分布式部署
从 v0.8.0 版本开始,Qdrant 支持分布式部署模式。在此模式下,多个 Qdrant 服务相互通信,将数据分布到各个对等节点,以扩展存储能力并提高稳定性。
我应该运行多少个 Qdrant 节点?
理想的 Qdrant 节点数量取决于您在成本节约、弹性和性能/可扩展性之间如何权衡。
优先考虑成本节约:如果成本对您最重要,则运行单个 Qdrant 节点。不推荐用于生产环境。缺点
- 弹性:用户在节点重启期间会遇到停机,除非您有备份或快照,否则无法恢复。
- 性能:受限于单个服务器的资源。
优先考虑弹性:如果弹性对您最重要,则运行一个包含三个或更多节点以及两个或更多分片副本的 Qdrant 集群。拥有三个或更多节点和复制功能的集群即使在其中一个节点宕机时也能执行所有操作。此外,它们还可以从负载均衡中获得性能优势,并且无需备份或快照即可从单个节点的永久性丢失中恢复(但强烈建议仍然进行备份)。这是生产环境中最推荐的配置。缺点
- 成本:大型集群比小型集群成本更高,这是此配置的唯一缺点。
平衡成本、弹性和性能:运行一个具有复制分片的双节点 Qdrant 集群,允许集群即使在其中一个节点宕机时(例如在维护期间)也能响应大多数读/写请求。拥有两个节点也意味着比单节点集群更高的性能,同时仍比三节点集群更便宜。缺点
- 弹性(正常运行时间):当一个节点宕机时,集群无法对 Collection 执行操作。这些操作需要超过 50% 的节点正常运行,因此只有在 3 个或更多节点的集群中才可能实现。由于创建、编辑和删除 Collection 通常是罕见的操作,许多用户认为此缺点可以忽略不计。
- 弹性(数据完整性):如果两个节点之一的数据永久丢失或损坏,则除了快照或备份外无法恢复。只有 3 个或更多节点的集群才能从单个节点的永久丢失中恢复,因为恢复操作需要集群中超过 50% 的节点健康。
- 成本:复制分片需要存储数据的两个副本。
- 性能:Qdrant 集群的最大性能随着您添加更多节点而增加。
总之,单节点集群最适合非生产工作负载,复制的 3 个或更多节点集群是黄金标准,而复制的双节点集群则取得了良好的平衡。
在自托管 Qdrant 中启用分布式模式
要启用分布式部署,请在配置中启用集群模式,或使用环境变量:QDRANT__CLUSTER__ENABLED=true。
cluster:
# Use `enabled: true` to run Qdrant in distributed deployment mode
enabled: true
# Configuration of the inter-cluster communication
p2p:
# Port for internal communication between peers
port: 6335
# Configuration related to distributed consensus algorithm
consensus:
# How frequently peers should ping each other.
# Setting this parameter to lower value will allow consensus
# to detect disconnected node earlier, but too frequent
# tick period may create significant network and CPU overhead.
# We encourage you NOT to change this parameter unless you know what you are doing.
tick_period_ms: 100
默认情况下,Qdrant 将使用端口 6335 进行内部通信。集群内的所有对等节点都应可以通过此端口访问,但请确保将此端口与外部访问隔离,因为它可能用于执行写操作。
此外,您必须向第一个对等节点提供 --uri 标志,以便它可以告诉其他节点如何访问它
./qdrant --uri 'http://qdrant_node_1:6335'
集群中的后续对等节点必须知道现有集群中的至少一个节点,以便通过它与集群的其余部分同步。
为此,需要为它们提供引导 URL
./qdrant --bootstrap 'http://qdrant_node_1:6335'
新对等节点本身的 URL 将根据其请求的 IP 地址自动计算。但也可能使用 --uri 参数单独提供它们。
USAGE:
qdrant [OPTIONS]
OPTIONS:
--bootstrap <URI>
Uri of the peer to bootstrap from in case of multi-peer deployment. If not specified -
this peer will be considered as a first in a new deployment
--uri <URI>
Uri of this peer. Other peers should be able to reach it by this uri.
This value has to be supplied if this is the first peer in a new deployment.
