索引
Qdrant 的一个关键特性是向量索引和传统索引的有效结合。拥有此功能至关重要,因为对于带有过滤器的向量搜索而言,仅有向量索引是不够的。简单来说,向量索引可以加速向量搜索,而 payload 索引可以加速过滤。
段中的索引独立存在,但索引本身的参数是为整个集合配置的。
并非所有段都自动拥有索引。它们的必要性由优化器设置决定,通常取决于存储点的数量。
Payload 索引
Qdrant 中的 payload 索引类似于传统文档型数据库中的索引。此索引是为特定字段和类型构建的,用于通过相应的过滤条件快速请求点。
该索引还用于准确估计过滤器基数,这有助于查询规划选择搜索策略。
创建索引需要额外的计算资源和内存,因此选择要索引的字段至关重要。Qdrant 不会做出此选择,而是将其授予用户。
要将字段标记为可索引,您可以使用以下内容
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": "keyword"
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema="keyword",
)
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: "keyword",
});
use qdrant_client::qdrant::{CreateFieldIndexCollectionBuilder, FieldType};
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Keyword,
)
.wait(true),
)
.await?;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
client.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Keyword,
null,
true,
null,
null);
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index"
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
})
您可以使用点表示法指定要索引的嵌套字段。类似于指定嵌套过滤器。
可用字段类型为
keyword- 用于关键字 payload,影响匹配过滤条件。integer- 用于整数 payload,影响匹配和范围过滤条件。float- 用于浮点数 payload,影响范围过滤条件。bool- 用于布尔值 payload,影响匹配过滤条件(自 v1.4.0 起可用)。geo- 用于地理 payload,影响地理边界框和地理半径过滤条件。datetime- 用于日期时间 payload,影响范围过滤条件(自 v1.8.0 起可用)。text- 一种特殊类型的索引,可用于关键字/字符串 payload,影响全文搜索过滤条件。阅读有关文本索引配置的更多信息uuid- 一种特殊类型的索引,类似于keyword,但针对UUID 值进行了优化。影响匹配过滤条件。(自 v1.11.0 起可用)
Payload 索引可能会占用一些额外的内存,因此建议仅对用于过滤条件的字段使用索引。如果您需要按许多字段进行过滤,并且内存限制不允许全部索引,建议选择限制搜索结果最多的字段。通常,payload 值具有的不同值越多,索引的使用效率越高。
参数化索引
自 v1.8.0 起可用
我们为integer索引添加了一个参数化变体,它允许您微调索引和搜索性能。
常规和参数化integer索引都使用以下标志
常规的integer索引假定lookup和range都为true。相反,要配置参数化索引,您只需将其中一个过滤器设置为true
查找 | 范围 | 结果 |
|---|---|---|
真 | 真 | 常规整数索引 |
真 | 假 | 参数化整数索引 |
假 | 真 | 参数化整数索引 |
假 | 假 | 无整数索引 |
参数化索引可以提高具有数百万个点的集合的性能。我们鼓励您尝试一下。如果它在您的用例中没有提高性能,您可以随时恢复常规的integer索引。
注意:如果您将"lookup": true与范围过滤器一起设置,可能会导致严重的性能问题。
例如,以下代码设置了一个参数化整数索引,该索引仅支持范围过滤器
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "integer",
"lookup": false,
"range": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
lookup=False,
range=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "integer",
lookup: false,
range: true,
},
});
use qdrant_client::qdrant::{
payload_index_params::IndexParams, CreateFieldIndexCollectionBuilder, FieldType,
IntegerIndexParams, PayloadIndexParams,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Integer,
)
.field_index_params(PayloadIndexParams {
index_params: Some(IndexParams::IntegerIndexParams(IntegerIndexParams {
lookup: false,
range: true,
})),
}),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.IntegerIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Integer,
PayloadIndexParams.newBuilder()
.setIntegerIndexParams(
IntegerIndexParams.newBuilder().setLookup(false).setRange(true).build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Integer,
indexParams: new PayloadIndexParams
{
IntegerIndexParams = new()
{
Lookup = false,
Range = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeInteger.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsInt(
&qdrant.IntegerIndexParams{
Lookup: false,
Range: true,
}),
})
磁盘上的 Payload 索引
自 v1.11.0 起可用
默认情况下,所有与 payload 相关的结构都存储在内存中。通过这种方式,向量索引可以在搜索期间快速访问 payload 值。由于在这种情况下延迟至关重要,因此建议将热 payload 索引保留在内存中。
但是,在某些情况下,payload 索引过大或很少使用。在这些情况下,可以将 payload 索引存储在磁盘上。
要配置磁盘上的 payload 索引,您可以使用以下索引参数
PUT /collections/{collection_name}/index
{
"field_name": "payload_field_name",
"field_schema": {
"type": "keyword",
"on_disk": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="payload_field_name",
field_schema=models.KeywordIndexParams(
type=models.KeywordIndexType.KEYWORD,
on_disk=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "payload_field_name",
field_schema: {
