索引
Qdrant 的一个关键特性是有效地结合了向量索引和传统索引。这一点至关重要,因为对于带过滤器的向量搜索来说,仅有向量索引是不够的。简单来说,向量索引加速向量搜索,而载荷索引加速过滤。
分段中的索引是独立存在的,但索引本身的参数是为整个集合配置的。
并非所有分段都自动拥有索引。它们的必要性由 优化器 设置决定,并且通常取决于存储点的数量。
载荷索引
Qdrant 中的载荷索引类似于传统面向文档数据库中的索引。该索引是为特定字段和类型构建的,用于根据相应的过滤条件快速查找点。
该索引还用于准确估计过滤条件的基数,这有助于 查询规划 选择搜索策略。
创建索引需要额外的计算资源和内存,因此选择要索引的字段至关重要。Qdrant 不会替用户做出选择,而是将选择权交给用户。
要将字段标记为可索引,可以使用以下方法
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": "keyword"
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema="keyword",
)
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: "keyword",
});
use qdrant_client::qdrant::{CreateFieldIndexCollectionBuilder, FieldType};
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Keyword,
)
.wait(true),
)
.await?;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
client.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Keyword,
null,
true,
null,
null);
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index"
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
})
您可以使用点表示法指定嵌套字段进行索引。这与指定 嵌套过滤器 类似。
可用字段类型包括
keyword- 用于 关键字 载荷,影响 匹配(Match) 过滤条件。integer- 用于 整数 载荷,影响 匹配(Match) 和 范围(Range) 过滤条件。float- 用于 浮点数 载荷,影响 范围(Range) 过滤条件。bool- 用于 布尔值 载荷,影响 匹配(Match) 过滤条件(v1.4.0 起可用)。geo- 用于 地理位置 载荷,影响 地理位置边界框(Geo Bounding Box) 和 地理位置半径(Geo Radius) 过滤条件。datetime- 用于 日期时间 载荷,影响 范围(Range) 过滤条件(v1.8.0 起可用)。text- 一种特殊类型的索引,可用于 关键字 / 字符串载荷,影响 全文搜索(Full Text search) 过滤条件。uuid- 一种特殊类型的索引,类似于keyword,但针对 UUID 值 进行了优化。影响 匹配(Match) 过滤条件。(v1.11.0 起可用)
载荷索引可能会占用一些额外的内存,因此建议仅对用于过滤条件的字段使用索引。如果您需要按多个字段进行过滤,但内存限制不允许索引所有字段,建议选择对搜索结果限制最大的字段。通常,载荷值具有的不同值越多,索引的使用效率就越高。
全文索引
v0.10.0 起可用
Qdrant 支持对字符串载荷进行全文搜索。全文索引允许您根据载荷字段中是否存在某个词或短语来过滤点。
全文索引的配置比其他索引稍微复杂一些,因为您可以指定分词参数。分词是将字符串拆分成标记的过程,这些标记随后被索引到倒排索引中。
要创建全文索引,可以使用以下方法
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"min_token_len": 2,
"max_token_len": 20,
"lowercase": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=15,
lowercase=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
min_token_len: 2,
max_token_len: 15,
lowercase: true,
},
});
use qdrant_client::qdrant::{
payload_index_params::IndexParams, CreateFieldIndexCollectionBuilder, FieldType,
PayloadIndexParams, TextIndexParams, TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
)
.field_index_params(PayloadIndexParams {
index_params: Some(IndexParams::TextIndexParams(TextIndexParams {
tokenizer: TokenizerType::Word as i32,
min_token_len: Some(2),
max_token_len: Some(10),
lowercase: Some(true),
})),
}),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setMinTokenLen(2)
.setMaxTokenLen(10)
.setLowercase(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
MinTokenLen = 2,
MaxTokenLen = 10,
Lowercase = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Whitespace,
MinTokenLen: qdrant.PtrOf(uint64(2)),
MaxTokenLen: qdrant.PtrOf(uint64(10)),
Lowercase: qdrant.PtrOf(true),
}),
})
可用分词器包括
word- 将字符串按空格、标点符号和特殊字符分隔成单词。whitespace- 将字符串按空格分隔成单词。prefix- 将字符串按空格、标点符号和特殊字符分隔成单词,然后为每个单词创建前缀索引。例如:hello将被索引为h、he、hel、hell、hello。multilingual- 基于 charabia 包的特殊类型分词器。它允许对多种语言进行正确的分词和词形还原,包括使用非拉丁字母和非空格分隔符的语言。有关支持的语言和归一化选项的完整列表,请参阅 charabia 文档。在默认构建配置中,由于生成二进制文件大小增加,qdrant 不包含对所有语言的支持。中文、日语和韩语默认未启用,但可以通过使用--features multiling-chinese,multiling-japanese,multiling-korean标志从源代码构建 qdrant 来启用。
有关使用全文索引进行查询的示例,请参阅 全文匹配(Full Text match)。
参数化索引
v1.8.0 起可用
我们在 integer 索引中添加了一个参数化变体,允许您微调索引和搜索性能。
常规和参数化 integer 索引都使用以下标志
常规 integer 索引假定 lookup 和 range 都为 true。相比之下,要配置参数化索引,您只会将其中一个过滤器设置为 true