In case this is not the first peer and it bootstraps the value is optional. If not
supplied then qdrant will take internal grpc port from config and derive the IP address
of this peer on bootstrap peer (receiving side)
成功同步后,您可以通过 REST API 观察集群的状态
GET /cluster
示例结果
{
"result": {
"status": "enabled",
"peer_id": 11532566549086892000,
"peers": {
"9834046559507417430": {
"uri": "http://172.18.0.3:6335/"
},
"11532566549086892528": {
"uri": "http://qdrant_node_1:6335/"
}
},
"raft_info": {
"term": 1,
"commit": 4,
"pending_operations": 1,
"leader": 11532566549086892000,
"role": "Leader"
}
},
"status": "ok",
"time": 5.731e-06
}
请注意,启用分布式模式不会自动复制您的数据。有关后续步骤,请参阅关于使用新的分布式 Qdrant 集群的部分。
在 Qdrant Cloud 中启用分布式模式
为获得最佳结果,请首先确保您的集群正在运行 Qdrant v1.7.4 或更高版本。旧版本的 Qdrant 确实支持分布式模式,但 v1.7.4 中的改进使分布式集群在中断期间更具弹性。
在 Qdrant Cloud 控制台中,点击“Scale Up”将集群大小增加到 >1。Qdrant Cloud 会自动配置分布式模式设置。
规模扩展过程完成后,您将拥有一个与现有节点并行运行的新的空节点。要将数据复制到这个新的空节点中,请参阅下一节。
使用新的分布式 Qdrant 集群
当您启用分布式模式并扩展到两个或更多节点时,您的数据不会自动移动到新节点;它最初是空的。要利用您的新空节点,请执行以下操作之一
- 通过将复制因子 (replication_factor) 设置为 2 或更多,并将分片数量 (number of shards) 设置为您节点数量的倍数,来创建一个新的复制 Collection。
- 如果您现有的 Collection 没有足够的 shard 供每个节点使用,则必须按照上一个要点中的描述创建一个新的 Collection。
- 如果您已经为每个节点配置了足够数量的 shard,并且您只需要复制数据,请按照创建新的 shard 副本的说明进行操作。
- 如果您已经为每个节点配置了足够数量的 shard 并且数据已经复制,您可以通过移动 shard 将数据(无需复制)移动到新的节点上。
Raft
Qdrant 使用 Raft 一致性协议来维护集群拓扑和 Collection 结构的一致性。
另一方面,对 point 的操作不经过一致性基础设施。Qdrant 不旨在提供强事务保证,这使得它可以以低开销执行 point 操作。实际上,这意味着 Qdrant 不保证原子分布式更新,但允许您等待操作完成以查看写入结果。
相反,对 Collection 的操作是一致性协议的一部分,这保证所有操作都是持久的,并最终由所有节点执行。实际上,这意味着在服务执行操作之前,大多数节点会就应应用的操作达成一致。
实际上,这意味着如果集群处于过渡状态——无论是故障后选举新 leader 还是正在启动,对 Collection 的更新操作都将被拒绝。
您可以使用集群 REST API 检查一致性协议的状态。
分片
Qdrant 中的一个 Collection 由一个或多个 shard 组成。Shard 是一个独立的 point 存储单元,能够执行 Collection 提供的所有操作。将 point 分布到 shard 有两种方法
自动分片:使用一致性哈希算法将 Point 分布到 shard 中,这样 shard 管理的是不相交的 Point 子集。这是默认行为。
用户定义分片:(v1.7.0 起可用) - 每个 Point 上传到特定的 shard,以便操作仅影响所需的 shard。即使采用这种分布方式,shard 仍确保管理不相交的 Point 子集。查看更多…
每个节点通过一致性协议知道 Collection 的所有部分存储在哪里,因此当您向一个 Qdrant 节点发送搜索请求时,它会自动查询所有其他节点以获取完整的搜索结果。
选择合适的分片数量
创建 Collection 时,Qdrant 会将 Collection 分割成 shard_number 个 shard。如果未设置,shard_number 将设置为创建 Collection 时集群中的节点数量。不重新创建 Collection 则无法更改 shard_number。
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=300, distance=models.Distance.COSINE),
shard_number=6,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 300,
distance: "Cosine",
},
shard_number: 6,
});
use qdrant_client::qdrant::{CreateCollectionBuilder, Distance, VectorParamsBuilder};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(300, Distance::Cosine))
.shard_number(6),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(300)
.setDistance(Distance.Cosine)
.build())
.build())
.setShardNumber(6)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 300, Distance = Distance.Cosine },
shardNumber: 6
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 300,
Distance: qdrant.Distance_Cosine,
}),
ShardNumber: qdrant.PtrOf(uint32(6)),
})
为确保集群中所有节点得到均匀利用,shard 数量必须是您当前集群中节点数量的倍数。
附注:多租户等高级用例可能需要不均匀的 shard 分布。请参阅多租户。
我们建议每个节点创建至少 2 个 shard,以便将来扩展而无需重新分片。重新分片 (Resharding) 在使用我们的云服务时是可能的,但在其他地方托管时应避免,因为它需要创建一个新的 Collection。
如果您预计会有大量增长,我们建议设置 12 个 shard,因为您可以从 1 个节点扩展到 2、3、6 和 12 个节点,而无需重新分片。在小型集群中拥有超过 12 个 shard 可能不值得性能开销。
Collection 初次创建时,shard 会均匀分布在所有现有节点上,但如果您的集群大小或复制因子发生变化,Qdrant 不会自动重新平衡 shard(因为这在大型集群上是一个昂贵的操作)。有关扩展操作后如何移动 shard,请参阅下一节。
