使用 Sentence Transformers 和 Qdrant 构建神经搜索服务
| 时长:30分钟 | 级别:初学者 | 输出:GitHub |
|---|
本教程将向您展示如何构建和部署您自己的神经搜索服务,以浏览来自 startups-list.com 的公司描述并选择与您的查询最相似的公司。该网站包含每个条目的公司名称、描述、位置和图片。
神经搜索服务使用人工神经网络来提高搜索结果的准确性和相关性。除了提供简单的关键词结果外,该系统还可以按含义检索结果。它可以理解和解释复杂的搜索查询,并提供更具上下文相关性的输出,有效提升用户的搜索体验。
工作流程
要创建神经搜索服务,您需要转换原始数据,然后创建一个搜索函数来处理它。首先,您将 1) 使用 BERT 机器学习模型的修改版本下载和准备样本数据集。然后,您将 2) 将数据加载到 Qdrant 中,3) 创建一个神经搜索 API,并 4) 使用 FastAPI 提供服务。
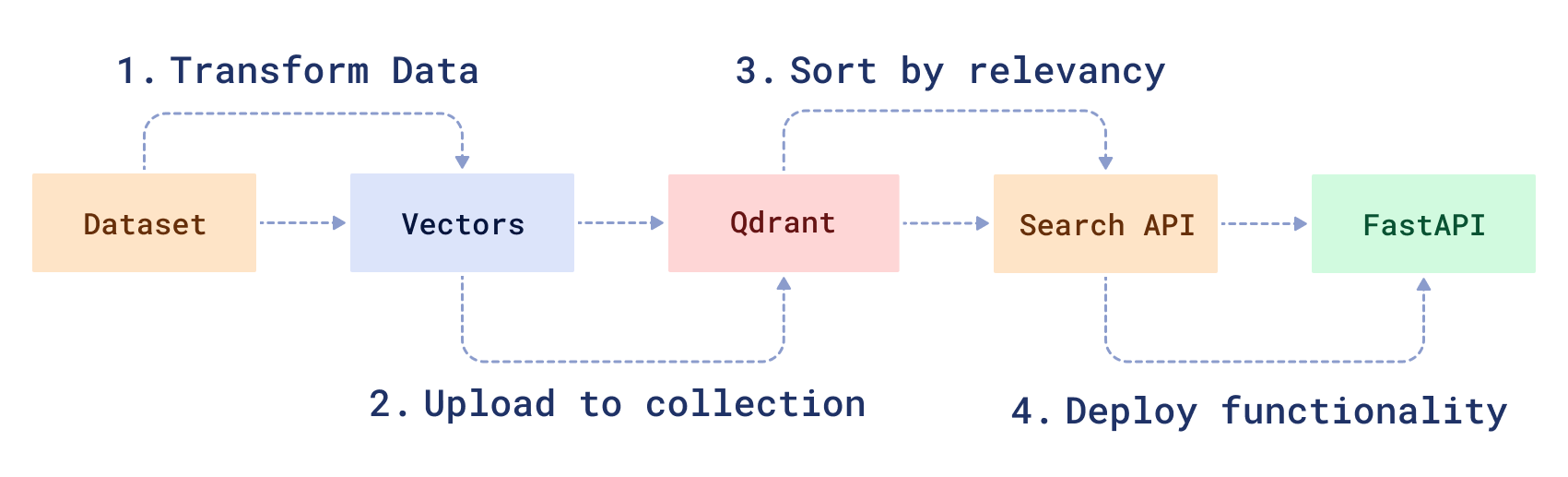
注意:本教程的代码可以在此处找到:| 步骤 1:数据准备过程 | 步骤 2:神经搜索完整代码。|
先决条件
要完成本教程,您需要
- Docker - 使用 Qdrant 最简单的方法是运行预构建的 Docker 镜像。
- 来自 startups-list.com 的原始解析数据。
- Python 版本 >=3.8
准备样本数据集
要对初创公司描述进行神经搜索,您必须首先将描述数据编码为向量。为了处理文本,您可以使用像 BERT 或 sentence transformers 这样的预训练模型。sentence-transformers 库让您可以方便地下载和使用许多预训练模型,例如 DistilBERT、MPNet 等。
- 首先您需要下载数据集。
wget https://storage.googleapis.com/generall-shared-data/startups_demo.json
- 安装 SentenceTransformer 库以及其他相关包。
pip install sentence-transformers numpy pandas tqdm
- 导入所需的模块。
from sentence_transformers import SentenceTransformer
import numpy as np
import json
import pandas as pd
from tqdm.notebook import tqdm
您将使用一个名为 all-MiniLM-L6-v2 的预训练模型。这是一个性能优化的句子嵌入模型,您可以在此处阅读有关它以及其他可用模型的更多信息。
- 下载并创建一个预训练的句子编码器。
model = SentenceTransformer(
"all-MiniLM-L6-v2", device="cuda"
) # or device="cpu" if you don't have a GPU
- 读取原始数据文件。
df = pd.read_json("./startups_demo.json", lines=True)
- 编码所有初创公司描述,为每个描述创建一个嵌入向量。在内部,
encode函数会将输入分割成批次,这将显着加快处理速度。
vectors = model.encode(
[row.alt + ". " + row.description for row in df.itertuples()],
show_progress_bar=True,
)
所有描述现在都已转换为向量。共有 40474 个维度为 384 的向量。模型的输出层具有这个维度。
vectors.shape
# > (40474, 384)
- 将保存的向量下载到名为
startup_vectors.npy的新文件中。
np.save("startup_vectors.npy", vectors, allow_pickle=False)
