向量搜索在 Qdrant 中是如何工作的?
如果您仍在努力理解向量搜索的工作原理,请继续阅读。本文档描述了向量搜索的用途,涵盖了 Qdrant 在更大生态系统中的位置,并概述了如何使用 Qdrant 来增强您现有的项目。
对于那些想立即开始编写代码的人,请访问我们的新手入门教程,以便在 5-15 分钟内构建一个搜索引擎。
搜索简史
人类记忆不可靠。因此,只要我们试图以书面形式收集“知识”,我们就必须找出如何搜索相关内容而无需重复阅读同一本书。这就是为什么一些杰出人才引入了倒排索引。最简单的形式是书的附录,通常放在书末,列出基本术语及其出现的页码链接。术语按字母顺序排列。过去,这是一份需要大量人工制作的清单。数字化开始后,它变得容易得多,但我们仍然保留了相同的基本原则。这曾经有效,现在仍然有效。
如果您正在特定书籍中寻找特定主题,您可以尝试找到相关短语并快速转到正确的页面。当然,前提是您知道正确的术语。如果您不知道,您必须尝试并失败几次,或者找人帮助您构建正确的查询。

倒排索引的简化版本。
时光流逝,这个领域很长一段时间没有太大变化。但我们的文本数据收集开始以更快的速度增长。因此,我们也开始围绕这些倒排索引构建许多流程。例如,我们允许用户提供许多单词并开始将它们分解成碎片。