lookup | range | 结果 |
|---|---|---|
true | true | 常规整数索引 |
true | false | 参数化整数索引 |
false | true | 参数化整数索引 |
false | false | 无整数索引 |
参数化索引可以在拥有数百万点的集合中提升性能。我们鼓励您尝试一下。如果它在您的用例中未能提升性能,您可以随时恢复常规 integer 索引。
注意:如果您将 "lookup": true 与范围过滤器一起使用,可能会导致严重的性能问题。
例如,以下代码设置了一个仅支持范围过滤器的参数化整数索引
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "integer",
"lookup": false,
"range": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
lookup=False,
range=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "integer",
lookup: false,
range: true,
},
});
use qdrant_client::qdrant::{
payload_index_params::IndexParams, CreateFieldIndexCollectionBuilder, FieldType,
IntegerIndexParams, PayloadIndexParams,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Integer,
)
.field_index_params(PayloadIndexParams {
index_params: Some(IndexParams::IntegerIndexParams(IntegerIndexParams {
lookup: false,
range: true,
})),
}),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.IntegerIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Integer,
PayloadIndexParams.newBuilder()
.setIntegerIndexParams(
IntegerIndexParams.newBuilder().setLookup(false).setRange(true).build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Integer,
indexParams: new PayloadIndexParams
{
IntegerIndexParams = new()
{
Lookup = false,
Range = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeInteger.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsInt(
&qdrant.IntegerIndexParams{
Lookup: false,
Range: true,
}),
})
磁盘载荷索引
v1.11.0 起可用
默认情况下,所有与载荷相关的结构都存储在内存中。这样,向量索引可以在搜索期间快速访问载荷值。由于在这种情况下延迟至关重要,建议将热载荷索引保留在内存中。
然而,在某些情况下,载荷索引可能过大或很少使用。在这些情况下,可以将载荷索引存储在磁盘上。
要配置磁盘载荷索引,可以使用以下索引参数
PUT /collections/{collection_name}/index
{
"field_name": "payload_field_name",
"field_schema": {
"type": "keyword",
"on_disk": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="payload_field_name",
field_schema=models.KeywordIndexParams(
type=models.KeywordIndexType.KEYWORD,
on_disk=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "payload_field_name",
field_schema: {
type: "keyword",
on_disk: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"payload_field_name",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.on_disk(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"payload_field_name",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setOnDisk(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "payload_field_name",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
OnDisk = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
OnDisk: qdrant.PtrOf(true),
}),
})
磁盘上的载荷索引支持以下类型
keywordintegerfloatdatetimeuuidtextgeo
此列表将在未来版本中扩展。
租户索引
v1.11.0 起可用
许多向量搜索用例需要多租户。在多租户场景中,集合预期包含多个数据子集,每个子集属于不同的租户。
Qdrant 通过启用 特殊配置 的向量索引来支持高效的多租户搜索,该配置禁用全局搜索,并仅为每个租户构建子索引。
然而,了解集合包含多个租户可以解锁更多优化机会。为了进一步优化 Qdrant 中的存储,您可以为载荷字段启用租户索引。
此选项将告知 Qdrant 哪些字段用于租户标识,并允许 Qdrant 构建存储结构以加快租户特定数据的搜索速度。这种优化的一个例子是将租户特定数据在磁盘上更靠近地存放,从而减少搜索期间的磁盘读取次数。
要为字段启用租户索引,可以使用以下索引参数
PUT /collections/{collection_name}/index
{
"field_name": "payload_field_name",
"field_schema": {
"type": "keyword",
"is_tenant": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="payload_field_name",
field_schema=models.KeywordIndexParams(
type=models.KeywordIndexType.KEYWORD,
is_tenant=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "payload_field_name",
field_schema: {
type: "keyword",
