GraphRAG:Lettria 如何通过 Qdrant 和 Neo4j 将准确率提高 20%
Daniel Azoulai
·2025 年 6 月 17 日

规模化向量与图检索:Lettria 如何通过 Qdrant 和 Neo4j 将准确率提高 20%

为什么复杂的文档智能不仅仅需要向量搜索
在精度、可审计性和准确性至关重要的受监管行业中,有效利用大型语言模型 (LLM) 通常需要超越传统的检索增强生成 (RAG)。 Lettria 是一家在文档智能平台领域处于领先地位的公司,它认识到复杂的、高度受监管的数据集,如医药研究、法律合规和航空航天文档,需要比仅基于向量的 RAG 系统更高的准确性和更可解释的输出。为了达到预期的性能水平,团队致力于构建一个非常强大的文档解析引擎,该引擎专为复杂的 PDF(包含表格、图表等)设计,并提供自动本体构建器和涵盖向量及图富集的摄取管道。
通过将 Qdrant 的向量搜索功能与 Neo4j 支持的知识图谱相结合,Lettria 创建了一个混合图 RAG 系统,显著提高了准确性并丰富了提供给 LLM 的上下文。本案例研究探讨了 Lettria 的创新解决方案、克服的技术挑战以及取得的可衡量成果。
为什么传统 RAG 在高风险用例中表现不佳
受监管行业的企业处理大量复杂的文档,其中包含结构化和半结构化数据,例如复杂的表格、多层图表和专业术语。标准向量搜索方法实现了约 70% 的准确率,这对于精度不可协商的行业来说是不足的。此外,理解和审计基于复杂文档的 LLM 输出带来了巨大的障碍。
为什么 Qdrant 作为向量数据库脱颖而出
构建中的一个组件是向量数据库。Lettria 根据 Weaviate、Milvus 和 Qdrant 的混合搜索能力、部署简易性(Docker、Kubernetes)和搜索性能(延迟、RAM 使用情况)对它们进行了评估。
最终,Lettria 选择了 Qdrant。首先,它具有简单的 Kubernetes 部署,在竞争性基准测试中具有卓越的延迟和更低的内存占用。此外,Qdrant 还具有独特的功能,例如分组 API 和详细的有效载荷索引,这些都使 Qdrant 脱颖而出。
构建文档理解和提取管道
Lettria 高精度解决方案的核心在于将向量嵌入(存储在 Qdrant 中)与基于图的语义理解(Neo4j)相结合。以下是其管道的概述:
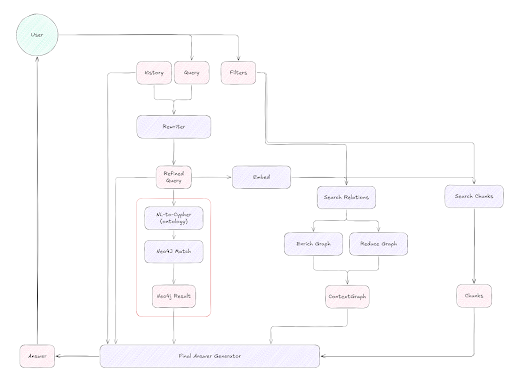
- 摄取:解析复杂的 PDF,并将数据转换为双重表示形式:密集向量嵌入和语义三元组(存储在 Neo4j 中并索引在 Qdrant 中)。如下图所示,摄取管道提取布局和内容结构,将文本分成有意义的块,并将其路由到向量和图表示形式。每个块都保留沿袭元数据,将其链接回其在源文档中的确切位置——这对于可追溯性至关重要。
![]()
图:摄取事务机制
本体生成:Lettria 使用 LLM 自动生成本体,确保可扩展性和适应性。此步骤确保只提取语义上有意义的关系——减少噪声并实现下游的结构化查询。
向量驱动的图扩展:查询从 Qdrant 中的快速向量搜索开始,将节点和关系识别为文本嵌入。然后,这些种子点用于在 Neo4j 中扩展一个上下文子图,该子图与块数据相结合并传递给 LLM 以生成答案。
摄取事务机制:保持 Neo4j 和 Qdrant 同步
保持 Qdrant 和 Neo4j 同步是一项挑战,因为它们对数据操作采用了根本不同的方法。Neo4j 是一个事务型数据库,这意味着它可以将更改分组为原子单元,这些单元要么完全提交,要么完全回滚。相比之下,Qdrant 是一个向量搜索引擎,旨在立即处理每次更新,而不具备事务语义。这种区别很重要:事务支持是数据库的典型特征,而像 Qdrant 这样的搜索引擎则优先考虑低延迟的摄取和检索,而非回滚功能。
这种根本性的不匹配带来了复杂性。因此,如果在数据已经写入 Qdrant 之后,Neo4j 中的事务失败,那么两个数据库可能会迅速失去一致性。
为确保 Qdrant(非事务性)和 Neo4j(事务性)之间的数据原子性,Lettria 构建了一个自定义的摄取机制,以保证两个系统之间的一致写入。该过程首先在 Neo4j 中将写入作为事务批处理进行准备——如果 Neo4j 接受更改,则将其提交并保存。在更新 Qdrant 之前,会为每个受影响的点拍摄一个快照。然后,乐观地更新 Qdrant。如果 Neo4j 提交成功,则操作完成。但如果失败,Lettria 的系统将使用之前的快照来回滚 Qdrant 到其先前的状态,确保两个数据库中都没有留下部分写入。
挑战出现在并发环境中,多个摄取过程可能会与相同的数据点交互。为了解决这个问题,Lettria 实现了一个冲突解决函数,该函数比较每个点的三种状态:原始快照、当前过程提议的更改以及 Qdrant 中的当前状态。如果检测到冲突(例如,另一个过程同时修改了该点),解析器会智能地合并更改,以保留有效的更新,同时仅回滚失败的批处理。此策略与小批量大小相结合,最大程度地减少了风险窗口,并确保即使在大规模下也具有高可靠性。
伪代码示例:ingest_graph_attempt
def ing est_graph_attempt(graph_data, qdrant, neo4j):
"""
Attempts to ingest graph data into Qdrant and Neo4j consistently.
If Neo4j write fails, Qdrant changes are rolled back.
This mimics a "try Qdrant, then try Neo4j; if Neo4j fails, undo Qdrant" strategy.