这使得找到一些不一定包含所有查询词但可能包含其中一部分的文档成为可能。我们还开始将单词转换为其词根形式以涵盖更多情况,删除停用词等。实际上,我们变得越来越用户友好。尽管如此,整个过程背后的想法仍然源于中世纪以来已知最直接的基于关键词的搜索,并做了一些调整。
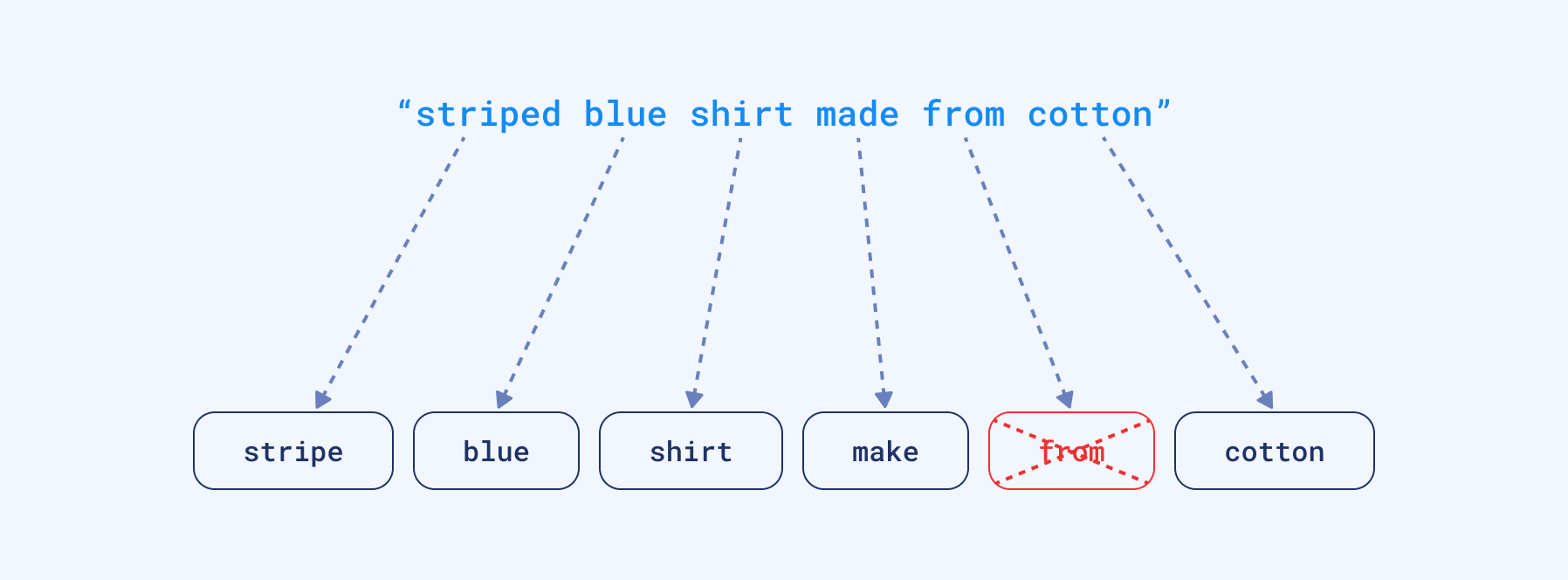
分词过程,包括额外的停用词去除和词根形式转换。
从技术上讲,我们将文档和查询编码成所谓的稀疏向量,其中每个位置对应于整个词典中的一个单词。如果输入文本包含特定单词,则在该位置获得非零值。但实际上,没有任何文本会包含超过数百个不同的单词。因此,大多数向量将包含数千个零和少量非零值。这就是为什么我们称它们为稀疏向量。它们可能已经被用于通过查找具有最大重叠的文档来计算基于词的相似度。
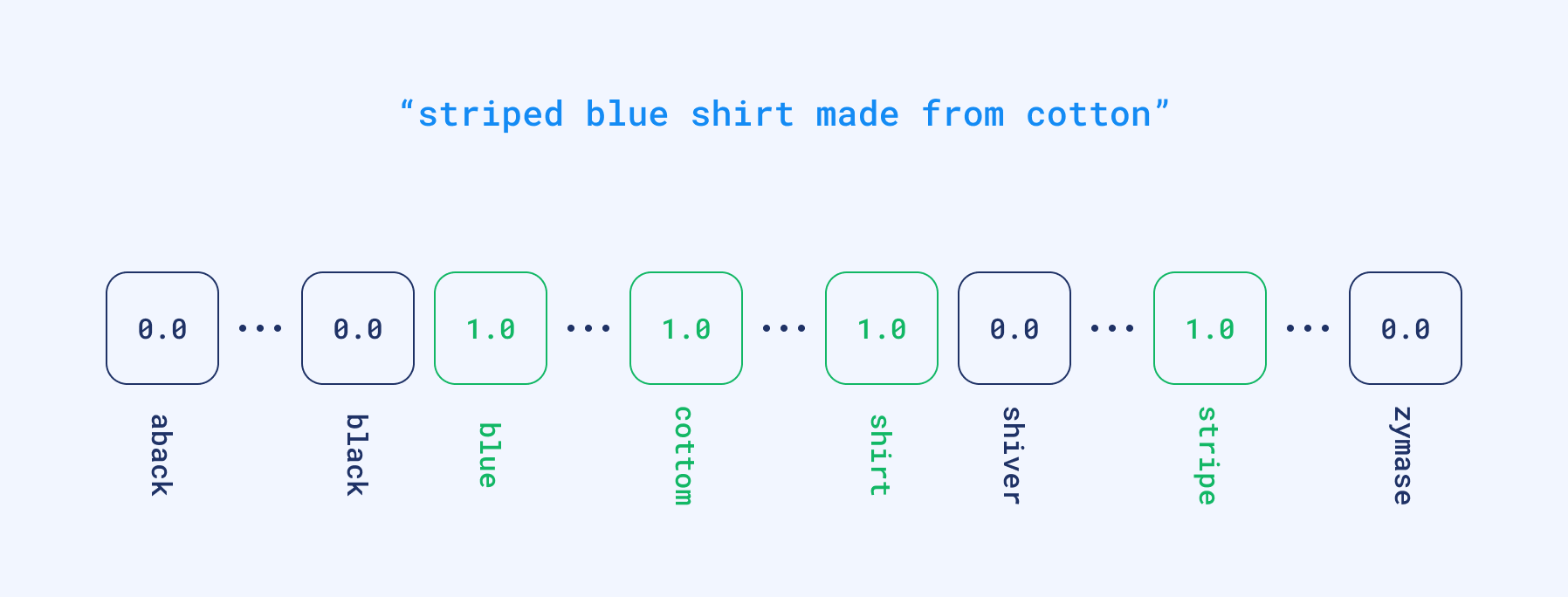
将查询向量化为稀疏格式的示例。
稀疏向量具有相对高维度;维度等于词典的大小。词典是根据输入数据自动获得的。因此,如果我们有一个向量,我们就能够部分重构创建该向量的文本中使用的词语。
巴别塔