is_tenant: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"payload_field_name",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.is_tenant(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"payload_field_name",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setIsTenant(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "payload_field_name",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
IsTenant = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
IsTenant: qdrant.PtrOf(true),
}),
})
租户优化支持以下数据类型
keyworduuid
主索引
v1.11.0 起可用
与租户索引类似,主索引用于优化存储以加快搜索速度,前提是搜索请求主要由主字段过滤。
主索引的一个很好的用例示例是与时间相关的数据,其中每个点都与一个时间戳相关联。在这种情况下,可以使用主索引来优化存储,以加快基于时间的过滤器的搜索速度。
PUT /collections/{collection_name}/index
{
"field_name": "timestamp",
"field_schema": {
"type": "integer",
"is_principal": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="timestamp",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
is_principal=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "timestamp",
field_schema: {
type: "integer",
is_principal: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
IntegerIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"timestamp",
FieldType::Integer,
)
.field_index_params(
IntegerIndexParamsBuilder::default()
.is_principal(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.IntegerIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"timestamp",
PayloadSchemaType.Integer,
PayloadIndexParams.newBuilder()
.setIntegerIndexParams(
KeywordIndexParams.newBuilder()
.setIsPrincipa(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "timestamp",
schemaType: PayloadSchemaType.Integer,
indexParams: new PayloadIndexParams
{
IntegerIndexParams = new IntegerIndexParams
{
IsPrincipal = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeInteger.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsInt(
&qdrant.IntegerIndexParams{
IsPrincipal: qdrant.PtrOf(true),
}),
})
主优化支持以下类型
integerfloatdatetime
向量索引
向量索引是一种通过特定数学模型在向量上构建的数据结构。通过向量索引,我们可以高效地查询与目标向量相似的多个向量。
Qdrant 目前仅使用 HNSW 作为密集向量索引。
HNSW(分层可导航小世界图)是一种基于图的索引算法。它根据某些规则为图像构建多层导航结构。在该结构中,上层更加稀疏,节点之间的距离更远;下层更加密集,节点之间的距离更近。搜索从最上层开始,在该层找到离目标最近的节点,然后进入下一层开始新的搜索。经过多次迭代,可以快速接近目标位置。
为了提高性能,HNSW 将图每层节点的最高度数限制为 m。此外,您可以使用 ef_construct(构建索引时)或 ef(搜索目标时)来指定搜索范围。
相应的参数可以在配置文件中配置
storage:
# Default parameters of HNSW Index. Could be overridden for each collection or named vector individually
hnsw_index:
# Number of edges per node in the index graph.
# Larger the value - more accurate the search, more space required.
m: 16
# Number of neighbours to consider during the index building.
# Larger the value - more accurate the search, more time required to build index.
ef_construct: 100
# Minimal size (in KiloBytes) of vectors for additional payload-based indexing.
# If payload chunk is smaller than `full_scan_threshold_kb` additional indexing won't be used -
# in this case full-scan search should be preferred by query planner and additional indexing is not required.
# Note: 1Kb = 1 vector of size 256
full_scan_threshold: 10000
并在创建 集合 的过程中配置。 ef 参数在 搜索 期间配置,默认等于 ef_construct。
选择 HNSW 有几个原因。首先,HNSW 与允许 Qdrant 在搜索期间使用过滤器的修改兼容性良好。其次,根据 公开基准测试,它是最准确、最快的算法之一。
v1.1.1 起可用
通过设置 hnsw_config,也可以在集合和命名向量级别配置 HNSW 参数,以微调搜索性能。
稀疏向量索引
v1.7.0 起可用
Qdrant 中的稀疏向量使用一种特殊的数据结构进行索引,该结构针对包含大量零值的向量进行了优化。在某些方面,这种索引方法类似于文本搜索引擎中使用的倒排索引。
- Qdrant 中的稀疏向量索引是精确的,这意味着它不使用任何近似算法。
- 添加到集合中的所有稀疏向量都会立即在稀疏索引的可变版本中进行索引。
使用 Qdrant,您可以受益于更紧凑高效的不可变稀疏索引,该索引与密集向量索引在相同的优化过程中构建。