重新分片 (Resharding)
v1.13.0 起在云中可用
如果您使用我们的云服务托管,Resharding 允许您更改现有 Collection 中的 shard 数量。
Resharding 可以增加或减少 shard 数量,而无需从头重新创建 Collection。
请参阅我们的云文档中的重新分片 (Resharding) 部分以获取更多详细信息。
移动分片
v0.9.0 起可用
Qdrant 允许在集群节点之间移动 shard 并从集群中移除节点。此功能开启了动态扩展集群大小而无需停机的能力。它还允许您在不停机的情况下升级或迁移节点。
Qdrant 通过 Collection 集群信息 API 提供有关集群中当前 shard 分布的信息。
使用 更新 Collection 集群设置 API 来启动 shard 传输
POST /collections/{collection_name}/cluster
{
"move_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995
}
}
传输启动后,服务将根据使用的传输方法进行处理,保持两个 shard 同步。传输完成后,旧的 shard 将从源节点删除。
如果您想缩减集群规模,可以将所有 shard 从某个对等节点移开,然后使用移除对等节点 API 移除该对等节点。
DELETE /cluster/peer/{peer_id}
之后,Qdrant 将把该节点从一致性协议中排除,该实例即可准备关闭。
用户定义分片
v1.7.0 起可用
Qdrant 允许您单独指定每个 point 所属的 shard。如果您想控制数据的 shard 位置,以便操作只影响实际需要的 shard 子集,则此功能非常有用。在大型集群中,这可以显著提高不需要扫描整个 Collection 的操作的性能。
此功能的一个明确用例是管理多租户 Collection,其中每个租户(无论是用户还是组织)都被假定为隔离的,因此他们的数据可以存储在单独的 shard 中。
要启用用户定义分片,请在创建 Collection 时将 sharding_method 设置为 custom
PUT /collections/{collection_name}
{
"shard_number": 1,
"sharding_method": "custom"
// ... other collection parameters
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
shard_number=1,
sharding_method=models.ShardingMethod.CUSTOM,
# ... other collection parameters
)
client.create_shard_key("{collection_name}", "{shard_key}")
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
shard_number: 1,
sharding_method: "custom",
// ... other collection parameters
});
client.createShardKey("{collection_name}", {
shard_key: "{shard_key}"
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, CreateShardKeyBuilder, CreateShardKeyRequestBuilder, Distance,
ShardingMethod, VectorParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(300, Distance::Cosine))
.shard_number(1)
.sharding_method(ShardingMethod::Custom.into()),
)
.await?;
client
.create_shard_key(
CreateShardKeyRequestBuilder::new("{collection_name}")
.request(CreateShardKeyBuilder::default().shard_key("{shard_key".to_string())),
)
.await?;
import static io.qdrant.client.ShardKeyFactory.shardKey;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.ShardingMethod;
import io.qdrant.client.grpc.Collections.CreateShardKey;
import io.qdrant.client.grpc.Collections.CreateShardKeyRequest;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
// ... other collection parameters
.setShardNumber(1)
.setShardingMethod(ShardingMethod.Custom)
.build())
.get();
client.createShardKeyAsync(CreateShardKeyRequest.newBuilder()
.setCollectionName("{collection_name}")
.setRequest(CreateShardKey.newBuilder()
.setShardKey(shardKey("{shard_key}"))
.build())
.build()).get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
// ... other collection parameters
shardNumber: 1,
shardingMethod: ShardingMethod.Custom
);
await client.CreateShardKeyAsync(
"{collection_name}",
new CreateShardKey { ShardKey = new ShardKey { Keyword = "{shard_key}", } }
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
// ... other collection parameters
ShardNumber: qdrant.PtrOf(uint32(1)),
ShardingMethod: qdrant.ShardingMethod_Custom.Enum(),
})
client.CreateShardKey(context.Background(), "{collection_name}", &qdrant.CreateShardKey{
ShardKey: qdrant.NewShardKey("{shard_key}"),
})
在此模式下,shard_number 表示每个 shard key 的 shard 数量,point 将均匀分布。例如,如果您有 10 个 shard key 并且 Collection 配置如下