type: "keyword",
on_disk: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"payload_field_name",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.on_disk(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"payload_field_name",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setOnDisk(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "payload_field_name",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
OnDisk = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
OnDisk: qdrant.PtrOf(true),
}),
})
以下类型支持磁盘上的 payload 索引
关键字整数浮点数日期时间uuid文本地理
该列表将在未来版本中扩展。
租户索引
自 v1.11.0 起可用
许多向量搜索用例需要多租户。在多租户场景中,集合预计包含多个数据子集,其中每个子集属于不同的租户。
Qdrant 通过启用特殊配置向量索引来支持高效的多租户搜索,该索引禁用全局搜索并仅为每个租户构建子索引。
然而,知道集合包含多个租户可以解锁更多优化机会。为了进一步优化 Qdrant 中的存储,您可以为 payload 字段启用租户索引。
此选项将告诉 Qdrant 哪些字段用于租户识别,并允许 Qdrant 构造存储以加快租户特定数据的搜索。这种优化的一个示例是在磁盘上将租户特定数据定位得更近,这将减少搜索期间的磁盘读取次数。
要为字段启用租户索引,您可以使用以下索引参数
PUT /collections/{collection_name}/index
{
"field_name": "payload_field_name",
"field_schema": {
"type": "keyword",
"is_tenant": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="payload_field_name",
field_schema=models.KeywordIndexParams(
type=models.KeywordIndexType.KEYWORD,
is_tenant=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "payload_field_name",
field_schema: {
type: "keyword",
is_tenant: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"payload_field_name",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.is_tenant(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"payload_field_name",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setIsTenant(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "payload_field_name",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
IsTenant = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
IsTenant: qdrant.PtrOf(true),
}),
})
以下数据类型支持租户优化
关键字uuid
主索引
自 v1.11.0 起可用
与租户索引类似,主索引用于优化存储以加快搜索,假设搜索请求主要由主字段过滤。
主索引用例的一个很好的例子是时间相关数据,其中每个点都与时间戳相关联。在这种情况下,主索引可用于优化存储以加快基于时间的过滤器的搜索。
PUT /collections/{collection_name}/index
{
"field_name": "timestamp",
"field_schema": {
"type": "integer",
"is_principal": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="timestamp",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
is_principal=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "timestamp",
field_schema: {
type: "integer",
is_principal: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
IntegerIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"timestamp",
FieldType::Integer,
)
.field_index_params(
IntegerIndexParamsBuilder::default()
.is_principal(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.IntegerIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"timestamp",
PayloadSchemaType.Integer,
PayloadIndexParams.newBuilder()
.setIntegerIndexParams(
KeywordIndexParams.newBuilder()
.setIsPrincipa(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "timestamp",
schemaType: PayloadSchemaType.Integer,
indexParams: new PayloadIndexParams
{
IntegerIndexParams = new IntegerIndexParams
{
IsPrincipal = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeInteger.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsInt(
&qdrant.IntegerIndexParams{
IsPrincipal: qdrant.PtrOf(true),
}),
})
以下类型支持主优化
整数浮点数日期时间
全文索引
Qdrant 支持字符串 payload 的全文搜索。全文索引允许您根据 payload 字段中是否存在单词或短语来过滤点。
全文索引配置比其他索引稍微复杂一些,因为您可以指定分词参数。分词是将字符串拆分为标记的过程,然后将这些标记索引到倒排索引中。
有关使用全文索引查询的示例,请参阅全文匹配。
要创建全文索引,您可以使用以下内容
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"min_token_len": 2,
"max_token_len": 10,
"lowercase": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=10,
lowercase=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
min_token_len: 2,
max_token_len: 10,
lowercase: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.min_token_len(2)
