





























Lyzr 如何利用 Qdrant 大幅提升 AI 代理性能
Daniel Azoulai
·2025 年 4 月 15 日

Lyzr 如何利用 Qdrant 大幅提升 AI 代理性能

智能代理扩展:Lyzr 如何利用 Qdrant 大幅提升性能
随着 AI 代理变得越来越强大和普及,其背后的基础设施必须不断发展,以应对日益增长的并发性、低延迟需求和不断增长的知识库。在 Lyzr 代理工作室,有超过 100 个代理部署在各个行业中,这些挑战迅速且大规模地出现。
当他们现有的向量数据库基础设施开始承受不住压力时,工程团队需要一个解决方案,它不仅能跟上,还能加速他们前进。
以下是他们如何重新思考其技术栈并采用 Qdrant 作为快速、可扩展代理性能的基础。
早期技术栈选择的扩展限制
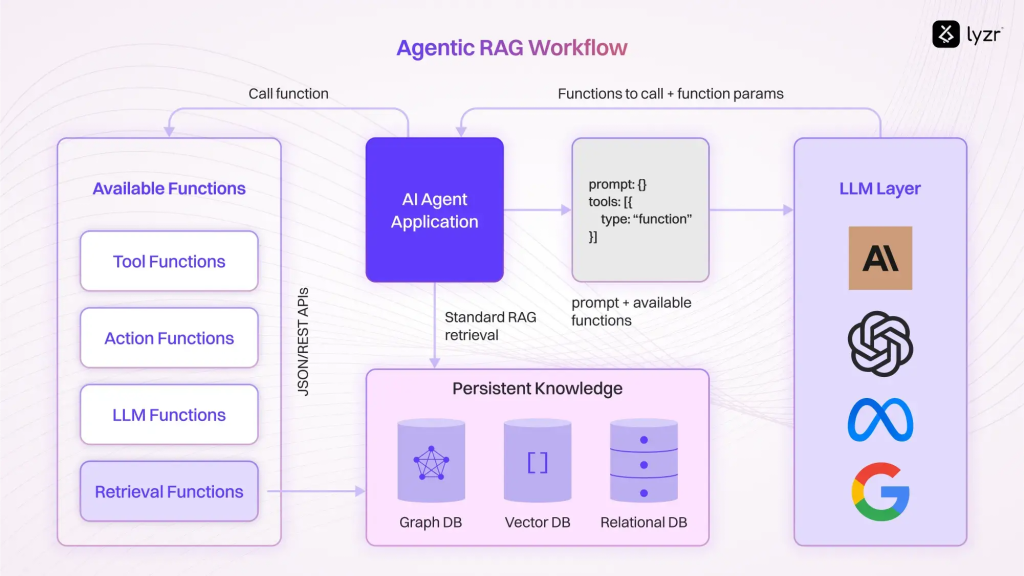
Lyzr 的架构使用了 Weaviate,并对 Pinecone 进行了额外的基准测试。最初,这种设置对于开发和受控测试来说还不错。系统管理着大约 1,500 个向量条目,少量代理以稳定的模式发出适度的查询负载。
初始设置
| 参数 | 详情 |
|---|---|
| 部署类型 | 单节点或小集群(Weaviate 和其他向量数据库) |
| 嵌入模型 | Sentence-transformer(768 维度) |
| 并发代理 | 10 到 20 个知识搜索代理 |
| 每个代理的查询速率 | 每分钟 5-10 次查询 |
| 流量模式 | 稳定,无明显高峰 |
在这些条件下,两个数据库都表现良好。查询延迟在 80 到 150 毫秒之间。索引操作在几个小时内完成。整体性能可预测且稳定。
但随着平台扩展——拥有更大的语料库、更复杂的工作流程和显著增加的并发性——这些系统开始出现故障。
增长带来延迟、超时和资源瓶颈
一旦知识库超过 2,500 个条目,并且实时代理并发量超过 100,平台就开始吃力。
查询延迟增加了近 4 倍,达到 300-500 毫秒。在高峰使用期间,代理有时会因等待向量结果而超时,这影响了下游的决策逻辑。索引操作也变慢了,消耗了过多的 CPU 和内存,并在数据更新期间造成了瓶颈。