在 Docker 中运行 Qdrant
接下来,您需要使用向量引擎管理所有数据。Qdrant 允许您存储、更新或删除创建的向量。最重要的是,它允许您通过便捷的 API 搜索最近的向量。
注意:开始之前,请创建一个项目目录并在其中创建虚拟 Python 环境。
- 从 DockerHub 下载 Qdrant 镜像。
docker pull qdrant/qdrant
- 在 Docker 中启动 Qdrant。
docker run -p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
您应该看到如下输出
...
[2021-02-05T00:08:51Z INFO actix_server::builder] Starting 12 workers
[2021-02-05T00:08:51Z INFO actix_server::builder] Starting "actix-web-service-0.0.0.0:6333" service on 0.0.0.0:6333
通过访问 https://:6333/ 测试服务。您应该在浏览器中看到 Qdrant 版本信息。
所有上传到 Qdrant 的数据都保存在 ./qdrant_storage 目录中,即使您重新创建容器也会被持久化。
上传数据到 Qdrant
- 安装官方 Python 客户端以便更好地与 Qdrant 交互。
pip install qdrant-client
此时,您应该在 startups_demo.json 文件中有初创公司记录,在 startup_vectors.npy 中有编码向量,并且 Qdrant 在本地机器上运行。
现在您需要编写一个脚本,将所有初创公司数据和向量上传到搜索引擎中。
- 为 Qdrant 创建一个客户端对象。
# Import client library
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
client = QdrantClient("https://:6333")
- 相关向量需要添加到集合中。为您的初创公司向量创建一个新集合。
if not client.collection_exists("startups"):
client.create_collection(
collection_name="startups",
vectors_config=VectorParams(size=384, distance=Distance.COSINE),
)
- 创建初创公司数据和向量的迭代器。
Qdrant 客户端库定义了一个特殊函数,允许您将数据集加载到服务中。然而,由于数据可能过多而无法适应单台计算机内存,该函数将数据的迭代器作为输入。
fd = open("./startups_demo.json")
# payload is now an iterator over startup data
payload = map(json.loads, fd)
# Load all vectors into memory, numpy array works as iterable for itself.
# Other option would be to use Mmap, if you don't want to load all data into RAM
vectors = np.load("./startup_vectors.npy")
- 上传数据
client.upload_collection(
collection_name="startups",
vectors=vectors,
payload=payload,
ids=None, # Vector ids will be assigned automatically
batch_size=256, # How many vectors will be uploaded in a single request?