{
"shard_number": 1,
"sharding_method": "custom",
"replication_factor": 2
}
那么您的 Collection 中总共将有 1 * 10 * 2 = 20 个物理 shard。
物理 shard 需要大量资源,因此请确保您的自定义 sharding key 的基数较低。
对于高基数 key,建议改为使用按载荷分区。
要为每个 point 指定 shard,您需要在 upsert 请求中提供 shard_key 字段
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1111,
"vector": [0.1, 0.2, 0.3]
},
]
"shard_key": "user_1"
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1111,
vector=[0.1, 0.2, 0.3],
),
],
shard_key_selector="user_1",
)
client.upsert("{collection_name}", {
points: [
{
id: 1111,
vector: [0.1, 0.2, 0.3],
},
],
shard_key: "user_1",
});
use qdrant_client::qdrant::{PointStruct, UpsertPointsBuilder};
use qdrant_client::Payload;
client
.upsert_points(
UpsertPointsBuilder::new(
"{collection_name}",
vec![PointStruct::new(
111,
vec![0.1, 0.2, 0.3],
Payload::default(),
)],
)
.shard_key_selector("user_1".to_string()),
)
.await?;
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ShardKeySelectorFactory.shardKeySelector;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
import io.qdrant.client.grpc.Points.UpsertPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
UpsertPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllPoints(
List.of(
PointStruct.newBuilder()
.setId(id(111))
.setVectors(vectors(0.1f, 0.2f, 0.3f))
.build()))
.setShardKeySelector(shardKeySelector("user_1"))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new() { Id = 111, Vectors = new[] { 0.1f, 0.2f, 0.3f } }
},
shardKeySelector: new ShardKeySelector { ShardKeys = { new List<ShardKey> { "user_1" } } }
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: "{collection_name}",
Points: []*qdrant.PointStruct{
{
Id: qdrant.NewIDNum(111),
Vectors: qdrant.NewVectors(0.1, 0.2, 0.3),
},
},
ShardKeySelector: &qdrant.ShardKeySelector{
ShardKeys: []*qdrant.ShardKey{
qdrant.NewShardKey("user_1"),
},
},
})
现在,您可以通过在任何操作中指定 shard_key 来定位到特定的 shard。未指定 shard key 的操作将在所有 shard 上执行。
另一个用例是让 shard 按时间顺序跟踪数据,以便您可以执行更复杂的流程,例如在一个 shard 中上传实时数据,并在达到一定年龄后将其归档。
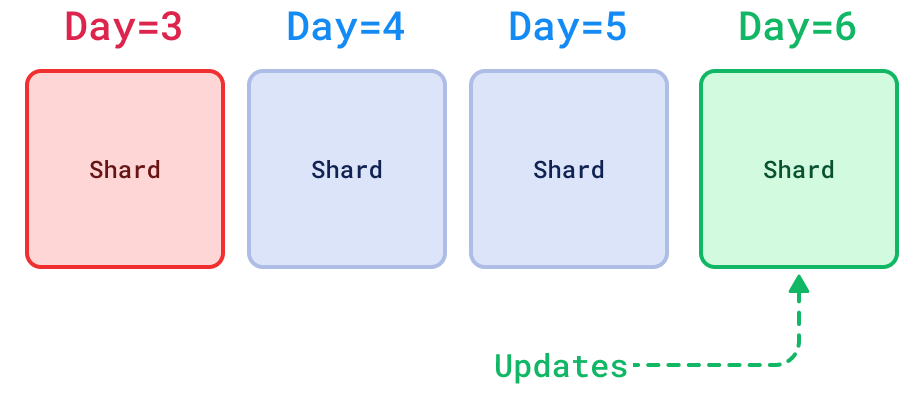
分片传输方法
v1.7.0 起可用
将 shard 转移到另一个节点有不同的方法,例如移动或复制。根据您想要的性能和保证以及您希望如何管理集群,您可能希望选择特定的方法。每种方法都有自己的优缺点。哪种方法最快取决于 shard 的大小和状态。
可用的 shard 传输方法有
stream_records:(默认)通过将记录批量流式传输到目标节点进行传输。snapshot:通过自动利用快照传输,包括其索引和量化数据。wal_delta:(自动恢复默认)通过解析WAL 差异进行传输;即遗漏的操作。
每种方法都有优点、缺点和特定要求,其中一些如下
| 方法 | 流式记录 | 快照 | WAL 增量 |
|---|---|---|---|
| 版本 | v0.8.0+ | v1.7.0+ | v1.8.0+ |
| 目标 | 新的/现有的 shard | 新的/现有的 shard | 现有的 shard |
| 连接性 | 内部 gRPC API (6335) | REST API (6333) 内部 gRPC API (6335) | 内部 gRPC API (6335) |
| HNSW 索引 | 不传输,将在目标上重新索引。 | 传输,在目标上立即可用。 | 不传输,可能在目标上索引。 |
| 量化 | 不传输,将在目标上重新量化。 | 传输,在目标上立即可用。 | 不传输,可能在目标上量化。 |
| 顺序 | 目标上无序更新1 | 目标上有序更新2 | 目标上有序更新2 |
| 磁盘空间 | 无需额外空间 | 在两个节点上都需要额外空间用于快照 | 无需额外空间 |
要选择 shard 传输方法,请指定 method,例如
POST /collections/{collection_name}/cluster
{
"move_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995,
"method": "snapshot"
}
}
stream_records 传输方法是最简单的可用方法。它只是将所有 shard 记录批量传输到目标节点,直到传输完所有记录,保持两个 shard 同步。它还会确保传输的 shard 索引过程在执行最终切换之前跟上进度。该方法有两个常见的缺点:1. 它不传输索引或量化数据,这意味着 shard 必须在新节点上再次优化,这可能非常昂贵。2. 顺序保证是弱的1,不适用于某些应用程序。由于它非常简单,因此也非常健壮,如果您的用例可以接受上述缺点,它是一个可靠的选择。如果您的集群不稳定且资源不足,最好使用 stream_records 传输方法,因为它不太可能失败。