这种方法对于存储密集向量和稀疏向量的集合特别有用。
要配置稀疏向量索引,请使用以下参数创建一个集合
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"index": {
"on_disk": false
}
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
index=models.SparseIndexParams(on_disk=False),
)
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"splade-model-name": {
index: {
on_disk: false
}
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, SparseIndexConfigBuilder, SparseVectorParamsBuilder,
SparseVectorsConfigBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"splade-model-name",
SparseVectorParamsBuilder::default()
.index(SparseIndexConfigBuilder::default().on_disk(true)),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections;
QdrantClient client = new QdrantClient(
QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.createCollectionAsync(
Collections.CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
Collections.SparseVectorConfig.newBuilder().putMap(
"splade-model-name",
Collections.SparseVectorParams.newBuilder()
.setIndex(
Collections.SparseIndexConfig
.newBuilder()
.setOnDisk(false)
.build()
).build()
).build()
).build()
).get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("splade-model-name", new SparseVectorParams{
Index = new SparseIndexConfig {
OnDisk = false,
}
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"splade-model-name": {
Index: &qdrant.SparseIndexConfig{
OnDisk: qdrant.PtrOf(false),
}},
}),
})
以下参数可能影响性能
on_disk: true- 索引存储在磁盘上,可以节省内存。这可能会降低搜索性能。on_disk: false- 索引仍然持久化到磁盘,但也会加载到内存中以加快搜索速度。
与密集向量索引不同,稀疏向量索引不需要预先定义向量大小。它会自动适应添加到集合中的向量大小。
注意:稀疏向量索引仅支持点积相似度搜索。它不支持其他距离指标。
IDF 修饰符
v1.10.0 起可用
对于许多搜索算法来说,考虑一个项目在集合中出现的频率非常重要。直观地说,一个项目在集合中出现的频率越低,它在搜索中的重要性就越大。
这也被称为逆文档频率(IDF)。它用于文本搜索引擎中,根据单词在集合中的稀有程度对搜索结果进行排序。
IDF 取决于当前存储的文档,因此在流式推理模式下无法在稀疏向量中预先计算。为了在稀疏向量索引中支持 IDF,Qdrant 提供了一个选项,可以自动使用 IDF 统计数据修改稀疏向量查询。
唯一的要求是在集合配置中启用 IDF 修饰符
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"modifier": "idf"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
modifier=models.Modifier.IDF,
),
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"text": {
modifier: "idf"
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Modifier, SparseVectorParamsBuilder, SparseVectorsConfigBuilder,
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"text",
SparseVectorParamsBuilder::default().modifier(Modifier::Idf),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Modifier;
import io.qdrant.client.grpc.Collections.SparseVectorConfig;
import io.qdrant.client.grpc.Collections.SparseVectorParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
SparseVectorConfig.newBuilder()
.putMap("text", SparseVectorParams.newBuilder().setModifier(Modifier.Idf).build()))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("text", new SparseVectorParams {
Modifier = Modifier.Idf,
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"text": {
Modifier: qdrant.Modifier_Idf.Enum(),
},
}),
})
Qdrant 使用以下公式计算 IDF 修饰符
$$ \text{IDF}(q_i) = \ln \left(\frac{N - n(q_i) + 0.5}{n(q_i) + 0.5}+1\right) $$
其中
N是集合中的文档总数。n是对于给定向量元素包含非零值的文档数量。
可过滤索引
单独的载荷索引和向量索引不能完全解决使用过滤器进行搜索的问题。
对于弱过滤器的情况,您可以直接使用 HNSW 索引。对于严格过滤器的情况,可以使用载荷索引并进行完全重新评分。然而,对于居中的情况,这种方法效果不佳。
一方面,我们不能对过多的向量进行完全扫描。另一方面,当使用过于严格的过滤器时,HNSW 图开始崩溃。
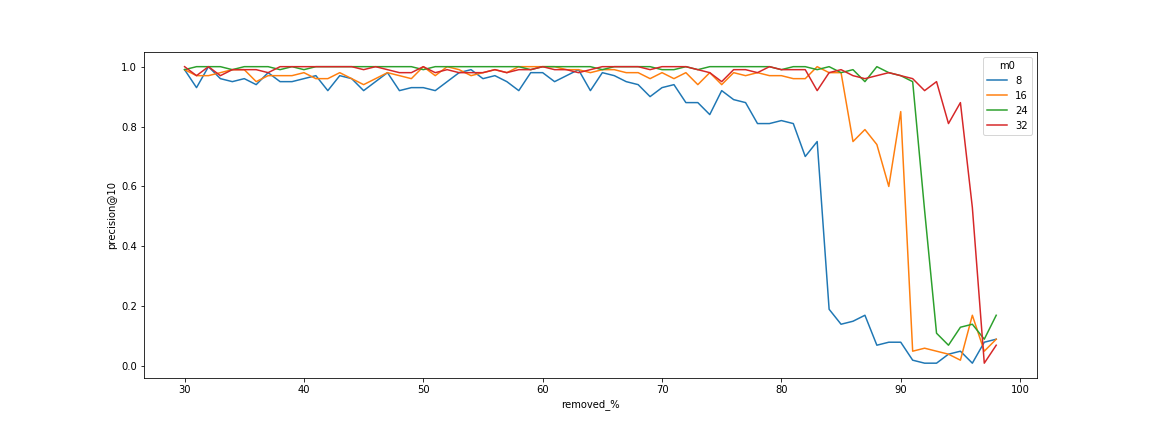

您可以在我们的 博客文章 中找到关于这种情况发生原因的更多信息。Qdrant 通过基于存储的载荷值扩展 HNSW 图的额外边来解决这个问题。
额外的边允许您使用 HNSW 索引高效搜索附近的向量,并在图搜索过程中应用过滤器。
这种方法最大限度地减少了条件检查的开销,因为您只需要计算搜索中涉及的一小部分点的条件。