





























Mixpeek 如何使用 Qdrant 实现高效的多模态特征存储
Daniel Azoulai
·2025 年 4 月 8 日

Mixpeek 如何使用 Qdrant 实现高效的多模态特征存储

关于 Mixpeek
Mixpeek 是一个面向开发者和数据团队的多模态数据处理和检索平台。由前 MongoDB 搜索专家 Ethan Steininger 创立,Mixpeek 能够高效地摄取、提取和检索包括视频、图像、音频和文本在内的各种媒体类型。
挑战:优化复杂检索器的特征存储
随着 Mixpeek 多模态数据仓库的发展,他们的特征存储需要支持越来越复杂的检索模式。最初使用 MongoDB Atlas 的向量搜索时,他们在实现结合密集和稀疏向量与元数据预过滤的混合检索器时遇到了限制。
在实现跨视频嵌入的 ColBERT 等晚期交互技术时出现了一个关键限制,这需要多向量索引。MongoDB 的 kNN 搜索无法支持这些用于上下文理解的多向量表示。
Mixpeek 的另一个客户需要用于程序化广告投放的反向视频搜索,其中检索器需要从海量对象集合中识别高转化视频片段——这项任务用 MongoDB 的通用数据库特征存储效率低下。
“当我们用 Qdrant 替代 MongoDB 的 kNN 混合搜索作为我们的特征存储时,我们消除了数百行代码。” — Ethan Steininger,Mixpeek 创始人
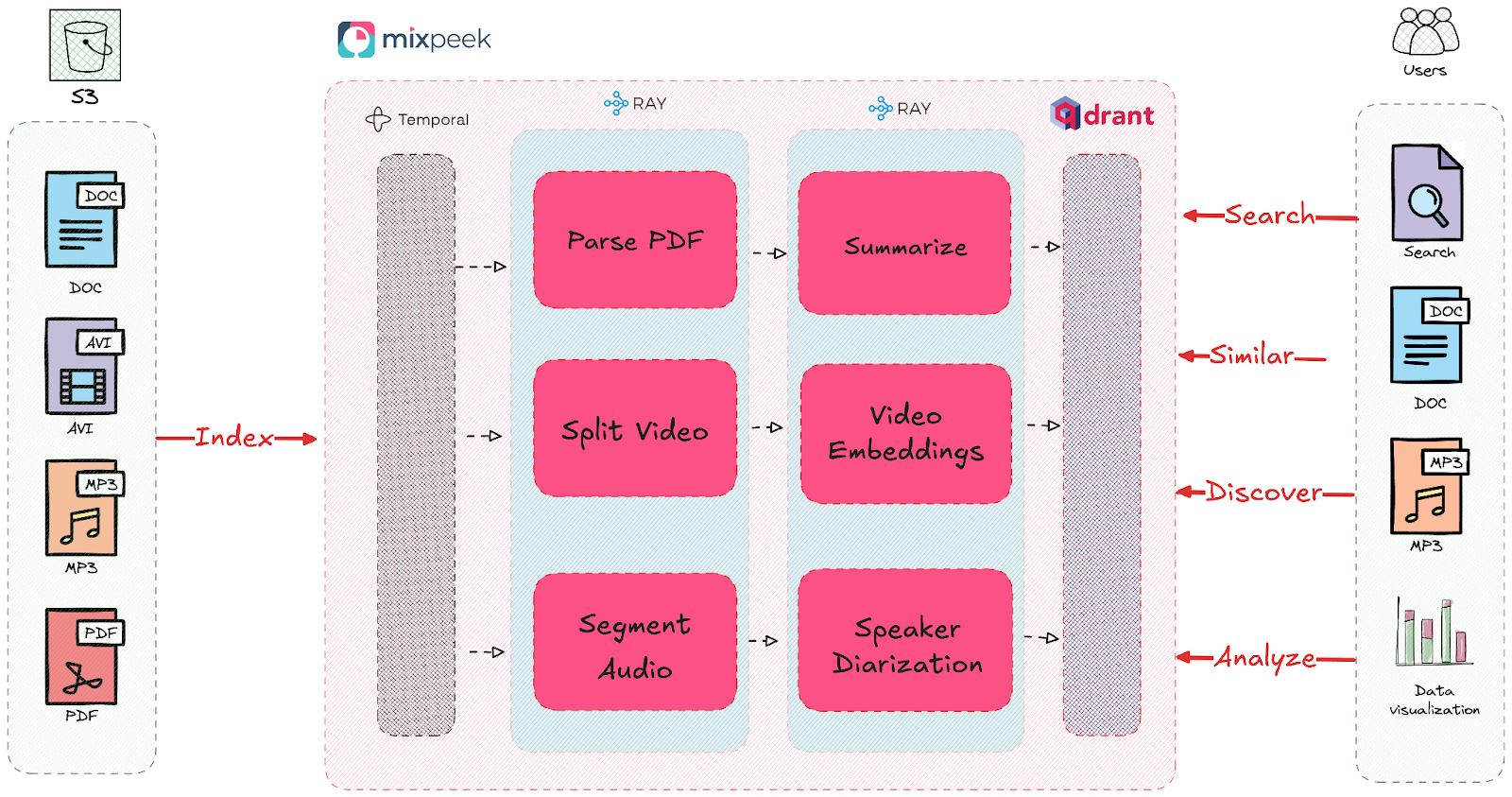
Mixpeek 为何选择 Qdrant 用于特征存储
在评估了包括 Postgres 与 pgvector 和 MongoDB 的 kNN 搜索在内的多种选项后,Mixpeek 选择 Qdrant 来支持他们的特征存储,因为它专注于向量搜索以及与他们检索管道的集成能力。Qdrant 对多向量索引的原生支持对于实现 ColBERT 等晚期交互技术至关重要,而 MongoDB 无法高效支持。
简化混合检索器
此前,Mixpeek 维护复杂的自定义逻辑来合并来自不同特征存储的结果。Qdrant 对 Reciprocal Rank Fusion (RRF) 的原生支持简化了他们的检索器实现,将混合搜索代码减少了 80%。多向量功能还支持更复杂的检索方法,更好地捕捉语义关系。