"""
BEGIN_TRANSACTION
neo4j.begin_transaction()
points = graph_data.get_triplets()
# Merge points in Neo4j (non blocking)
neo4j.upsert(points)
# Load current points from Qdrant
snapshot = qdrant.get([point.id for point in points])
# Update points in Qdrant
qdrant.upsert(points)
neo4j.commit()
TRANSACTION_ROLLBACK
# Load current points state
current_points = qdrant.get([point.id for point in points])
# Build snapshot of the current state
resolved_snapshot = resolve_conflicts(points, current_points, snapshot)
# Rollback Qdrant changes
qdrant.upsert(resolved_snapshot)
TRANSACTION_SUCCESS
total_points = len(points)
added_points, updated_points = diff(points, snapshot)
Log(f"Successfully ingested {total_points} points into Qdrant and Neo4j.")
Log(f"Added {added_points} points and updated {updated_points} points.")
通过有效载荷扁平化实现一致的查询和索引
为了确保 Qdrant 和 Neo4j 之间一致的查询行为和索引性能,Lettria 采用了有效载荷扁平化策略。虽然 Qdrant 在其有效载荷中支持嵌套的 JSON 样结构,但 Neo4j 要求节点和关系上的属性为扁平的键值对。这种结构不匹配使得难以在两个数据库中应用一致的过滤器或索引逻辑。Lettria 通过在摄取过程中扁平化所有嵌套字段来解决此问题——例如,将 { "author": { "name": "Jane" } } 转换为 { "author_name": "Jane" }。这种方法允许在 Neo4j 中无缝重用相同的元数据结构,从而简化了混合搜索并强制执行了双数据库架构的模式兼容性。
扩展到超过 1 亿个向量,P95 检索延迟小于 200 毫秒
Lettria 将其 Qdrant 部署扩展到超过 1 亿个向量,同时在生产环境下的负载测试中,仍能将第 95 百分位的检索延迟保持在 200 毫秒以下。这种性能得益于精心设计的有效载荷索引和不常用向量的基于磁盘的缓存集合。最初,缺少索引导致了全集合扫描,严重降低了性能。在频繁过滤的有效载荷字段(例如 doc_type、client_id、chunk_source)上添加索引后,延迟急剧下降并趋于稳定。为了进一步减少内存压力,Lettria 将热数据和冷数据分离——将活动块保留在内存中,并将不常用的向量卸载到磁盘存储中,从而在不牺牲准确性的情况下实现更精细的内存调优。这种方法在大规模下提供了速度和成本控制,支持密集和稀疏模式的混合检索,而无需过多的资源开销。
结果:准确率提高 >20%
Lettria 的图增强 RAG 系统在纯向量解决方案上实现了显著的准确性提升
- 在金融、航空航天、制药和法律等垂直领域,准确率提升 20-25%。
- 从文档摄取到查询响应的增强可解释性和沿袭跟踪。
- 客户接受的稳健、可审计级准确性,且延迟可控(每次查询 1-2 秒)。
最终,Lettria 的准确率超越了传统 RAG
作为首个可用于生产的 GraphRAG 平台,Lettria 在与传统 RAG 参与者的竞争中脱颖而出。GraphRAG 使得创建代理变得更加容易,帮助 Lettria 快速构建新的文档智能功能(例如,多文档之间的差距分析)。这使得他们在需要高准确性的行业中获得了高价值合同,并通过透明、可审计的输出提高了客户信任。
“Qdrant 已成为我们 GenAI 基础设施的关键组成部分。它提供了我们所需的性能、灵活性和可靠性,以构建航空航天、金融和制药领域客户的生产级 GraphRAG 系统——在这些领域,准确性是不可或缺的。”
— Jérémie Basso,Lettria 工程主管
延伸阅读
摄取事务机制
Lettria 必须保持 Neo4J 和 Qdrant 中数据的一致性。推理 (RAG) 管道使用 Qdrant 进行向量和有效载荷搜索,然后回退到 Neo4J 从图结构中收集相关三元组。如果某些点未能插入 Neo4J 但存在于 Qdrant 集合中,则最终的输出图将不一致。
为了防止这种情况,Lettria 使用了一种事务机制,其中 Neo4J 提交作为整体成功的最终关卡。该机制设计为幂等且对并发摄取场景安全。
事务机制
ingest_graph_attempt 伪代码中概述的过程可总结如下:
Neo4J 事务和试探性写入:
- 显式 Neo4J 事务开始 (neo4j.begin_transaction())。
- 在此事务中准备数据并将其 upsert 到 Neo4J (neo4j.upsert(points))。这些更改尚未永久生效。
Qdrant 快照与更新:
- 在更改 Qdrant 之前,会拍摄相关点的当前状态快照 (qdrant.get(…))。
- 然后使用新数据更新 Qdrant (qdrant.upsert(points))。
Neo4J 提交(决定点):
- 系统尝试提交 Neo4J 事务 (neo4j.commit())。
成功时 (TRANSACTION_SUCCESS): Neo4J 更改是永久性的。Qdrant 已更新,因此两个系统一致。
失败时 (TRANSACTION_ROLLBACK):
- Neo4J 自动回滚其待定更改。
- 为了恢复一致性,Qdrant 被回滚。
Qdrant 回滚
当 Neo4j 提交失败且需要回滚 Qdrant 时,由于并发操作,简单地恢复到快照可能不足或不正确。另一个摄取过程可能在当前(失败)事务拍摄快照之后但在当前事务尝试回滚之前成功更新了 Qdrant 中的一些相同点。
resolve_conflicts 函数旨在就回滚后 Qdrant 中每个点的状态做出智能决策。它考虑了每个相关点的三种状态:
- 快照:当前更新前点的状态
- 点:当前状态的更新
- current_points:Qdrant 中点的当前状态
这是一个最小示例:
snapshot = {
"id": "my_point_id_123",
"name": "my_point", # Original name
"foo": "bar" # Original foo
}
point = {
"id": "my_point_id_123",
"name": "my_point_v2", # Our transaction intended to change the name
"bar": "baz" # Our transaction intended to add a new key "bar"
}
current = {
"id": "my_point_id_123",
"name": "my_point_v2", # Matches our intended name change (our change "stuck" so far)
"foo": "qux", # another transaction changed this!
"bar": "baz", # Matches our intended new key "bar"
"baz": "quux" # NEW key - another transaction added this!
}
resolved = {
"id": "my_point_id_123",
"name": "my_point", # Reverted: Our transaction changed this, so undo.
"foo": "qux", # Preserved: Another transaction changed this, respect it.
"baz": "quux" # Preserved: Another transaction added this, respect it.
# bar is Removed: Our transaction added this, so undo by removing.
}
伪代码示例
def ingest_graph_attempt(graph_data, qdrant, neo4j):
"""
Attempts to ingest graph data into Qdrant and Neo4j consistently.
If Neo4j write fails, Qdrant changes are rolled back.
This mimics a "try Qdrant, then try Neo4j; if Neo4j fails, undo Qdrant" strategy.
"""
BEGIN_TRANSACTION
neo4j.begin_transaction()
points = graph_data.get_triplets()
# Merge points in Neo4j (non blocking)
neo4j.upsert(points)
# Load current points from Qdrant
snapshot = qdrant.get([point.id for point in points])
# Update points in Qdrant
qdrant.upsert(points)
neo4j.commit()
TRANSACTION_ROLLBACK
# Load current points state
current_points = qdrant.get([point.id for point in points])
# Build snapshot of the current state
resolved_snapshot = resolve_conflicts(points, current_points, snapshot)
# Rollback Qdrant changes
qdrant.upsert(resolved_snapshot)
TRANSACTION_SUCCESS
total_points = len(points)
added_points, updated_points = diff(points, snapshot)
Log(f"Successfully ingested {total_points} points into Qdrant and Neo4j.")