snapshot 传输方法利用快照来传输 shard。快照会自动创建。然后将其传输并在目标节点上恢复。完成后,快照会从两个节点中删除。在快照/传输/恢复操作期间,源节点会将所有新操作排队。然后按顺序将所有排队的更新发送到目标 shard,使其与源 shard 处于相同状态。这有两个重要的好处:1. 它传输索引和量化数据,因此 shard 不必在目标节点上再次优化,使其立即可用。这样,Qdrant 确保在传输结束时不会出现性能下降。特别是在大型 shard 上,这可以带来巨大的性能提升。2. 顺序保证可以是强的2,某些应用程序需要此特性。
wal_delta 传输方法仅传输两个 shard 之间的差异。更具体地说,它将所有遗漏的操作传输到目标 shard。使用两个 shard 的 WAL 来解决此问题。这有两个好处:1. 它会非常快,因为它只传输差异而不是所有数据。2. 顺序保证可以是强的2,某些应用程序需要此特性。两个缺点是:1. 它只能用于传输到另一个节点上已存在的 shard。2. 适用性有限,因为 WAL 通常只包含不超过 64MB 的近期操作。但这对于快速重启的节点(例如为了升级)来说应该足够了。如果无法解析差异,此方法会自动回退到 stream_records,这相当于传输整个 shard。
stream_records 方法目前用作默认方法。将来可能会改变。从 Qdrant 1.9.0 开始,wal_delta 用于自动进行 shard 复制以恢复宕机的 shard。
复制
Qdrant 允许您在集群节点之间复制 shard。
Shard 复制通过在集群中分散保存 shard 的多个副本来提高集群的可靠性。这确保了在节点故障时数据的可用性,除非所有副本都丢失。
复制因子
创建 Collection 时,您可以通过更改 replication_factor 来控制要存储多少个 shard 副本。默认情况下,replication_factor 设置为“1”,这意味着不会自动维护额外副本。可以在Qdrant 配置中更改默认值。您可以在创建 Collection 时设置 replication_factor 来更改它。
可以更新现有 Collection 的 replication_factor,但这取决于您如何运行 Qdrant。如果您自行托管开源版本的 Qdrant,在创建 Collection 后更改复制因子不会产生任何效果。您可以手动创建或删除 shard 副本以达到所需的复制因子。在 Qdrant Cloud(包括混合云、私有云)中,您的 shard 将根据配置的复制因子自动复制或删除。
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=300, distance=models.Distance.COSINE),
shard_number=6,
replication_factor=2,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 300,
distance: "Cosine",
},
shard_number: 6,
replication_factor: 2,
});
use qdrant_client::qdrant::{CreateCollectionBuilder, Distance, VectorParamsBuilder};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(300, Distance::Cosine))
.shard_number(6)
.replication_factor(2),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(300)
.setDistance(Distance.Cosine)
.build())
.build())
.setShardNumber(6)
.setReplicationFactor(2)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 300, Distance = Distance.Cosine },
shardNumber: 6,
replicationFactor: 2
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 300,
Distance: qdrant.Distance_Cosine,
}),
ShardNumber: qdrant.PtrOf(uint32(6)),
ReplicationFactor: qdrant.PtrOf(uint32(2)),
})
此代码示例创建一个总共包含 6 个逻辑 shard 的 Collection,由总共 12 个物理 shard 提供支持。
由于复制因子为“2”将需要两倍的存储空间,因此建议事先确保硬件能够容纳额外的 shard 副本。
创建新的分片副本
可以使用更新 Collection 集群设置 API 在现有 Collection 上手动创建或删除副本。这通常仅在您运行 Qdrant 开源版本时需要。在 Qdrant Cloud 中,shard 复制是自动处理和更新的,以匹配配置的 replication_factor。
可以通过指定从中复制的对等节点,在特定对等节点上添加副本。
POST /collections/{collection_name}/cluster
{
"replicate_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995
}
}
并且可以在特定对等节点上删除副本。
POST /collections/{collection_name}/cluster
{
"drop_replica": {
"shard_id": 0,
"peer_id": 381894127
}
}
请记住,Collection 必须至少包含一个 shard 的活动副本。
错误处理
副本可能处于不同的状态
- 活动:健康且准备好处理流量
- 宕机:不健康且未准备好处理流量
- 部分:激活前当前正在重新同步
如果副本未响应内部健康检查或无法处理流量,则会被标记为宕机。
宕机的副本将不会接收来自其他对等节点的流量,如果它没有自动恢复,可能需要手动干预。
此机制可确保在更新操作期间部分副本发生故障时的数据一致性和可用性。
节点故障恢复
有时硬件故障可能导致 Qdrant 集群的某些节点无法恢复。任何系统都无法幸免于此。
但有几种恢复场景可以使 Qdrant 保持对请求的可用性,甚至避免性能下降。让我们从最好到最坏依次介绍。
使用复制的 Collection 恢复
如果故障节点的数量小于 Collection 的复制因子,那么您的集群应该仍然能够执行读、搜索和更新查询。
现在,如果故障节点重新启动,一致性协议将触发复制过程,用它遗漏的最新更新来更新恢复中的节点。
如果故障节点从未重新启动,如果您有 3 个或更多节点的集群,则可以恢复丢失的 shard。在较小的集群中无法恢复丢失的 shard,因为恢复操作是通过Raft进行的,这需要超过 50% 的节点健康。
使用复制的 Collection 重新创建节点
如果节点发生故障且无法恢复,您应该将宕机节点从一致性协议中排除并创建一个空节点。
要将故障节点从一致性协议中排除,请使用移除对等节点 API。如有必要,请使用 force 标志。
创建新节点时,请务必通过指定 --bootstrap CLI 参数以及任何正在运行的集群节点的 URL,将其附加到现有集群。
新节点准备就绪并与集群同步后,您可能需要确保 Collection shard 被充分复制。请记住,Qdrant 不会自动平衡 shard,因为这是一项昂贵的操作。使用复制 Shard 操作在新连接的节点上创建 shard 的另一个副本。
