数据加载到 Qdrant 中,3) 创建一个混合搜索 API,并 4) 使用 FastAPI 提供服务。
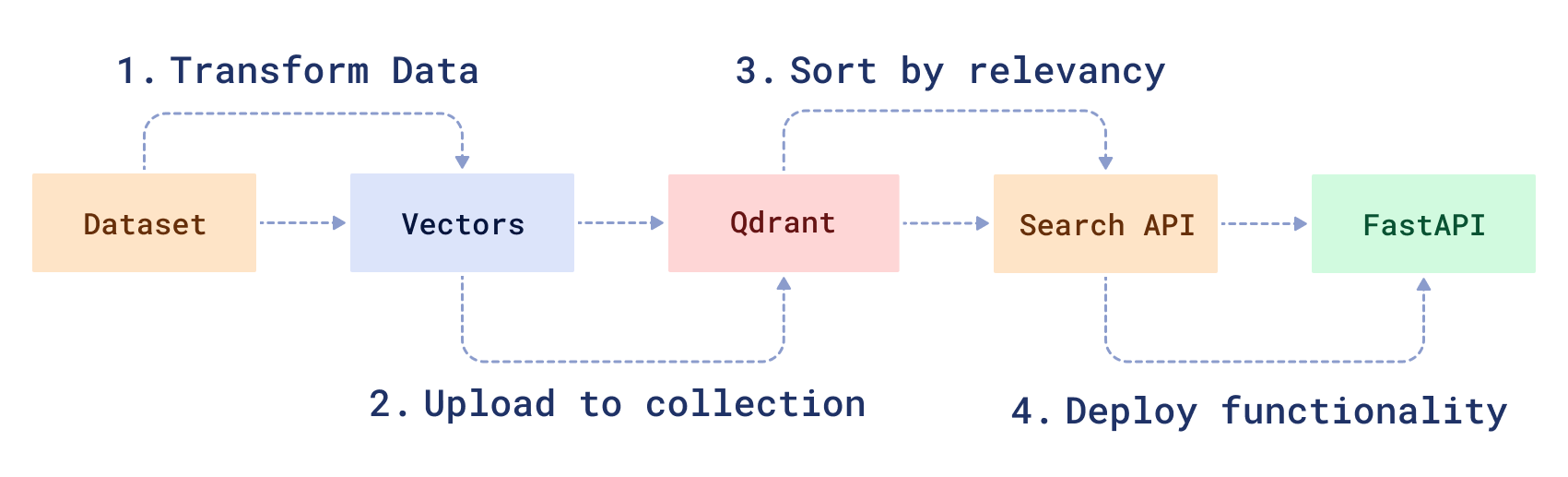
先决条件
完成本教程需要
- Docker - 使用 Qdrant 的最简单方法是运行预构建的 Docker 镜像。
- 来自 startups-list.com 的原始解析数据。
- Python 版本 >=3.9
准备示例数据集
要对初创公司描述进行混合搜索,必须首先将描述数据编码为向量。Fastembed 集成到 Qdrant 客户端中,将编码和上传合并为一个步骤。
它还负责批处理和并行化,因此您无需为此担心。
首先下载数据并安装必要的软件包。
- 首先您需要下载数据集。
wget https://storage.googleapis.com/generall-shared-data/startups_demo.json
在 Docker 中运行 Qdrant
接下来,您需要使用向量引擎来管理所有数据。Qdrant 允许您存储、更新或删除创建的向量。最重要的是,它允许您通过方便的 API 搜索最近的向量。
注意: 开始之前,请创建一个项目目录并在其中设置一个虚拟 Python 环境。
- 从 DockerHub 下载 Qdrant 镜像。
docker pull qdrant/qdrant
- 在 Docker 中启动 Qdrant。
docker run -p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
您应该会看到类似以下的输出
...