这些问题在生产环境中造成了真正的摩擦,并明确表明需要一个更具可扩展性、更高性能的向量数据库。
替代向量数据库的评估
随着数据量和代理并发性的增长,Lyzr 需要一个更具可扩展性和效率的向量数据库。
他们需要能够处理更重负载、同时保持快速响应时间并降低运营开销的解决方案。他们根据以下标准评估了替代方案:
| 标准 | 重点领域 | 对系统的影响 |
|---|---|---|
| 可扩展性与分布式计算 | 横向扩展、集群 | 支持不断增长的数据集和高代理并发 |
| 索引性能 | 摄取速度、更新效率 | 减少停机时间并实现更快的批量数据更新 |
| 查询延迟和吞吐量 | 负载下的搜索响应 | 确保代理保持快速、实时的响应 |
| 一致性与可靠性 | 处理并发和故障 | 避免高峰使用期间的超时和查询失败 |
| 资源效率 | CPU、内存和存储使用 | 在扩展工作负载的同时优化基础设施成本 |
| 基准测试结果 | 真实世界负载模拟 | 验证在 >1,000 QPM 负载下持续性能 |
Qdrant 将查询速度提升 >90%,索引速度提高 2 倍,并降低了 30% 的基础设施成本。
这种转变是通过 Qdrant 实现的,Qdrant 迅速超越了所有关键指标的预期。
使用 Qdrant,查询延迟降至仅 20-50 毫秒,比 Weaviate 和 Pinecone 提高了 >90%。即使有数百个并发代理每分钟生成超过 1,000 个查询,性能仍然保持一致。
索引操作显著改善。大型数据集的摄取时间 快了 2 倍,系统完成这些操作所需的计算和内存资源显著减少。这使得团队能够将基础设施成本降低约 30%。
Qdrant 还表现出更高的一致性。虽然 Weaviate 和 Pinecone 在扩展时都遇到了性能下降,但 Qdrant 在每分钟 1,000+ 次查询下保持稳定,支持 100 多个并发代理,没有出现延迟峰值或速度下降。最值得注意的是,Lyzr 在分布式代理之间保持了 每秒超过 250 次查询的吞吐量,而没有影响速度或稳定性。
| 指标 | Weaviate | Pinecone | Qdrant |
|---|---|---|---|
| 100 个代理下的平均查询延迟 (ms) | 300-500 | 250-450 | 20-50 (P99) |
