





























Pento 如何用 Qdrant 模拟审美偏好
Daniel Azoulai
·2025 年 7 月 14 日


通过 Qdrant 将人们联系在一起

艺术品味不仅仅是一种偏好;它更是一种指纹。
想象一下,您是一位艺术家或艺术爱好者,寻找的不是一幅画,而是寻找与您有着独特品味的人,一个能与您一样深切地共鸣超现实主义色彩的人,或者一个能在极简线条中找到宁静乐趣的人。系统如何知道这些人是谁?传统推荐系统通常推荐流行或热门的东西,或者根本无法理解艺术的细微差别。
在这篇文章中,我们将构建一个能做到这一点的推荐系统。通过将用户与艺术品的互动映射到语义向量空间,识别偏好簇,并利用 Qdrant 强大的推荐 API,我们将创建一个系统,通过共享的艺术偏好而不是受欢迎程度来连接人们。
虽然我们将专注于艺术,但这个系统本质上是通用的。用播客、公寓、合作者替换艺术品,其逻辑仍然成立。一旦所有事物都成为向量,相同的管道就可以为合适的人在几乎任何领域推荐合适的物品。
传统推荐系统的问题
大多数推荐系统都以流行度为目标进行优化,依赖于协同过滤等技术,假设行为相似的用户具有相似的品味。但在艺术领域,这种假设常常失效。一个人的最爱画作可能会让另一个人感到冷漠。这些反应是高度个人化的,并且会发生变化。今天喜欢超现实主义的用户明天可能会在极简主义中找到慰藉。我们需要一个向内倾听的系统,一个将品味建模为动态、不断变化的景观的系统。这正是我们正在构建的。
通过互动建模审美偏好
审美偏好并非一成不变,它会漂移、深化,有时甚至完全转向。这些转变通常是在无意识中发生的,但它们会体现在互动模式中。
每当一个人与一件艺术品互动时,他们都会留下一个信号,单独看,这些信号可能看起来很小。但随着时间的推移,它们开始勾勒出一个形状,一种情感指纹。
大多数系统试图将这种形状压缩成一个单一的向量。但人类的品味不属于一条直线。它是分层的,多方面的,而且常常是矛盾的。一个人可以同时热爱抽象艺术和现实主义。一个真正富有表现力的模型应该反映这一点。