每隔一段时间,当我们发现倒排索引的新问题时,我们就会提出新的启发式方法来解决它,至少在一定程度上。一旦我们意识到人们可能会用不同的词语描述同一个概念,我们就开始构建同义词列表,将查询转换为标准化形式。但这对于我们没有预见到的情况不起作用。而且,我们仍然需要手动制作和维护词典,以便它们能够支持随时间变化的语言。多语言场景带来了另一个难题。旧方法需要设置独立的流程并让人工参与以保持质量。

巴别塔,老彼得·勃鲁盖尔绘。
表征革命
自然语言处理 (NLP) 机器学习的最新研究重点在于训练深度语言模型。在这个过程中,神经网络将大量文本语料库作为输入,并创建词语的数学表示形式,即向量。这些向量的创建方式使得含义相似且出现在相似语境中的词语被分组在一起,并由相似的向量表示。我们还可以例如取所有词向量的平均值来创建整个文本(例如查询、句子或段落)的向量。
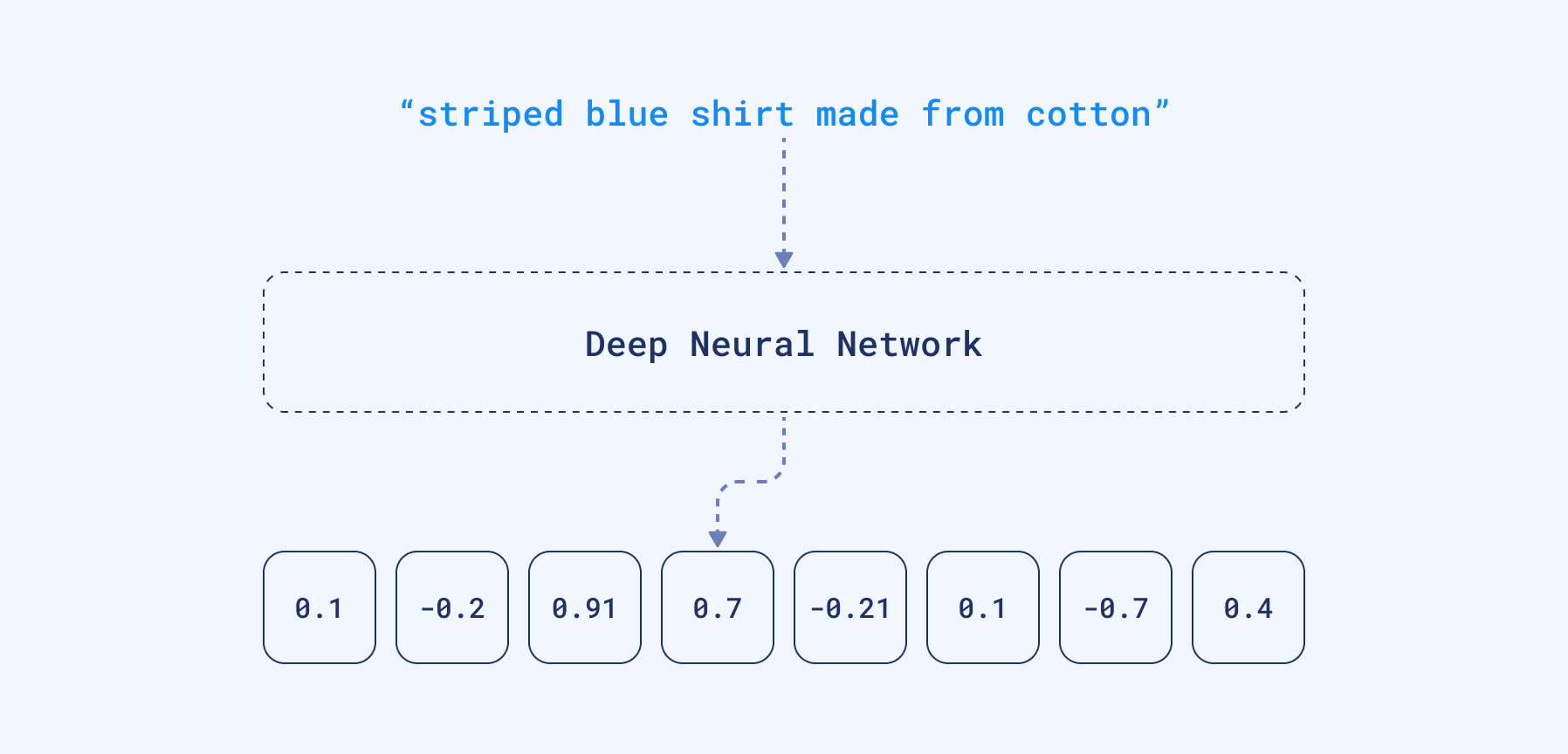
我们可以获取网络产生的密集向量,并将其用作不同的数据表示。它们是密集的,因为神经网络很少在任何位置产生零。与稀疏向量相反,它们的维度相对较低——只有几百到几千。不幸的是,如果我们想通过查看向量来查看和理解文档的内容,这已经不再可能。维度不再代表特定词语的存在。