.max_token_len(10)
.lowercase(true);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setMinTokenLen(2)
.setMaxTokenLen(10)
.setLowercase(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
MinTokenLen = 2,
MaxTokenLen = 10,
Lowercase = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Whitespace,
MinTokenLen: qdrant.PtrOf(uint64(2)),
MaxTokenLen: qdrant.PtrOf(uint64(10)),
Lowercase: qdrant.PtrOf(true),
}),
})
分词器
分词器是用于将文本拆分为称为标记的较小单元的算法,然后将这些标记索引并在全文索引中搜索。在 Qdrant 的上下文中,分词器决定如何分解字符串 payload 以进行高效搜索和过滤。分词器的选择会影响查询如何匹配索引文本,支持不同的语言、单词边界和搜索行为,例如前缀或短语匹配。
可用的分词器有
word- 将字符串拆分为单词,由空格、标点符号和特殊字符分隔。whitespace- 将字符串拆分为单词,由空格分隔。prefix- 将字符串拆分为单词,由空格、标点符号和特殊字符分隔,然后为每个单词创建一个前缀索引。例如:hello将被索引为h、he、hel、hell、hello。multilingual- 一种特殊类型的分词器,基于charabia和vaporetto等多个软件包,可为多种语言提供快速准确的分词。它支持多种语言的正确分词和词形还原,包括那些使用非拉丁字母和非空格分隔符的语言。有关支持的语言和标准化选项的完整列表,请参阅charabia 文档。注意:对于日语,Qdrant 依赖于vaporetto项目,与charabia相比,它开销更小,同时保持相似的性能。
小写化
默认情况下,Qdrant 中的全文搜索不区分大小写。例如,用户可以搜索小写术语tv并找到包含大写单词TV的文本字段。通过将索引中的单词和查询术语都转换为小写来实现不区分大小写。
默认启用小写化。要使用区分大小写的全文搜索,请将全文索引配置为lowercase设置为false。
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"lowercase": false
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
lowercase=False,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
lowercase: false,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.lowercase(false);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setLowercase(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Lowercase = true,
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Lowercase: qdrant.PtrOf(true),
}),
})
ASCII 折叠
自 v1.16.0 起可用
启用后,ASCII 折叠将 Unicode 字符转换为其相应的 ASCII 等效项,例如,通过删除变音符号。例如,字符ã更改为a,ç变为c,é转换为e。
由于 ASCII 折叠应用于索引中的单词和查询术语,因此它增加了召回率。例如,用户可以搜索cafe并找到包含单词café的文本字段。
默认情况下不启用 ASCII 折叠。要启用它,请将全文索引配置为ascii_folding设置为true。
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"ascii_folding": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
ascii_folding=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
ascii_folding: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.ascii_folding(true);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setLowercase(true)
.setAsciiFolding(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Lowercase = true,
AsciiFolding = true,
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Lowercase: qdrant.PtrOf(true),
AsciiFolding: qdrant.PtrOf(true),
}),
})
词干提取器
词干提取器是一种在文本处理中使用的算法,用于将单词还原为它们的词根或基本形式,称为“词干”。例如,单词“running”、“runner”和“runs”都可以还原为词干“run”。在 Qdrant 中配置全文索引时,您可以指定用于特定语言的词干提取器。这使得索引能够识别和匹配单词的不同变位或派生。
Qdrant 提供了Snowball 词干提取器的实现,这是一种广泛使用且性能优异的变体,适用于一些最流行的语言。有关支持的语言列表,请访问rust-stemmers 存储库。
以下是使用 Snowball 词干提取器进行全文索引配置的示例
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"stemmer": {
"type": "snowball",
"language": "english"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
stemmer=models.SnowballParams(
type=models.Snowball.SNOWBALL,
language=models.SnowballLanguage.ENGLISH
)
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
stemmer: {
type: "snowball",
language: "english"
}
}
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.snowball_stemmer("english".to_string());
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"{field_name}",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.SnowballParams;
import io.qdrant.client.grpc.Collections.StemmingAlgorithm;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setStemmer(
StemmingAlgorithm.newBuilder()
.setSnowball(
SnowballParams.newBuilder().setLanguage("english").build())
.build())
.build())
.build(),
true,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Stemmer = new StemmingAlgorithm
{
Snowball = new SnowballParams
{
Language = "english"
}
}