值得一提的是,Qdrant 只提供了创建自动化故障恢复所需的构建块。构建一个完全自动化的 Collection 扩展过程需要对集群机器本身进行控制。查看我们的云解决方案,我们正是在那里实现了这一点。
从快照恢复
如果集群中没有数据副本,仍然可以从快照恢复。
按照相同的步骤分离故障节点并在集群中创建一个新节点
- 要将故障节点从一致性协议中排除,请使用移除对等节点 API。如有必要,请使用
force标志。 - 创建一个新节点,并通过指定
--bootstrapCLI 参数以及任何正在运行的集群节点的 URL,确保将其附加到现有集群。
在单节点部署中使用的快照恢复与集群中的不同。一致性协议管理所有 Collection 的所有元数据,并且不需要快照来恢复它。但您可以使用快照来恢复 Collection 中丢失的 shard。
使用Collection 快照恢复 API 来执行此操作。服务将下载指定 Collection 的快照,并从中恢复包含数据的 shard。
一旦 Collection 的所有 shard 都恢复,Collection 将再次变为可操作状态。
临时节点故障
如果配置得当,以分布式模式运行 Qdrant 可以使您的集群在单个节点临时故障时具有抗中断能力。
以下是不同配置的 Qdrant 集群的响应方式
- 1 节点集群:所有操作都会超时或失败,最长达几分钟。这取决于重启并从磁盘加载数据所需的时间。
- 2 节点集群,其中 shard 未复制:所有操作都会超时或失败,最长达几分钟。这取决于重启并从磁盘加载数据所需的时间。
- 2 节点集群,其中所有 shard 都复制到两个节点:除了对 Collection 的操作外,所有请求在中断期间继续正常工作。
- 3 个或更多节点的集群,其中所有 shard 都复制到至少 2 个节点:所有请求在中断期间继续正常工作。
一致性保证
默认情况下,Qdrant 侧重于搜索操作的可用性和最大吞吐量。对于大多数用例,这是一个更可取的权衡。
在正常运行状态下,可以从集群中的任何对等节点搜索和修改数据。
在响应客户端之前,处理请求的对等节点会根据当前拓扑调度所有操作,以保持整个集群的数据同步。
- 读取操作使用部分扇出策略来优化延迟和可用性
- 写入操作在所有活动的 shard 副本上并行执行
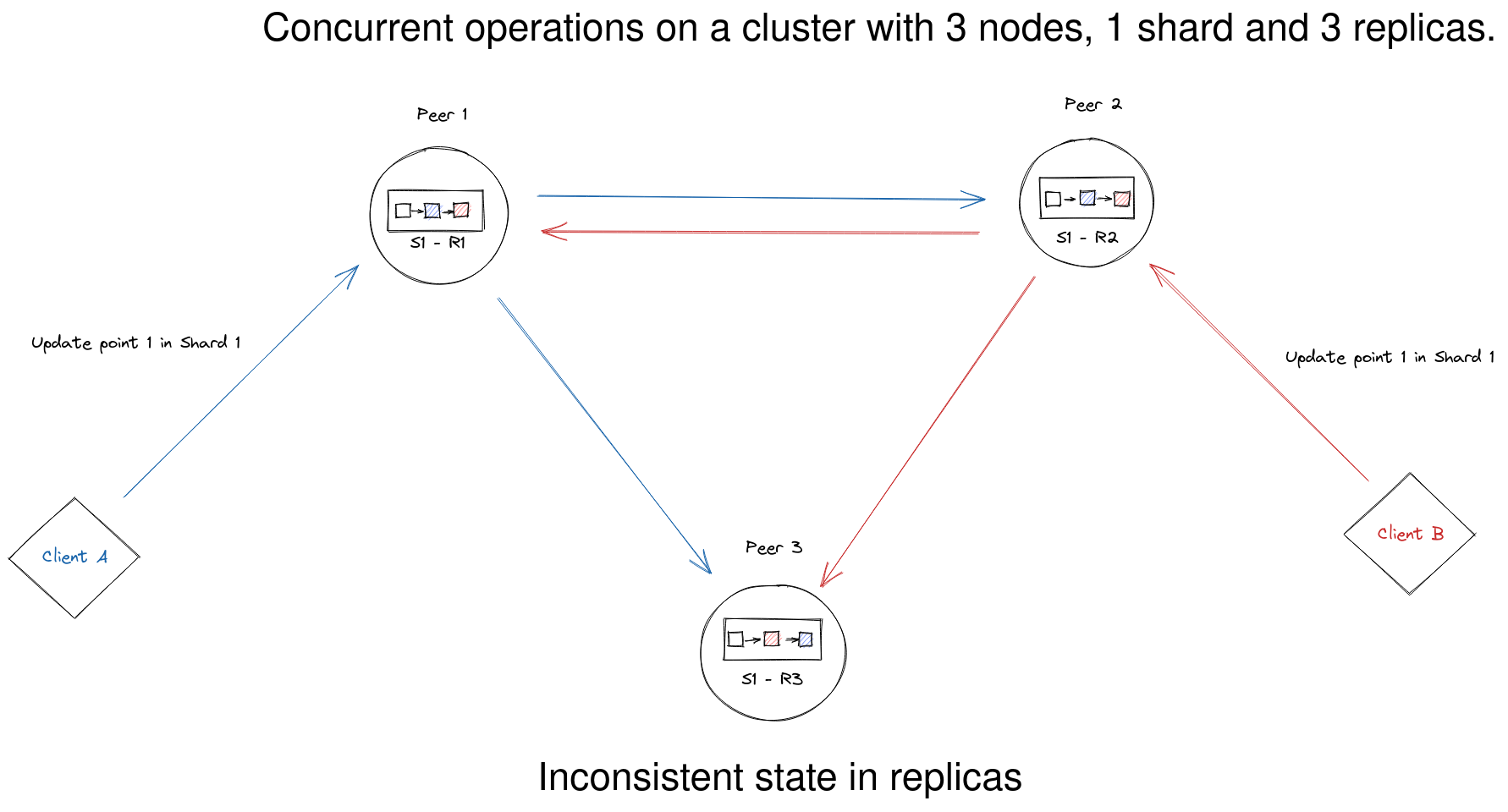
然而,在某些情况下,有必要在可能的硬件不稳定、同一文档的大量并发更新等情况下确保额外的保证。
Qdrant 提供了一些选项来控制一致性保证
write_consistency_factor- 定义在响应客户端之前必须确认写操作的副本数量。增加此值将使写操作能够容忍集群中的网络分区,但需要更多的活动副本才能执行写操作。- 读操作的
consistency参数,可与搜索和检索操作一起使用,以确保从所有副本获得的结果相同。如果使用此选项,Qdrant 将在多个副本上执行读操作,并根据选定的策略解析结果。此选项有助于避免同一文档并发更新时的数据不一致。如果更新操作频繁且副本数量较少,则优先选择此选项。 - 写操作的
ordering参数,可与更新和删除操作一起使用,以确保操作在所有副本上以相同的顺序执行。如果使用此选项,Qdrant 将把操作路由到 shard 的 leader 副本,并等待响应后才响应客户端。此选项有助于避免同一文档并发更新时的数据不一致。如果读操作比更新操作更频繁,且搜索性能至关重要,则优先选择此选项。
写一致性因子
write_consistency_factor 表示在响应客户端之前必须确认写操作的副本数量。默认设置为 1。可以在创建 Collection 或更新 Collection 参数时进行配置。
此值范围从 1 到每个 shard 的副本数量。
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2,
"write_consistency_factor": 2
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=300, distance=models.Distance.COSINE),
shard_number=6,
replication_factor=2,
write_consistency_factor=2,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 300,
distance: "Cosine",
},
shard_number: 6,
replication_factor: 2,
write_consistency_factor: 2,
});
use qdrant_client::qdrant::{CreateCollectionBuilder, Distance, VectorParamsBuilder};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(300, Distance::Cosine))
.shard_number(6)
.replication_factor(2)
.write_consistency_factor(2),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(300)
.setDistance(Distance.Cosine)
.build())
.build())
.setShardNumber(6)
.setReplicationFactor(2)
.setWriteConsistencyFactor(2)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 300, Distance = Distance.Cosine },
shardNumber: 6,
replicationFactor: 2,
writeConsistencyFactor: 2
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 300,
Distance: qdrant.Distance_Cosine,
}),
ShardNumber: qdrant.PtrOf(uint32(6)),
ReplicationFactor: qdrant.PtrOf(uint32(2)),
WriteConsistencyFactor: qdrant.PtrOf(uint32(2)),
})
如果活动副本的数量小于 write_consistency_factor,写操作将失败。在这种情况下,客户端需要再次发送操作以确保达到一致状态。
将 write_consistency_factor 设置为较低值,即使存在无响应的节点,也可能允许接受写入。无响应的节点会被标记为宕机,一旦可用将自动恢复以确保数据一致性。
write_consistency_factor 的配置对于调整集群在某些节点因重启、升级或故障而离线时的行为非常重要。
默认情况下,只要每个 shard 至少有一个副本在线,集群就会继续接受更新。然而,这种行为意味着一旦离线副本恢复,它将需要与集群的其余部分进行额外的同步。在某些情况下,这种同步可能会消耗大量资源且不受欢迎。
将 write_consistency_factor 设置为与复制因子匹配,会修改集群的行为,从而拒绝未复制的更新,避免额外的同步需求。
如果更新被应用到足够数量的副本——根据 write_consistency_factor——更新将返回成功状态。任何未能应用更新的副本将被临时禁用,并自动恢复以保持数据一致性。如果更新未能应用到足够数量的副本,则会返回错误并可能部分应用。用户必须再次提交操作以确保数据一致性。