密集向量可以捕捉含义,而不是文本中使用的词语。也就是说,大型语言模型可以自动处理同义词。更重要的是,由于这些神经网络可能使用多语言语料库进行训练,它们可以将用不同语言编写的同一句话翻译成相似的向量表示,这也称为嵌入。我们可以通过计算与数据库中其他向量的距离来比较它们,从而找到相似的文本片段。

输入查询包含不同的词语,但它们仍然被转换为相似的向量表示,因为神经编码器可以捕捉句子的含义。这个特性不仅可以捕捉同义词,还可以处理不同的语言。
向量搜索是根据嵌入相似度查找相似对象的过程。好消息是,您不必自己设计和训练神经网络。许多预训练模型是可用的,可以在 HuggingFace 上找到,或者使用像 SentenceTransformers 这样的库。然而,如果您不想亲自动手处理神经网络模型,您也可以使用 SaaS 工具创建嵌入,例如 co.embed API。
为什么选择 Qdrant?
向量搜索的挑战在于,当我们需要在一个大型对象集合中查找相似文档时。如果我们要查找最相似的示例,朴素的方法需要计算与每个文档的距离。这对于几十个甚至几百个示例可能有效,但如果数量更多,就可能成为瓶颈。处理关系数据时,我们设置数据库索引来加快速度并避免全表扫描。向量搜索也是如此。Qdrant 是一个功能完备的向量数据库,它通过使用图状结构以次线性时间查找最相似的对象来加速搜索过程。因此,您无需计算与数据库中每个对象的距离,而只需计算与部分候选对象的距离。
