





























观察结果
自上次运行以来,大多数引擎都取得了进步。生活和软件都有权衡,但有些明显做得更好
Qdrant在几乎所有场景中都实现了最高的 RPS 和最低的延迟,无论我们选择何种精度阈值和指标。它还在其中一个数据集上显示了 4 倍的 RPS 增益。Elasticsearch在许多情况下变得相当快,但在索引时间方面非常慢。存储 10M+ 96 维向量时,它可能会慢 10 倍!(32 分钟 vs 5.5 小时)Milvus在索引时间方面是最快的,并保持了良好的精度。但是,当您拥有更高维度的嵌入或更多向量时,它在 RPS 或延迟方面与其他人不相上下。Redis能够实现良好的 RPS,但主要用于较低精度。它还在单线程下实现了低延迟,但随着并行请求的增加,其延迟迅速上升。这种速度增益部分来自其自定义协议。Weaviate自上次运行以来改进最少。
如何阅读结果
- 选择您要检查的数据集和指标。
- 选择一个适合您用例的精度阈值。这很重要,因为 ANN 搜索的本质是用精度换取速度。这意味着在任何向量搜索基准测试中,只有在具有相似精度时才能比较两个结果。然而,大多数基准测试都忽略了这一关键方面。
- 表格按所选指标(RPS / 延迟 / P95 延迟 / 索引时间)的值排序,第一个条目始终是该类别的赢家 🏆
延迟 vs RPS
在我们的基准测试中,我们测试了实际中出现的两种主要搜索使用场景。
- 每秒请求数 (RPS):以单个请求耗时更长(即更高延迟)为代价,提供更多每秒请求。这是 Web 应用程序的典型场景,其中多个用户同时进行搜索。为了模拟此场景,我们使用多个线程并行运行客户端请求,并测量引擎每秒可以处理多少请求。
- 延迟:快速响应单个请求,而不是并行处理更多请求。这是服务器响应时间至关重要的应用程序的典型场景。自动驾驶汽车、制造机器人和其他实时系统是此类应用程序的良好示例。为了模拟此场景,我们以单线程运行客户端并测量每个请求所需的时间。
测试数据集