为了捕捉这种丰富性,我们将每个用户视为空间中一系列不同的点,这些簇随着他们与艺术的关系随时间演变。每个簇将根据互动的远近和频率获得不同的权重。
系统如何工作
互动获取
每次用户打开平台时,我们都会呈现一套精心策划的画作,并邀请他们以 0 到 5 的等级对每件作品进行评分。这些评分捕捉了用户对每件艺术品的兴趣程度。
在幕后,我们将每个原始评分 ri 转换为带符号的权重 wi= ri-,
其中是一个可调整的“中性”阈值(默认 = 2.5)。高于(wi>0)的得分表示正向偏好;低于(wi<0)的得分表示负向偏好。
如果用户系统性地选择量表的上限,我们只需提高以保持正负信号之间的平衡。
艺术品嵌入
该系统的核心是通过图像本身而非关键词或类别来理解艺术的能力。每件艺术品都通过图像编码器转换为向量,该编码器不仅捕捉形式和颜色,还捕捉风格、视觉色调和构图。图像编码器可以是用于视觉任务的预训练编码器,或者更好的是,是经过微调的模型,能够捕捉绘画风格。
结果是一个高维嵌入,将艺术品放置在一个语义空间中,其中相似的作品,无论是风格、主题、时期还是调色板,都彼此靠近,甚至跨越风格界限。这些嵌入成为后续所有工作的基础层:聚类、评分,最终是艺术家推荐。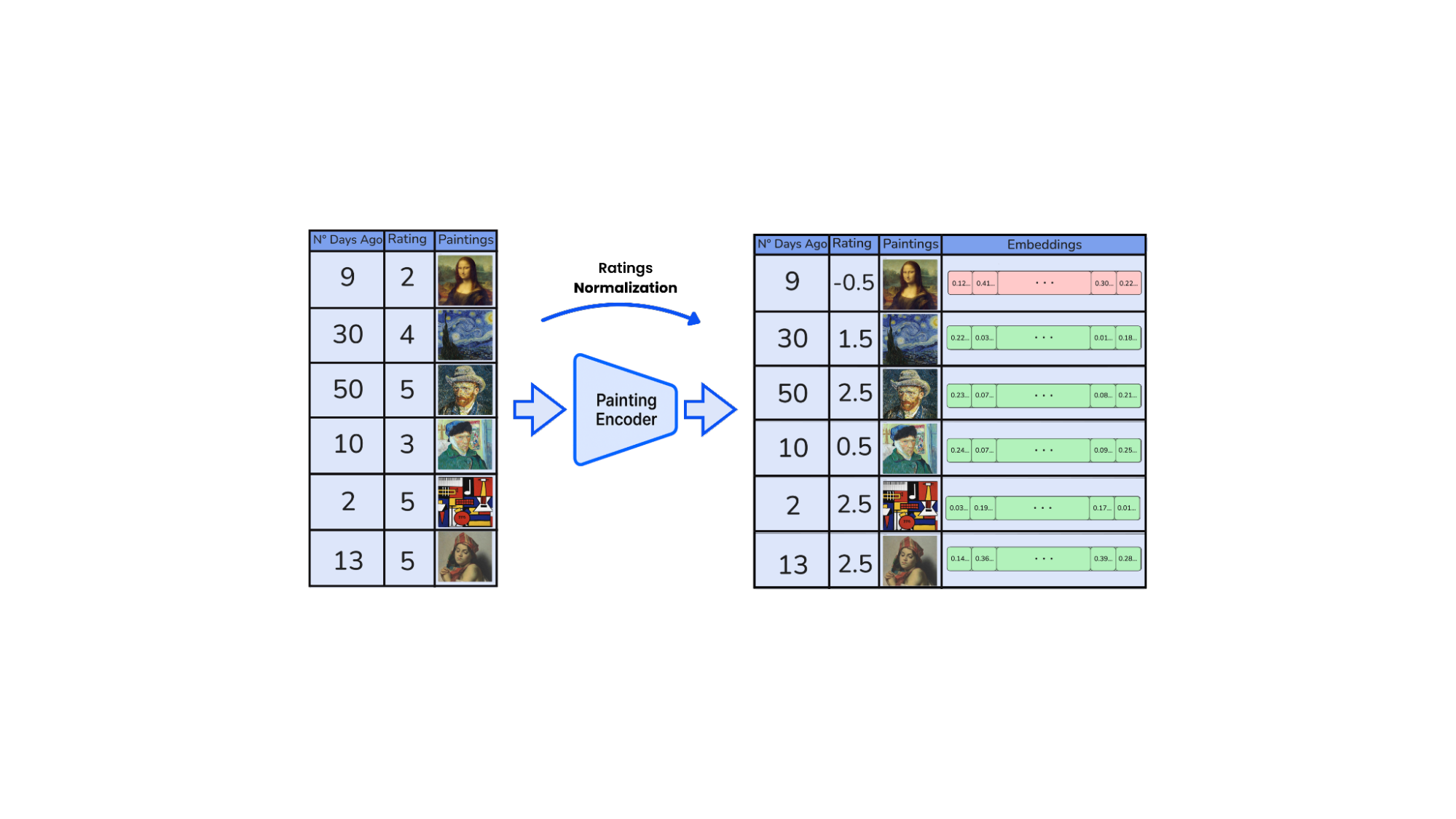
使用 HDBSCAN 进行交互聚类
一旦每件艺术品被嵌入,我们便转向用户,将其视为一系列时刻,而非静态配置文件。每次与艺术品互动都成为嵌入空间中的一个点,形成视觉偏好的云。
为了揭示这朵云中的结构,我们使用 HDBSCAN,这是一种基于密度的聚类算法,与 k-means 不同,它不需要预定义簇的数量。这在建模审美偏好时至关重要,因为审美偏好很少是统一的。一个用户可能同时或分阶段对浪漫主义、野兽派建筑和蒸汽波做出反应。
我们将互动分为两组
- 积极互动:wi > 0 的互动(绿色)