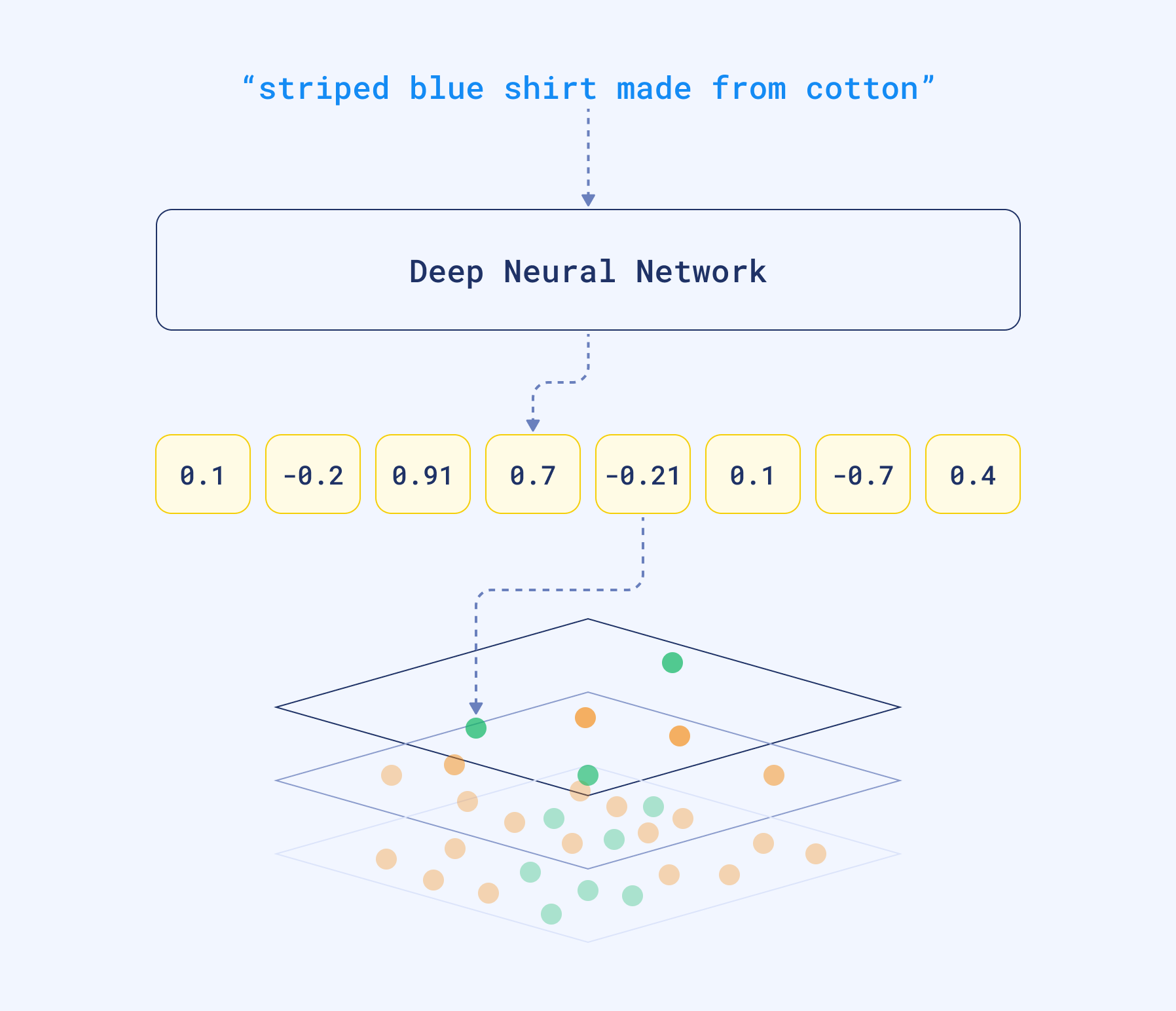
使用 Qdrant 进行向量搜索。得益于 HNSW 图,我们能够比较与数据库中部分对象的距离,而不是所有对象。
在进行大规模语义搜索时,因为这有时被称为对文本进行的向量搜索,我们需要一个专门的工具来有效地完成它——一个像 Qdrant 这样的工具。
后续步骤
向量搜索是稀疏方法令人兴奋的替代方案。它解决了基于关键词搜索的问题,而无需手动维护大量启发式规则。它需要一个额外的组件,即神经编码器,将文本转换为向量。
教程 1 - Qdrant 新手入门 尽管背景复杂,但向量搜索的设置却异常简单。使用 Qdrant,您可以在五分钟内搭建并运行一个搜索引擎。我们的新手入门教程将向您展示具体步骤。
教程 2 - 问答系统 不过,您也可以选择 SaaS 工具来生成它们,从而避免构建自己的模型。如果您按照问答系统教程操作,使用 Qdrant Cloud 和 Cohere co.embed API 设置向量搜索项目会非常简单。
向量搜索还有另一个令人兴奋的优点。只要存在一个能够将您的数据类型向量化的神经网络,您就可以搜索任何类型的数据。您是否想过反向图像搜索?这也可以通过向量嵌入实现。