介绍
向量数据库是一种相对较新的方式,用于与来自不透明机器学习模型(如深度学习架构)派生的抽象数据表示进行交互。这些表示通常被称为向量或嵌入(embeddings),它们是用于训练机器学习模型完成诸如情感分析、语音识别、目标检测等任务的数据的压缩版本。
这些新数据库在许多应用中表现出色,例如语义搜索和推荐系统,在这里,我们将学习市场上最受欢迎且增长最快的向量数据库之一:Qdrant。
什么是 Qdrant?
Qdrant “是一个向量相似度搜索引擎,提供了一个生产就绪的服务,带有方便的 API,用于存储、搜索和管理带额外载荷(payload)的点(即向量)。” 你可以将载荷视为附加信息,这些信息可以帮助你精确搜索,并接收可提供给用户的有用信息。
你可以通过使用 Python 的 qdrant-client 库开始使用 Qdrant,或者拉取最新的 qdrant Docker 镜像并在本地连接,或者尝试使用Qdrant Cloud 的免费层选项,直到你准备好完全切换为止。
言归正传,让我们谈谈什么是向量数据库。
什么是向量数据库?
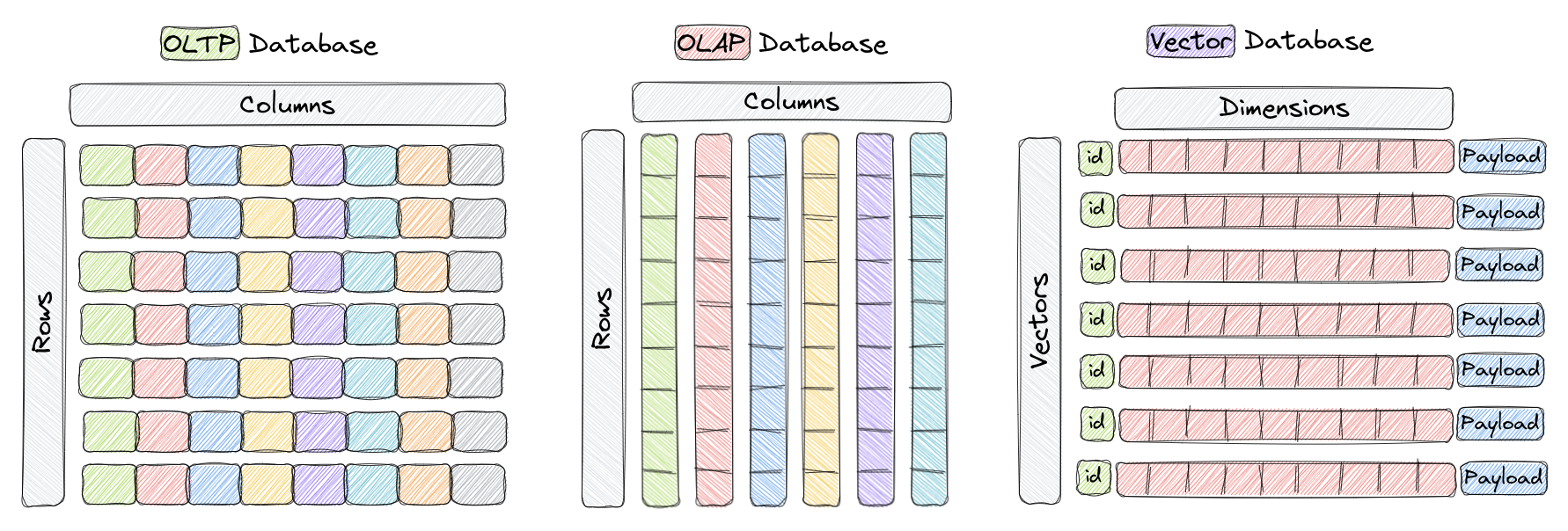
向量数据库是一种旨在高效存储和查询高维向量的数据库。在传统的OLTP和OLAP数据库中(如上图所示),数据以行和列(称为表)组织,查询基于这些列中的值执行。然而,在某些应用中,包括图像识别、自然语言处理和推荐系统,数据通常表示为高维空间中的向量,这些向量,加上一个 ID 和一个载荷,是我们存储在向量数据库(如 Qdrant)中称为集合 (Collection) 的元素。
在此情境下,向量是对对象或数据点的数学表示,向量的元素隐含或明确地对应于对象的特定特征或属性。例如,在图像识别系统中,向量可以表示图像,向量的每个元素可以表示一个像素值或该像素的描述符/特征。在音乐推荐系统中,每个向量可以表示一首歌,向量的元素会捕获歌曲的特征,如节奏、流派、歌词等。