我们的基准测试工具的灵感来自github.com/erikbern/ann-benchmarks。我们使用以下数据集来测试引擎在 ANN 搜索任务上的性能
| 数据集 | 向量数 | 维度 | 距离 |
|---|---|---|---|
| dbpedia-openai-1M-angular | 100 万 | 1536 | 余弦 |
| deep-image-96-angular | 1000 万 | 96 | 余弦 |
| gist-960-euclidean | 100 万 | 960 | 欧几里得 |
| glove-100-angular | 120 万 | 100 | 余弦 |
设置
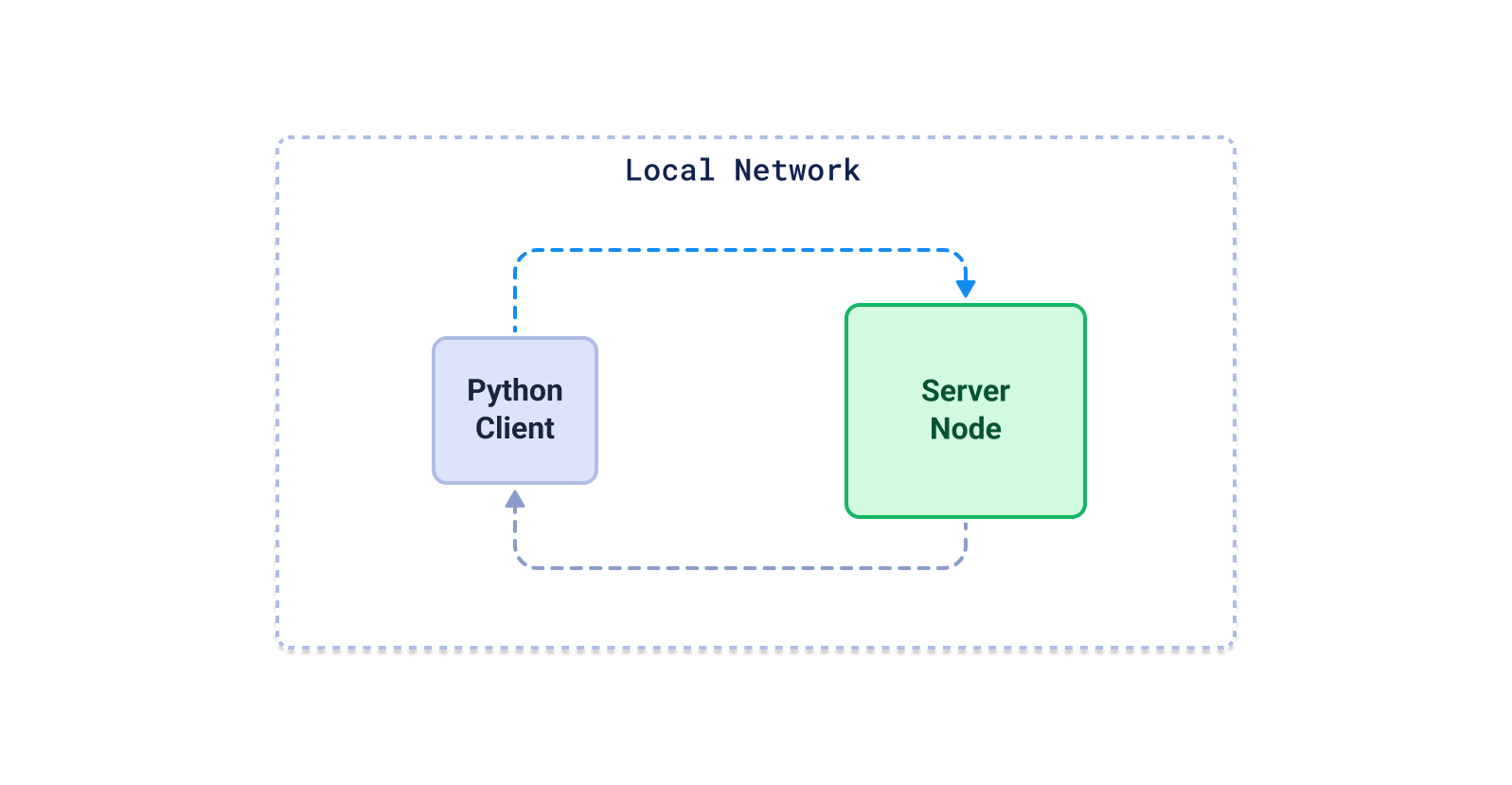
基准配置
- 这是我们本次实验的设置
- 客户端:8 个 vCPU,16 GiB 内存,64 GiB 存储(Azure 云上的
Standard D8ls v5) - 服务器:8 个 vCPU,32 GiB 内存,64 GiB 存储(Azure 云上的
Standard D8s v3)
- 客户端:8 个 vCPU,16 GiB 内存,64 GiB 存储(Azure 云上的
- Python 客户端将数据上传到服务器,等待所有必需的索引构建完成,然后以配置的线程数执行搜索。我们为每个引擎重复此过程,使用不同的配置,然后为给定精度选择最佳配置。
- 我们在 docker 中运行所有引擎,并将其内存限制为 25GB。这是为了通过避免某些引擎配置对 RAM 使用过于贪婪的情况来确保公平性。这个 25 GB 的限制是完全公平的,因为即使要服务最大的
dbpedia-openai-1M-1536-angular数据集,也很难需要1M * 1536 * 4字节 * 1.5 = 8.6GB的 RAM(包括向量 + 索引)。因此,我们决定为所有引擎提供约 3 倍于需求量的 RAM。
请注意,由于 25 GB 内存限制,某些引擎的某些配置在某些数据集上崩溃了。这就是为什么您在选择更高精度阈值时可能会看到某些引擎的点数较少。