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Stemmer: qdrant.NewStemmingAlgorithmSnowball(&qdrant.SnowballParams{
Language: "english",
}),
}),
})
停用词
停用词是常用词(例如“the”、“is”、“at”、“which”和“on”),在文本处理过程中通常会被过滤掉,因为它们对于搜索和检索任务几乎没有有意义的信息。
在 Qdrant 中,您可以指定一个停用词列表,以便在全文索引和搜索期间忽略这些词。这有助于简化搜索查询并提高相关性。
您可以根据预定义语言配置停用词,以及使用自定义单词扩展现有停用词列表。
以下是使用自定义停用词配置全文索引的示例
// Simple
PUT collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"stopwords": "english"
}
}
// Explicit
PUT collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"stopwords": {
"languages": [
"english",
"spanish"
],
"custom": [
"example"
]
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
# Simple
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
stopwords=models.Language.ENGLISH,
),
)
# Explicit
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
stopwords=models.StopwordsSet(
languages=[
models.Language.ENGLISH,
models.Language.SPANISH,
],
custom=[
"example"
]
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
// Simple
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
stopwords: "english"
},
});
// Explicit
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
stopwords: {
languages: [
"english",
"spanish"
],
custom: [
"example"
]
}
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
StopwordsSet,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
// Simple
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.stopwords_language("english".to_string());
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
// Explicit
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.stopwords(StopwordsSet {
languages: vec![
"english".to_string(),
"spanish".to_string(),
],
custom: vec!["example".to_string()],
});
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"{field_name}",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.StopwordsSet;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setStopwords(
StopwordsSet.newBuilder()
.addAllLanguages(List.of("english", "spanish"))
.addAllCustom(List.of("example"))
.build())
.build())
.build(),
true,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Stopwords = new StopwordsSet
{
Languages = { "english", "spanish" },
Custom = { "example" }
}
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Stopwords: &qdrant.StopwordsSet{
Languages: []string{"english", "spanish"},
Custom: []string{"example"},
},
}),
})
短语搜索
Qdrant 中的短语搜索允许您查找在文本 payload 字段中按相同顺序一起出现的特定单词序列的文档或点。当您想要匹配精确短语而不是散布在文本中的单个单词时,这非常有用。
当使用启用短语搜索的全文索引时,您可以通过在过滤器查询中将所需短语括在双引号中来执行短语搜索。例如,搜索"machine learning"将只返回单词“machine”和“learning”作为短语一起出现的结果,而不是文本中的任何位置。
为了高效的短语搜索,Qdrant 需要构建额外的数据结构,因此需要在创建全文索引时进行配置
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"lowercase": true,
"phrase_matching": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
lowercase=True,
phrase_matching=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
lowercase: true,
phrase_matching: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.phrase_matching(true)
.lowercase(true);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setLowercase(true)
.setPhraseMatching(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Lowercase = true,
PhraseMatching = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Whitespace,
Lowercase: qdrant.PtrOf(true),
PhraseMatching: qdrant.PtrOf(true),
}),
})
有关使用全文索引查询短语的示例,请参阅短语匹配。
向量索引
向量索引是通过特定数学模型在向量上构建的数据结构。通过向量索引,我们可以高效地查询几个与目标向量相似的向量。
Qdrant 目前仅使用 HNSW 作为稠密向量索引。
HNSW(分层可导航小世界图)是一种基于图的索引算法。它根据一定的规则为图像构建多层导航结构。在此结构中,上层更稀疏,节点之间的距离更远。下层更密集,节点之间的距离更近。搜索从最上层开始,在该层中找到最接近目标的节点,然后进入下一层开始另一次搜索。经过多次迭代,它可以快速接近目标位置。
为了提高性能,HNSW 将图的每一层上节点的度数限制为m。此外,您可以使用ef_construct(构建索引时)或ef(搜索目标时)指定搜索范围。
相应的参数可以在配置文件中配置
storage:
# Default parameters of HNSW Index. Could be overridden for each collection or named vector individually
hnsw_index:
# Number of edges per node in the index graph.
# Larger the value - more accurate the search, more space required.
m: 16
# Number of neighbours to consider during the index building.
# Larger the value - more accurate the search, more time required to build index.
ef_construct: 100
# Minimal size threshold (in KiloBytes) below which full-scan is preferred over HNSW search.
# This measures the total size of vectors being queried against.
# When the maximum estimated amount of points that a condition satisfies is smaller than
# `full_scan_threshold_kb`, the query planner will use full-scan search instead of HNSW index
# traversal for better performance.
# Note: 1Kb = 1 vector of size 256
full_scan_threshold: 10000
并在创建集合的过程中。ef参数在搜索期间配置,默认等于ef_construct。
选择 HNSW 的原因有几个。首先,HNSW 与允许 Qdrant 在搜索期间使用过滤器的修改兼容性良好。其次,根据公共基准测试,它是最准确和最快的算法之一。
自 v1.1.1 起可用
HNSW 参数也可以通过设置hnsw_config在集合和命名向量级别进行配置,以微调搜索性能。
稀疏向量索引
自 v1.7.0 起可用
Qdrant 中的稀疏向量使用特殊数据结构进行索引,该结构针对具有高比例零的向量进行了优化。在某些方面,这种索引方法类似于文本搜索引擎中使用的倒排索引。
- Qdrant 中的稀疏向量索引是精确的,这意味着它不使用任何近似算法。
- 添加到集合中的所有稀疏向量都会立即索引到稀疏索引的可变版本中。
借助 Qdrant,您可以受益于更紧凑、更高效的不可变稀疏索引,该索引在与稠密向量索引相同的优化过程中构建。
这种方法对于同时存储稠密向量和稀疏向量的集合特别有用。
要配置稀疏向量索引,请使用以下参数创建集合
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"index": {
"on_disk": false
}
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
index=models.SparseIndexParams(on_disk=False),
)
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"splade-model-name": {
index: {
on_disk: false
}
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, SparseIndexConfigBuilder, SparseVectorParamsBuilder,
SparseVectorsConfigBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"splade-model-name",
SparseVectorParamsBuilder::default()
.index(SparseIndexConfigBuilder::default().on_disk(true)),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections;
QdrantClient client = new QdrantClient(
QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.createCollectionAsync(
Collections.CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
Collections.SparseVectorConfig.newBuilder().putMap(
"splade-model-name",
Collections.SparseVectorParams.newBuilder()
.setIndex(
Collections.SparseIndexConfig
.newBuilder()
.setOnDisk(false)
.build()
).build()
).build()
).build()
).get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("splade-model-name", new SparseVectorParams{