Log(f"Added {added_points} points and updated {updated_points} points.")
已知限制
如果 Lettria 的更改与另一个事务完全相同,它可能会撤销该事务的更改。在 Qdrant 回滚过程中,存在一个非常短暂的脆弱窗口。它发生在 Lettria 读取当前 Qdrant 点(以决定如何回滚)之后,但在它执行实际的回滚 upsert (qdrant.upsert(resolved_snapshot)) 之前。如果另一个并发事务在此微小窗口内成功更新了 Qdrant 中的一个点,则其后续的回滚操作可能会无意中覆盖该最近的合法更新。
缓解措施 – 小批次迭代
- 他们通过小批量迭代处理数据摄取(以及任何潜在的回滚)来降低这种风险。
- 通过这样做,获取 current_qdrant_point 到对任何给定点执行回滚 upsert 之间的时间间隔被最小化。
- 更短的窗口显著降低了在关键的狭窄时间范围内发生冲突的并发更新到相同点的可能性。虽然不能完美保证,但它使得此类事件在统计上不太可能发生。
有效载荷扁平化
每个客户端助手都位于自己的 Qdrant 集合中。
Lettria 将每个元素的点 ID 定义为客户端生成的 UUID。这使得他们能够在 Neo4J 和 Qdrant 中保留相同的索引 ID。这些 UUID 是通过元素的字符串 ID 的哈希值生成的。
- 对于块,字符串 ID 是块的 ID,定义为源(pdf)ID、节(用于文本到图)ID 和块的顺序整数的组合。
- 对于关系,他们使用生成的 UUID6,因为每个关系都被认为是唯一的。
- 对于节点,他们使用节点 IRI(http://example.org/resource/France)和客户端助手命名空间。
def create_uuid_from_string(string_id: str, namespace: str):
"""Create uuid from string."""
hex_string = hashlib.md5(
f"{namespace}:{string_id}".encode("UTF-8"),
usedforsecurity=False
).hexdigest()
return uuid.UUID(hex=hex_string, version=4)
它还确保重新摄取相同的文档将更新块(因为 ID 将相同)。具有相同 IRI 的节点在特定助手中被视为合并。
扁平化
节点和关系保存在 Qdrant 和 Neo4J 中。节点和关系有效载荷遵循如下所示的嵌套结构:
{
"properties": {
"rdfs:label": {
"@en": "House",
"@fr": "Maison"
},
"onto:surface": 250
},
"metadata": {
"origin_ids": ["001", "002"],
"client_id": "8FKZ78"
}
}
Lettria 有两个主要级别:属性(关于对象的语义丰富信息)和元数据(系统信息)。
此外,字符串属性可能有一个额外的语言变体级别。如 Neo4J 文档所述,他们无法将嵌套属性添加到节点和关系中。因此,他们在 Neo4J 中将此类有效载荷扁平化。
{
"properties.rdfs:label": "House",
"properties.rdfs:label@en": "House",
"properties.rdfs:label@fr": "Maison",
"properties.onto:surface": 250,
"metadata.origin_ids": ["001", "002"],
"metadata.client_id": "8FKZ78"
}
请注意,他们复制了字符串属性的英语标签,因为它们被认为是默认值。语言标签未用点号扁平化,以防止在从数据库检索数据时解扁平化嵌套属性和语言变体之间的歧义。
筛选
基于过滤器定义。Lettria 将 Neo4J 上的属性扁平化,以便可以使用类似的过滤器。嵌套结构(更多信息在此){“foo”: { “bar”: “qux” }} 保留在 Qdrant 中,并在 NeoJ 中用点号分隔:foo.bar=qux,以便他们可以使用 Qdrant 中类似的键执行匹配查询。这引入了一些复杂性,因为他们需要仔细处理属性中的 URL 和其他“富点”值。
如果他们想根据 onto:surface 值进行过滤,Qdrant 和 Neo4J 中会使用相同的键。
MATCH (n:Node)
WHERE
n."properties.onto:surface" > 100
RETURN n;
POST /collections/{collection_name}/points/scroll
{
"filter": {
"should": [
{
"key": "properties.onto:surface",
"match": {
"range": {"gt": 100, "lt": null}
}
}
]
}
}
解析概念可视化
源文档
一个包含标题、文本、表格、图像和脚注的两列文档示例。

布局
他们隔离页面上的组件。

提取与结构化
他们提取每个组件的内容,并根据计算出的阅读顺序对内容进行结构化。

增强
他们删除了一些组件(脚注、页面等)并清理内容(修复编号和项目符号列表,合并多页表格,将图像文本化等)。

推理过程概述