向量数据库针对高效存储和查询这些高维向量进行了优化,它们经常使用专门的数据结构和索引技术,例如分层可导航小世界(HNSW)——用于实现近似最近邻搜索——以及乘积量化等。这些数据库在实现快速相似度和语义搜索的同时,允许用户根据某个距离度量找到最接近给定查询向量的向量。最常用的距离度量是欧氏距离、余弦相似度和点积,Qdrant 完全支持这三种。
以下是这三种度量的快速概述
- 余弦相似度 - 余弦相似度是衡量两个向量相似程度的一种方法。简单来说,它反映了向量的方向是否相同(相似)或完全相反。余弦相似度常用于文本表示,以比较两份文档或句子之间的相似程度。余弦相似度的输出范围从 -1 到 1,其中 -1 表示两个向量完全不相似,1 表示最大相似度。
- 点积 - 点积相似度是衡量两个向量相似程度的另一种方法。与余弦相似度不同,它也考虑了向量的长度。这在某些情况下可能很重要,例如当文档的向量表示基于词(单词)频率构建时。点积相似度通过将两个向量中对应位置的值相乘然后求和来计算。总和越大,两个向量越相似。如果对向量进行归一化(使其数值总和为 1),点积相似度将变为余弦相似度。
- 欧氏距离 - 欧氏距离是衡量空间中两点之间距离的一种方法,类似于我们测量地图上两地之间的距离。它的计算方法是找出两点坐标平方差的总和的平方根。这种距离度量也常用于机器学习中,以衡量两个向量的相似或不相似程度。
现在我们了解了什么是向量数据库以及它们在结构上与传统数据库有何不同,接下来让我们看看它们为何重要。
为什么我们需要向量数据库?
向量数据库在需要相似度搜索的各种应用中扮演着至关重要的角色,例如推荐系统、基于内容的图像检索和个性化搜索。通过利用其高效的索引和搜索技术,向量数据库能够更快、更准确地检索已表示为向量的非结构化数据,这有助于向用户呈现与其查询最相关的结果。
此外,使用向量数据库的其他好处包括:
- 高效存储和索引高维数据。
- 能够处理包含数十亿数据点的大规模数据集。
- 支持实时分析和查询。
- 能够处理来自复杂数据类型(如图像、视频和自然语言文本)的向量。
- 提高机器学习和人工智能应用的性能并降低延迟。