Index = new SparseIndexConfig {
OnDisk = false,
}
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"splade-model-name": {
Index: &qdrant.SparseIndexConfig{
OnDisk: qdrant.PtrOf(false),
}},
}),
})
以下参数可能会影响性能
on_disk: true- 索引存储在磁盘上,可以节省内存。这可能会降低搜索性能。on_disk: false- 索引仍然持久化到磁盘上,但也会加载到内存中以加快搜索速度。
与稠密向量索引不同,稀疏向量索引不需要预定义的向量大小。它会自动调整以适应添加到集合中的向量大小。
注意:稀疏向量索引仅支持点积相似性搜索。它不支持其他距离度量。
IDF 修饰符
自 v1.10.0 起可用
对于许多搜索算法,考虑一个项目在集合中出现的频率很重要。直观地说,一个项目在集合中出现的频率越低,它在搜索中的重要性就越高。
这也称为逆文档频率 (IDF)。它用于文本搜索引擎中,根据单词在集合中的稀有程度对搜索结果进行排名。
IDF 取决于当前存储的文档,因此无法在流式推理模式下的稀疏向量中预先计算。为了支持稀疏向量索引中的 IDF,Qdrant 提供了一个选项,可以自动使用 IDF 统计数据修改稀疏向量查询。
唯一的要求是在集合配置中启用 IDF 修饰符
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"modifier": "idf"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
modifier=models.Modifier.IDF,
),
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"text": {
modifier: "idf"
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Modifier, SparseVectorParamsBuilder, SparseVectorsConfigBuilder,
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"text",
SparseVectorParamsBuilder::default().modifier(Modifier::Idf),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Modifier;
import io.qdrant.client.grpc.Collections.SparseVectorConfig;
import io.qdrant.client.grpc.Collections.SparseVectorParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
SparseVectorConfig.newBuilder()
.putMap("text", SparseVectorParams.newBuilder().setModifier(Modifier.Idf).build()))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("text", new SparseVectorParams {
Modifier = Modifier.Idf,
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"text": {
Modifier: qdrant.Modifier_Idf.Enum(),
},
}),
})
Qdrant 使用以下公式计算 IDF 修饰符
$$ \text{IDF}(q_i) = \ln \left(\frac{N - n(q_i) + 0.5}{n(q_i) + 0.5}+1\right) $$
其中
N是集合中的文档总数。n是包含给定向量元素非零值的文档数量。
可过滤索引
单独的 payload 索引和向量索引无法完全解决使用过滤器进行搜索的问题。
在选择性高(弱)过滤器的情况下,您可以按原样使用 HNSW 索引。在选择性低(严格)过滤器的情况下,您可以使用 payload 索引并进行完整重新评分。
然而,对于中间情况,这种方法效果不佳。一方面,我们不能对太多向量进行完整扫描。另一方面,当使用过于严格的过滤器时,HNSW 图开始崩溃。
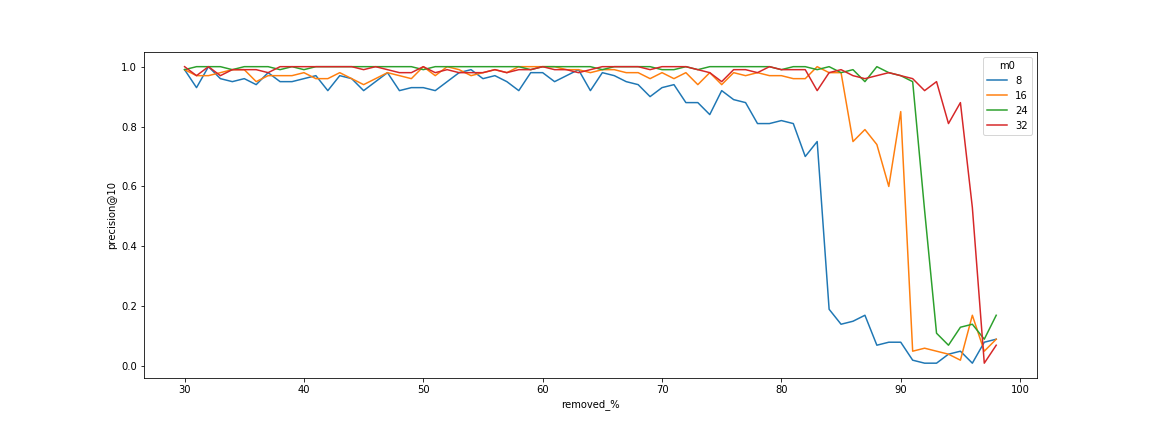
Qdrant 通过使用基于存储的 payload 值扩展 HNSW 图来解决此问题。额外的边允许您使用 HNSW 索引高效地搜索附近的向量,并在搜索图中应用过滤器。您可以在我们的文章中找到有关此方法的更多信息。
然而,在某些情况下,这些额外的边可能不足够。这些额外的边是为每个 payload 索引单独添加的,而不是为它们的每个可能组合添加的。因此,两个或更多严格过滤器的组合仍然可能导致图组件断开。当图中有大量软删除点时,也可能发生同样的情况。在这种情况下,可以使用ACORN 搜索算法。