[2021-02-05T00:08:51Z INFO actix_server::builder] Starting 12 workers
[2021-02-05T00:08:51Z INFO actix_server::builder] Starting "actix-web-service-0.0.0.0:6333" service on 0.0.0.0:6333
通过访问 https://:6333/ 测试服务。您应该能在浏览器中看到 Qdrant 版本信息。
所有上传到 Qdrant 的数据都保存在 ./qdrant_storage 目录中,即使您重新创建容器,数据也会持久化。
将数据上传到 Qdrant
- 安装官方 Python 客户端以便与 Qdrant 进行最佳交互。
pip install "qdrant-client[fastembed]>=1.14.2"
注意: 本教程需要 fastembed 版本 >=0.6.1。
此时,您应该在 startups_demo.json 文件中拥有初创公司记录,并且 Qdrant 正在本地机器上运行。
现在您需要编写一个脚本,将所有初创公司数据和向量上传到搜索引擎中。
- 为 Qdrant 创建一个客户端对象。
# Import client library
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
- 选择模型来编码数据并准备集合。
在本教程中,我们将使用两个预训练模型分别计算稠密和稀疏向量。模型是:sentence-transformers/all-MiniLM-L6-v2 和 prithivida/Splade_PP_en_v1。一旦做出选择,我们就需要在 Qdrant 中配置一个集合。
dense_vector_name = "dense"
sparse_vector_name = "sparse"
dense_model_name = "sentence-transformers/all-MiniLM-L6-v2"
sparse_model_name = "prithivida/Splade_PP_en_v1"
if not client.collection_exists("startups"):
client.create_collection(
collection_name="startups",
vectors_config={
dense_vector_name: models.VectorParams(
size=client.get_embedding_size(dense_model_name),
distance=models.Distance.COSINE
)
}, # size and distance are model dependent
sparse_vectors_config={sparse_vector_name: models.SparseVectorParams()},
)
Qdrant 要求向量拥有自己的名称和配置。参数 size 和 distance 是必需的,但是,您还可以为向量指定扩展配置,例如 quantization_config 或 hnsw_config。
- 从文件中读取数据。
import json
payload_path = "startups_demo.json"
documents = []
metadata = []
with open(payload_path) as fd:
for line in fd:
obj = json.loads(line)
description = obj["description"]
dense_document = models.Document(text=description, model=dense_model_name)
sparse_document = models.Document(text=description, model=sparse_model_name)
documents.append(
{
dense_vector_name: dense_document,
sparse_vector_name: sparse_document,
}
)
metadata.append(obj)
在这段代码块中,我们从 startups_demo.json 文件中读取数据,并将其分成两个列表:documents 和 metadata。Documents 是包含初创公司描述和用于嵌入数据的模型名称的模型。Metadata 是与每个初创公司相关的载荷(payload),例如名称、位置和图片。我们将使用 documents 将数据编码为向量。
- 编码并上传数据。
client.upload_collection(
collection_name="startups",
vectors=tqdm.tqdm(documents),
payload=metadata,
parallel=4, # Use 4 CPU cores to encode data.
# This will spawn a model per process, which might be memory expensive
# Make sure that your system does not use swap, and reduce the amount
# # of processes if it does.
# Otherwise, it might significantly slow down the process.
# Requires wrapping code into if __name__ == '__main__' block
)
上传已处理数据
从此处下载并解压已处理的数据,或使用以下脚本
wget https://storage.googleapis.com/dataset-startup-search/startup-list-com/startups_hybrid_search_processed_40k.tar.gz
tar -xvf startups_hybrid_search_processed_40k.tar.gz
然后您可以将数据上传到 Qdrant。
import json
import numpy as np
def named_vectors(
vectors: list[float],
sparse_vectors: list[models.SparseVector]
) -> dict:
for vector, sparse_vector in zip(vectors, sparse_vectors):
yield {
dense_vector_name: vector,
sparse_vector_name: models.SparseVector(**sparse_vector),
}
with open("dense_vectors.npy", "rb") as f:
vectors = np.load(f)
with open("sparse_vectors.json", "r") as f:
sparse_vectors = json.load(f)