对于能够处理错误和重试的异步更新和注入 pipeline,此策略可能更可取。
读一致性
读请求的 consistency 参数可以为大多数读请求指定,并将确保返回的结果在集群节点间保持一致。
all将查询所有节点,并返回在所有节点上都存在的 pointmajority将查询所有节点,并返回在大多数节点上都存在的 pointquorum将查询随机选择的大多数节点,并返回在所有这些节点上都存在的 point1/2/3/等 - 将查询指定数量的随机选择的节点,并返回在所有这些节点上都存在的 point- 默认
consistency为1
POST /collections/{collection_name}/points/query?consistency=majority
{
"query": [0.2, 0.1, 0.9, 0.7],
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"limit": 3
}
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
query_filter=models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(
value="London",
),
)
]
),
search_params=models.SearchParams(hnsw_ef=128, exact=False),
limit=3,
consistency="majority",
)
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
filter: {
must: [{ key: "city", match: { value: "London" } }],
},
params: {
hnsw_ef: 128,
exact: false,
},
limit: 3,
consistency: "majority",
});
use qdrant_client::qdrant::{
read_consistency::Value, Condition, Filter, QueryPointsBuilder, ReadConsistencyType,
SearchParamsBuilder,
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.filter(Filter::must([Condition::matches(
"city",
"London".to_string(),
)]))
.params(SearchParamsBuilder::default().hnsw_ef(128).exact(false))
.read_consistency(Value::Type(ReadConsistencyType::Majority.into())),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.QueryPoints;
import io.qdrant.client.grpc.Points.ReadConsistency;
import io.qdrant.client.grpc.Points.ReadConsistencyType;
import io.qdrant.client.grpc.Points.SearchParams;
import static io.qdrant.client.QueryFactory.nearest;
import static io.qdrant.client.ConditionFactory.matchKeyword;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setFilter(Filter.newBuilder().addMust(matchKeyword("city", "London")).build())
.setQuery(nearest(.2f, 0.1f, 0.9f, 0.7f))
.setParams(SearchParams.newBuilder().setHnswEf(128).setExact(false).build())
.setLimit(3)
.setReadConsistency(
ReadConsistency.newBuilder().setType(ReadConsistencyType.Majority).build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
filter: MatchKeyword("city", "London"),
searchParams: new SearchParams { HnswEf = 128, Exact = false },
limit: 3,
readConsistency: new ReadConsistency { Type = ReadConsistencyType.Majority }
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Filter: &qdrant.Filter{
Must: []*qdrant.Condition{
qdrant.NewMatch("city", "London"),
},
},
Params: &qdrant.SearchParams{
HnswEf: qdrant.PtrOf(uint64(128)),
},
Limit: qdrant.PtrOf(uint64(3)),
ReadConsistency: qdrant.NewReadConsistencyType(qdrant.ReadConsistencyType_Majority),
})
写顺序
写请求的 ordering 参数可以为任何写请求指定,以通过单个“leader”节点对其进行序列化,从而确保所有写操作(使用相同的 ordering 发出)按顺序执行和观察。
weak(默认)顺序不提供任何额外保证,因此写操作可以自由重新排序。medium顺序通过动态选举的 leader 对所有写操作进行序列化,这可能在 leader 变更时导致微小的不一致。strong顺序通过永久 leader 对所有写操作进行序列化,这提供了强一致性,但如果 leader 宕机,写操作可能不可用。
PUT /collections/{collection_name}/points?ordering=strong
{
"batch": {
"ids": [1, 2, 3],
"payloads": [
{"color": "red"},
{"color": "green"},
{"color": "blue"}
],
"vectors": [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9]
]
}
}
client.upsert(
collection_name="{collection_name}",
points=models.Batch(
ids=[1, 2, 3],
payloads=[
{"color": "red"},
{"color": "green"},
{"color": "blue"},
],
vectors=[
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9],
],
),