| 索引时间 (2,500+ 条目) | ~3 | ~2.5 | ~1.5 |
| 查询吞吐量 (QPS) | ~80 | ~100 | >250 |
| 资源利用率 (CPU/内存) | 高 | 中高 | 中低 |
| 横向可扩展性 | 中等 | 中等 | 高度可扩展 |
Qdrant 基于 HNSW 的索引允许系统处理实时更新,无需停机或重新索引,消除了之前设置中最大的摩擦源之一。
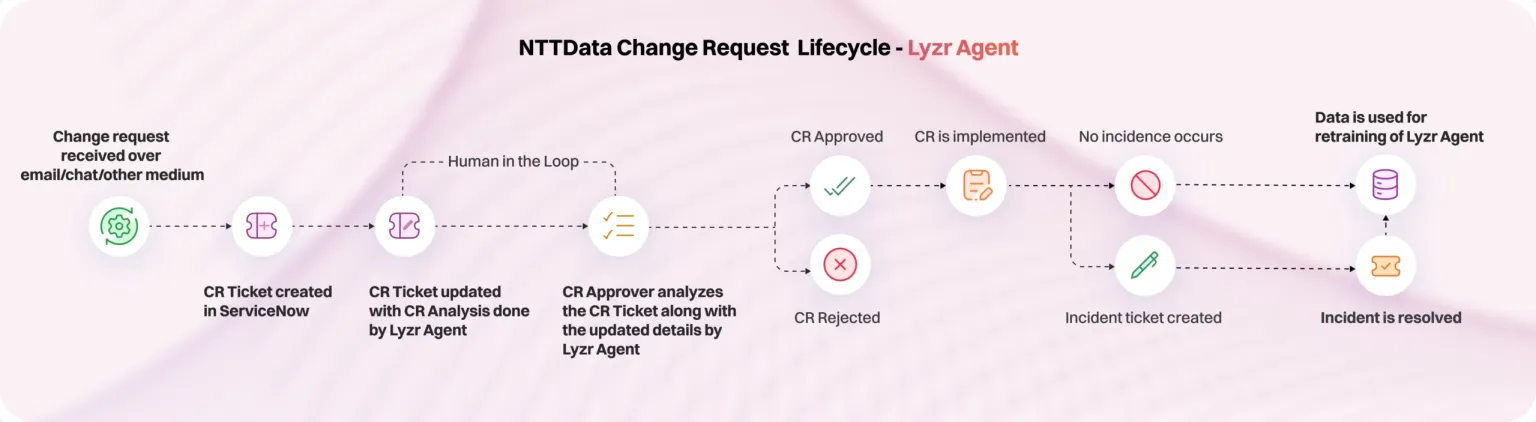
案例聚焦:NTT Data 提高检索准确性
为 NTT Data 构建的一个部署专注于自动化 IT 变更请求工作流。该代理最初在 Azure 中的 Cosmos DB 上运行。虽然集成很顺利,但向量搜索性能有限。索引精度不足,并且随着数据量的增长,系统难以显示相关结果。
迁移到 Qdrant 后,差异立竿见影。检索准确性显著提高,即使对于长尾查询也是如此。系统在并发负载下保持了高响应性,并且横向扩展变得更简单——确保随着项目需求的演变,性能保持一致。
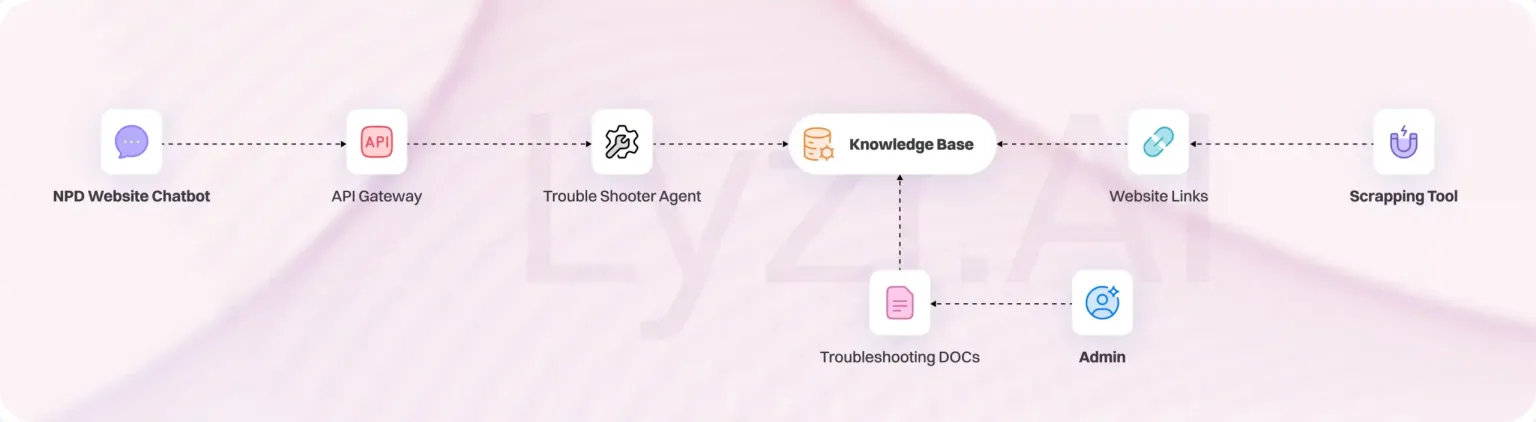
案例聚焦:NPD 支持代理实现准确、低延迟的检索
另一个例子涉及 NPD,它在六个网站上部署了面向客户的代理。这些代理的任务是回答产品问题,并根据动态的、全站范围的知识库引导用户到正确的 URL。
Qdrant 的向量搜索实现了数千个条目之间的准确、低延迟检索。即使在用户流量不断增加的情况下,平台仍能提供一致的性能,消除了以前解决方案中出现的延迟峰值。
总结
Lyzr 的经验教训很明确:生产级 AI 平台需要生产级向量数据库。
Qdrant 满足了这一要求。它使 Lyzr 能够显著降低延迟、扩展查询吞吐量、简化数据摄取并降低基础设施成本,同时在大规模部署中保持系统稳定性。
随着 AI 生态系统的发展,向量数据库的性能将越来越决定代理本身的性能。有了 Qdrant,Lyzr 获得了所需的基础设施,即使在真实世界的生产负载下,也能使其代理保持快速、智能和可靠。
想看看 Lyzr 代理工作室和 Qdrant 如何在您的技术栈中发挥作用吗?
探索 Lyzr 代理工作室 或了解更多关于 Qdrant 的信息。