with open("payload.json", "r") as f:
payload = json.load(f)
client.upload_collection(
"startups",
vectors=named_vectors(vectors, sparse_vectors),
payload=payload
)
upload_collection 方法将编码所有文档并将它们上传到 Qdrant。
parallel 参数启用数据并行,而不是内置的 ONNX 并行。
此外,您可以为每个文档指定 ID,如果您以后想使用它们来更新或删除文档。如果您不指定 ID,它们将自动生成。
您可以通过将 tqdm 进度条传递给 upload_collection 方法来监控编码的进度。
from tqdm import tqdm
client.upload_collection(
collection_name="startups",
vectors=documents,
payload=metadata,
ids=tqdm(range(len(documents))),
)
构建搜索 API
现在所有准备工作都已完成,让我们开始构建一个神经搜索类。
为了处理传入的请求,混合搜索类需要 3 个要素:1) 将查询转换为向量的模型,2) 执行搜索查询的 Qdrant 客户端,3) 用于重新排序稠密和稀疏搜索结果的融合函数。
Qdrant 支持 2 种用于组合结果的融合函数:Reciprocal Rank Fusion(倒数排序融合) 和 Distribution Based Score Fusion(基于分布的分数融合)
- 创建一个名为
hybrid_searcher.py的文件并指定以下内容。
from qdrant_client import QdrantClient, models
class HybridSearcher:
DENSE_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
SPARSE_MODEL = "prithivida/Splade_PP_en_v1"
def __init__(self, collection_name):
self.collection_name = collection_name
self.qdrant_client = QdrantClient()
- 编写搜索函数。
def search(self, text: str):
search_result = self.qdrant_client.query_points(
collection_name=self.collection_name,
query=models.FusionQuery(
fusion=models.Fusion.RRF # we are using reciprocal rank fusion here
),
prefetch=[
models.Prefetch(
query=models.Document(text=text, model=self.DENSE_MODEL)
),
models.Prefetch(
query=models.Document(text=text, model=self.SPARSE_MODEL)
),
],
query_filter=None, # If you don't want any filters for now
limit=5, # 5 the closest results
).points
# `search_result` contains models.QueryResponse structure
# We can access list of scored points with the corresponding similarity scores,
# vectors (if `with_vectors` was set to `True`), and payload via `points` attribute.
# Select and return metadata
metadata = [point.payload for point in search_result]
return metadata
- 添加搜索过滤器。
使用 Qdrant,还可以为搜索添加一些条件。例如,如果您想搜索某个城市的初创公司,搜索查询可以如下所示
...
city_of_interest = "Berlin"
# Define a filter for cities
city_filter = models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(value=city_of_interest)
)
]
)
# NOTE: it is not a hybrid search! It's just a dense query for simplicity
search_result = self.qdrant_client.query_points(
collection_name=self.collection_name,
query=models.Document(text=text, model=self.DENSE_MODEL),
query_filter=city_filter,
limit=5
).points
...
您现在已经创建了一个用于神经搜索查询的类。现在将其打包成一个服务。
使用 FastAPI 部署搜索服务
要构建此服务,您将使用 FastAPI 框架。
- 安装 FastAPI。
要安装它,请使用命令
pip install fastapi uvicorn
- 实现服务。
创建一个名为 service.py 的文件并指定以下内容。
该服务将只有一个 API 端点,如下所示
from fastapi import FastAPI
# The file where HybridSearcher is stored
from hybrid_searcher import HybridSearcher
app = FastAPI()
# Create a neural searcher instance
hybrid_searcher = HybridSearcher(collection_name="startups")
@app.get("/api/search")
def search_startup(q: str):
return {"result": hybrid_searcher.search(text=q)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
- 运行服务。
python service.py
- 在浏览器中打开 https://:8000/docs。
您应该能够看到服务的调试界面。
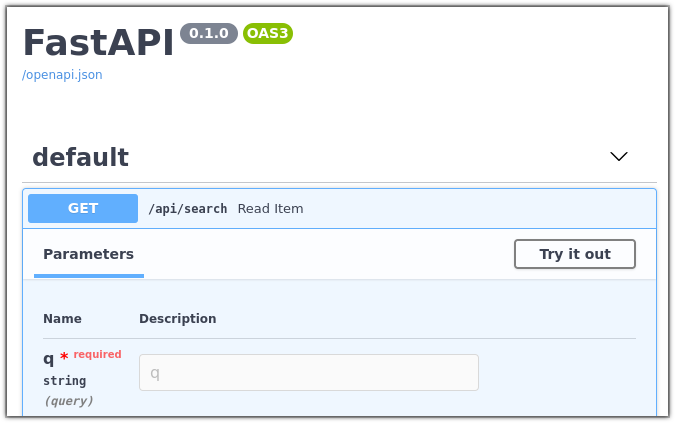
随意试用,对我们语料库中的公司进行查询,并查看结果。
加入我们的 Discord 社区,我们在其中讨论向量搜索和相似度学习,并发布神经网络和神经搜索应用的其他示例。