ordering=models.WriteOrdering.STRONG,
)
client.upsert("{collection_name}", {
batch: {
ids: [1, 2, 3],
payloads: [{ color: "red" }, { color: "green" }, { color: "blue" }],
vectors: [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9],
],
},
ordering: "strong",
});
use qdrant_client::qdrant::{
PointStruct, UpsertPointsBuilder, WriteOrdering, WriteOrderingType
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("https://:6334").build()?;
client
.upsert_points(
UpsertPointsBuilder::new(
"{collection_name}",
vec![
PointStruct::new(1, vec![0.9, 0.1, 0.1], [("color", "red".into())]),
PointStruct::new(2, vec![0.1, 0.9, 0.1], [("color", "green".into())]),
PointStruct::new(3, vec![0.1, 0.1, 0.9], [("color", "blue".into())]),
],
)
.ordering(WriteOrdering {
r#type: WriteOrderingType::Strong.into(),
}),
)
.await?;
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.grpc.Points.PointStruct;
import io.qdrant.client.grpc.Points.UpsertPoints;
import io.qdrant.client.grpc.Points.WriteOrdering;
import io.qdrant.client.grpc.Points.WriteOrderingType;
client
.upsertAsync(
UpsertPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllPoints(
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(0.9f, 0.1f, 0.1f))
.putAllPayload(Map.of("color", value("red")))
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(vectors(0.1f, 0.9f, 0.1f))
.putAllPayload(Map.of("color", value("green")))
.build(),
PointStruct.newBuilder()
.setId(id(3))
.setVectors(vectors(0.1f, 0.1f, 0.94f))
.putAllPayload(Map.of("color", value("blue")))
.build()))
.setOrdering(WriteOrdering.newBuilder().setType(WriteOrderingType.Strong).build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new[] { 0.9f, 0.1f, 0.1f },
Payload = { ["color"] = "red" }
},
new()
{
Id = 2,
Vectors = new[] { 0.1f, 0.9f, 0.1f },
Payload = { ["color"] = "green" }
},
new()
{
Id = 3,
Vectors = new[] { 0.1f, 0.1f, 0.9f },
Payload = { ["color"] = "blue" }
}
},
ordering: WriteOrderingType.Strong
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: "{collection_name}",
Points: []*qdrant.PointStruct{
{
Id: qdrant.NewIDNum(1),
Vectors: qdrant.NewVectors(0.9, 0.1, 0.1),
Payload: qdrant.NewValueMap(map[string]any{"color": "red"}),
},
{
Id: qdrant.NewIDNum(2),
Vectors: qdrant.NewVectors(0.1, 0.9, 0.1),
Payload: qdrant.NewValueMap(map[string]any{"color": "green"}),
},
{
Id: qdrant.NewIDNum(3),
Vectors: qdrant.NewVectors(0.1, 0.1, 0.9),
Payload: qdrant.NewValueMap(map[string]any{"color": "blue"}),
},
},
Ordering: &qdrant.WriteOrdering{
Type: qdrant.WriteOrderingType_Strong,
},
})
监听器模式
在某些情况下,拥有一个只累积数据而不参与搜索操作的 Qdrant 节点可能很有用。有几种场景下这很有用
- 监听器选项可用于将数据存储在单独的节点中,该节点可用于备份目的或长时间存储数据。
- 监听器节点可用于将数据同步到另一个区域,同时仍在本地区域执行搜索操作。
要启用监听器模式,请在配置文件中将 node_type 设置为 Listener
storage:
node_type: "Listener"
监听器节点将不参与搜索操作,但仍将接受写操作并将数据存储在本地存储中。
存储在监听器节点上的所有 shard 都将转换为 Listener 状态。
此外,所有发送到监听器节点的写请求都将使用 wait=false 选项处理,这意味着写操作在写入 WAL 后即被视为成功。这种机制应该能够在并行快照时最小化 upsert 延迟。
一致性协议检查点
一致性协议检查点是 Raft 中使用的一种技术,通过定期创建系统状态的一致性快照来提高性能并简化日志管理。此快照代表集群中所有节点已就状态达成一致的时间点,可用于截断日志,减少需要在节点之间存储和传输的数据量。
例如,如果您将新节点附加到集群,它应该重放所有日志条目以追赶当前状态。在长时间运行的集群中,这可能需要很长时间,并且日志可能会变得非常大。
为防止这种情况,可以使用特殊的检查点机制,它将截断日志并创建当前状态的快照。
要使用此功能,只需在所需节点上调用 /cluster/recover API
POST /cluster/recover
此 API 可以在任何非 leader 节点上触发,它将向当前一致性 leader 发送请求以创建快照。leader 会将快照发送回请求节点进行应用。
在某些情况下,此 API 可用于通过强制创建快照来从不一致的集群状态中恢复。