“使用我们以前的特征存储,混合检索器是具有挑战性的。使用 Qdrant,它就能正常工作。”
并行检索使查询时间缩短 40%
对于拥有数十亿特征的集合,Qdrant 的预取功能实现了跨多个特征存储的并行检索。这使检索器查询时间缩短了 40%,从约 2.5 秒降至 1.3-1.6 秒。
“Qdrant 中的预取功能使我们能够同时执行多个特征存储检索,然后组合结果,完美支持我们的检索器管道架构。”
优化 SageMaker 特征提取工作流
Mixpeek 使用 Amazon SageMaker 进行特征提取,而数据库查询是一个显著的瓶颈。通过将 Qdrant 作为其特征存储,他们将查询开销减少了 50%,从而简化了其摄取管道。
“我们正在使用 SageMaker 进行特征提取推理,而我们的特征存储查询曾经是一个显著的瓶颈。Qdrant 节省了大量时间。”
支持 Mixpeek 的分类和聚类架构
Qdrant 被证明在实现 Mixpeek 的分类和聚类功能方面特别有效。
分类法(JOIN 模拟)
Qdrant 的负载过滤有助于高效实现平面和分层分类法,通过基于相似性的“连接”跨集合实现文档丰富。
聚类(GROUP BY 模拟)
该平台的批量向量搜索功能简化了基于特征相似性的文档聚类,有效实现了传统的“group by”接口。
特征存储迁移后的可衡量改进
迁移到 Qdrant 作为 Mixpeek 的特征存储带来了显著改进
- 检索器速度提升 40%:查询时间从约 2.5 秒缩短至 1.3-1.6 秒
- 代码减少 80%:简化了检索器实现
- 提高开发者生产力:更容易实现复杂的检索模式
- 优化可扩展性:在十亿级特征规模下表现更好
- 增强多模态检索:更好地支持结合不同特征类型
未来方向:支持多样化的多模态用例
Mixpeek 的架构通过预构建与检索器管道紧密耦合的专用特征提取器而脱颖而出,从而能够高效处理多样化的多模态用例。
这种架构方法确保在摄取过程中提取的特征正是检索器高效查询所需的,消除了通常会减慢多模态系统速度的转换层。
“我们正在迈向复杂的多模态本体论,而 Qdrant 作为特征存储的专业能力将对这些高级检索策略至关重要。”
结论:多模态数据仓库的专用特征存储
Mixpeek 的旅程凸显了专用特征存储在多模态数据仓库架构中的重要性。Qdrant 对向量搜索效率的关注使其成为驱动 Mixpeek 特征存储的理想选择,从而实现更高效的检索器和摄取管道。