- 与构建定制解决方案相比,缩短开发和部署时间并降低成本。
请记住,使用向量数据库的具体好处可能因贵组织的用例以及您最终选择的数据库的功能而异。
现在,让我们从高层次评估 Qdrant 的架构方式。
Qdrant 架构的高层概述
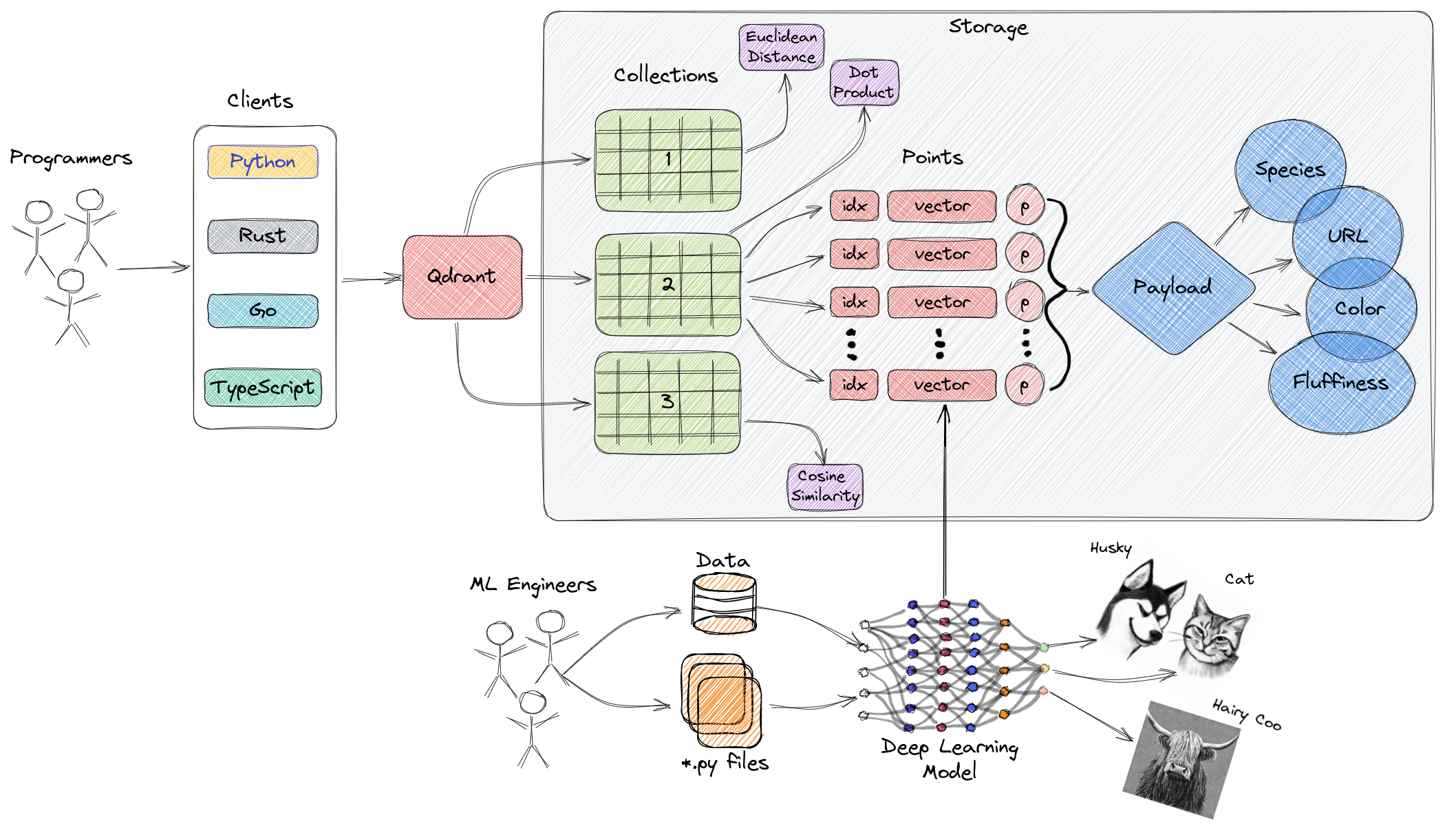
上图是 Qdrant 一些主要组件的高层概述。以下是你应该熟悉的一些术语。
- 集合 (Collections):集合是一组命名的点(带载荷的向量),你可以在其中进行搜索。同一集合中每个点的向量必须具有相同的维度,并使用单一指标进行比较。命名向量 (Named vectors) 可用于在一个点中包含多个向量,每个向量都可以有自己的维度和指标要求。
- 距离度量 (Distance Metrics):用于衡量向量之间的相似度,必须在创建集合时同时选择。度量的选择取决于向量的获取方式,特别是将用于编码新查询的神经网络。
- 点 (Points):点是 Qdrant 操作的核心实体,它们包含一个向量以及可选的 ID 和载荷。
- ID: 你的向量的唯一标识符。
- 向量: 数据的高维表示,例如,一张图像、一段声音、一份文档、一段视频等。
- 载荷 (Payload):载荷是一个 JSON 对象,包含你可以添加到向量的额外数据。
- 存储 (Storage):Qdrant 可以使用两种存储选项之一:内存存储 (In-memory)(将所有向量存储在 RAM 中,速度最快,因为仅在持久化时才需要磁盘访问),或内存映射存储 (Memmap)(创建与磁盘文件关联的虚拟地址空间)。
- 客户端 (Clients):你可以用来连接到 Qdrant 的编程语言。
后续步骤
现在你对向量数据库和 Qdrant 有了更多了解,你已经准备好开始我们的一个教程了。如果你从未用过向量数据库,请直接跳到入门部分。反之,如果你是这些技术的资深开发者,请跳到与你的用例最相关的部分。
当你学习教程时,如果有任何问题,请在我们的Discord 频道中告诉我们。😎