)
向量现在已上传到 Qdrant。
构建搜索 API
现在所有准备工作都已完成,让我们开始构建一个神经搜索类。
为了处理传入请求,神经搜索需要两样东西:1) 将查询转换为向量的模型,以及 2) 执行搜索查询的 Qdrant 客户端。
- 创建一个名为
neural_searcher.py的文件,并指定以下内容。
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
class NeuralSearcher:
def __init__(self, collection_name):
self.collection_name = collection_name
# Initialize encoder model
self.model = SentenceTransformer("all-MiniLM-L6-v2", device="cpu")
# initialize Qdrant client
self.qdrant_client = QdrantClient("https://:6333")
- 编写搜索函数。
def search(self, text: str):
# Convert text query into vector
vector = self.model.encode(text).tolist()
# Use `vector` for search for closest vectors in the collection
search_result = self.qdrant_client.query_points(
collection_name=self.collection_name,
query=vector,
query_filter=None, # If you don't want any filters for now
limit=5, # 5 the most closest results is enough
).points
# `search_result` contains found vector ids with similarity scores along with the stored payload
# In this function you are interested in payload only
payloads = [hit.payload for hit in search_result]
return payloads
- 添加搜索过滤器。
使用 Qdrant,还可以为搜索添加一些条件。例如,如果您想搜索某个城市的初创公司,搜索查询可能如下所示
from qdrant_client.models import Filter
...
city_of_interest = "Berlin"
# Define a filter for cities
city_filter = Filter(**{
"must": [{
"key": "city", # Store city information in a field of the same name
"match": { # This condition checks if payload field has the requested value
"value": city_of_interest
}
}]
})
search_result = self.qdrant_client.query_points(
collection_name=self.collection_name,
query=vector,
query_filter=city_filter,
limit=5
).points
...
您现在已经创建了一个用于神经搜索查询的类。现在将其封装成一个服务。
使用 FastAPI 部署搜索
要构建服务,您将使用 FastAPI 框架。
- 安装 FastAPI。
要安装它,请使用命令
pip install fastapi uvicorn
- 实现服务。
创建一个名为 service.py 的文件,并指定以下内容。
该服务将只有一个 API 端点,如下所示
from fastapi import FastAPI
# The file where NeuralSearcher is stored
from neural_searcher import NeuralSearcher
app = FastAPI()
# Create a neural searcher instance
neural_searcher = NeuralSearcher(collection_name="startups")
@app.get("/api/search")
def search_startup(q: str):
return {"result": neural_searcher.search(text=q)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
- 运行服务。
python service.py
- 在浏览器中打开 https://:8000/docs。
您应该能够看到您的服务的调试界面。
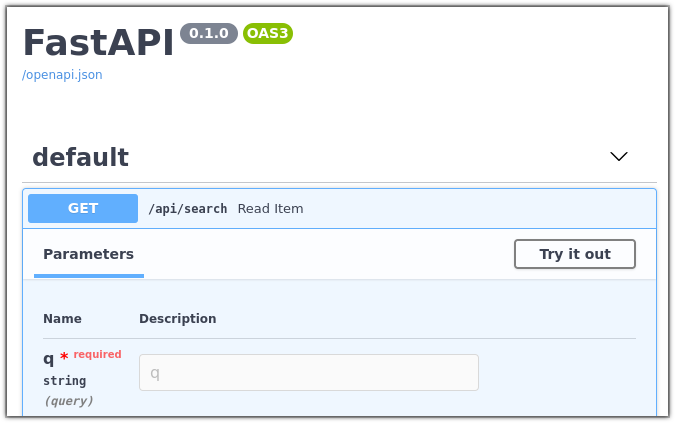
您可以随意试用,对我们语料库中的公司进行查询,并查看结果。
下一步
本教程中的代码已用于开发一个在线实时演示。您可以试用它,直观了解神经搜索在哪些情况下很有用。该演示包含一个开关,用于选择神经搜索和全文搜索。您可以打开和关闭神经搜索,将其结果与常规全文搜索进行比较。
注意:本教程的代码可以在此处找到:| 步骤 1:数据准备过程 | 步骤 2:神经搜索完整代码。|
加入我们的 Discord 社区,我们在其中讨论向量搜索和相似度学习,发布神经网络和神经搜索应用的其他示例。