- 消极互动:wi < 0 的互动(红色)
每组都使用 HDBSCAN 独立聚类。这会在嵌入空间中产生多个局部区域,反映连贯的审美主题。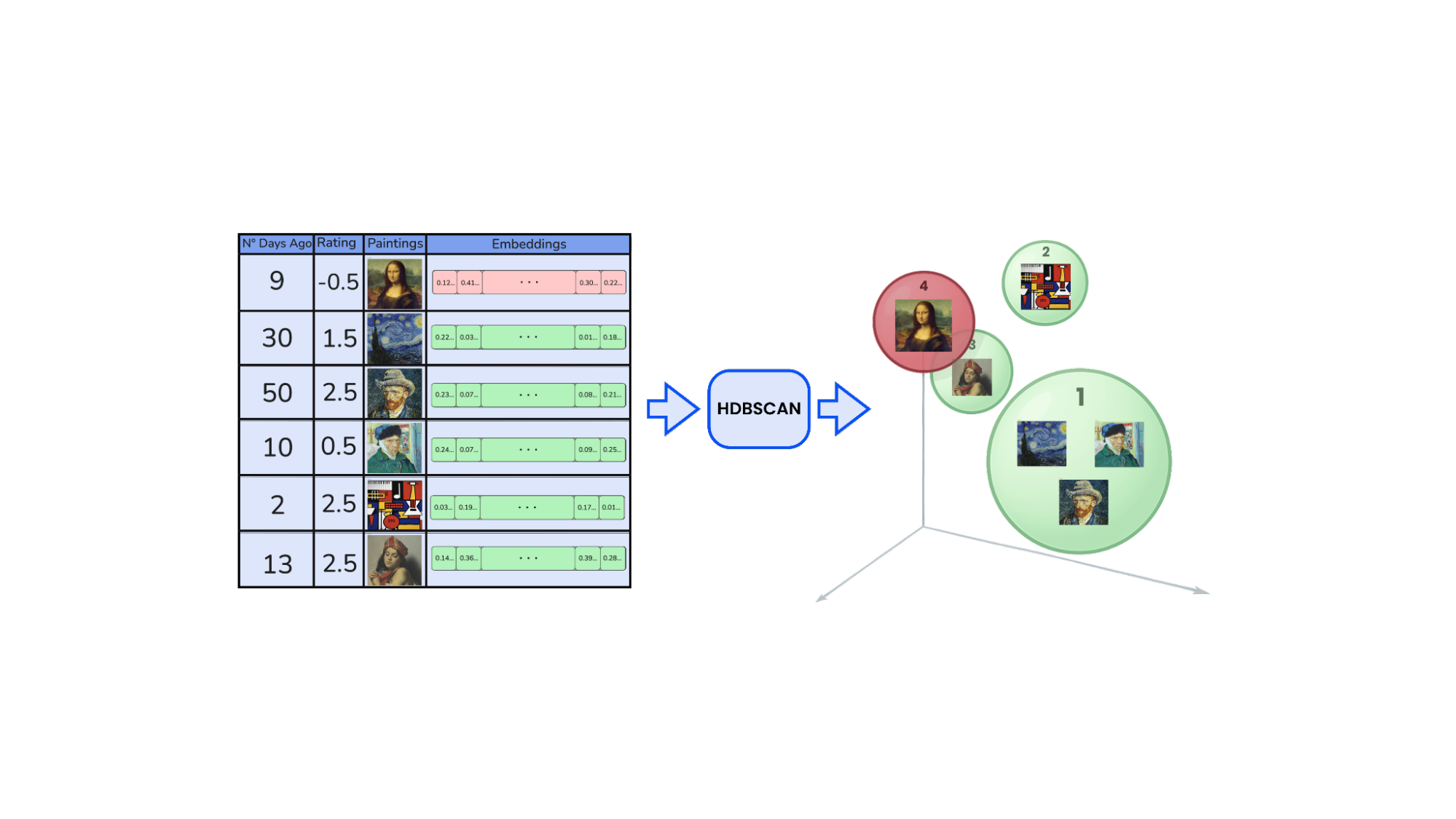 每个聚类都由其中心点(medoid)表示,中心点是该组中最中心、最具代表性的嵌入。这些中心点成为用户品味配置文件的核心构建块。
每个聚类都由其中心点(medoid)表示,中心点是该组中最中心、最具代表性的嵌入。这些中心点成为用户品味配置文件的核心构建块。
我们使用中心点而不是质心,因为质心是聚类中所有嵌入的平均值,可能不对应任何实际样本,并且可能受到嵌入空间中异常值或非线性距离的影响。相反,中心点是一个实际的数据点,能够最好地代表聚类,同时保留原始空间的真实结构,这在使用非欧几里得距离(如余弦相似度)时尤为重要。
我们需要明确的是,我们不必使用用户的全部历史记录,我们可以回顾一段时间来考虑最近的互动。这个时间阈值将取决于用户在平台上互动的频率以及您一次拥有的互动数量。
按时间远近对品味簇进行评分
并非所有的品味都具有相同的权重,尤其是随着时间的推移。用户几个月前喜欢的一组艺术品可能不再反映他们当前的偏好。为了解决这个问题,我们为每个集群分配一个考虑时间远近的得分,强调新近度而不丢弃历史记录。
每个簇都根据其包含的交互时间戳进行评分,使用指数衰减函数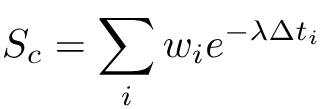
其中
- wi 是之前计算的归一化评分
- 𝚫ti 是自交互 i 以来经过的时间
- 近期互动比早期互动贡献更多
- 较大的集群自然会积累更多的权重,除非它们已经过时
- λ 是一个介于 0 和 1 之间的数字,前者平等地衡量所有事件,无论它们何时发生,后者则更重视最近发生的事件。在此示例中,我们使用 λ=0.01。
这种评分方法同时捕捉了两个维度
- 新近度: 新的偏好浮现出来
- 强度: 活跃度高的集群获得更高的重要性
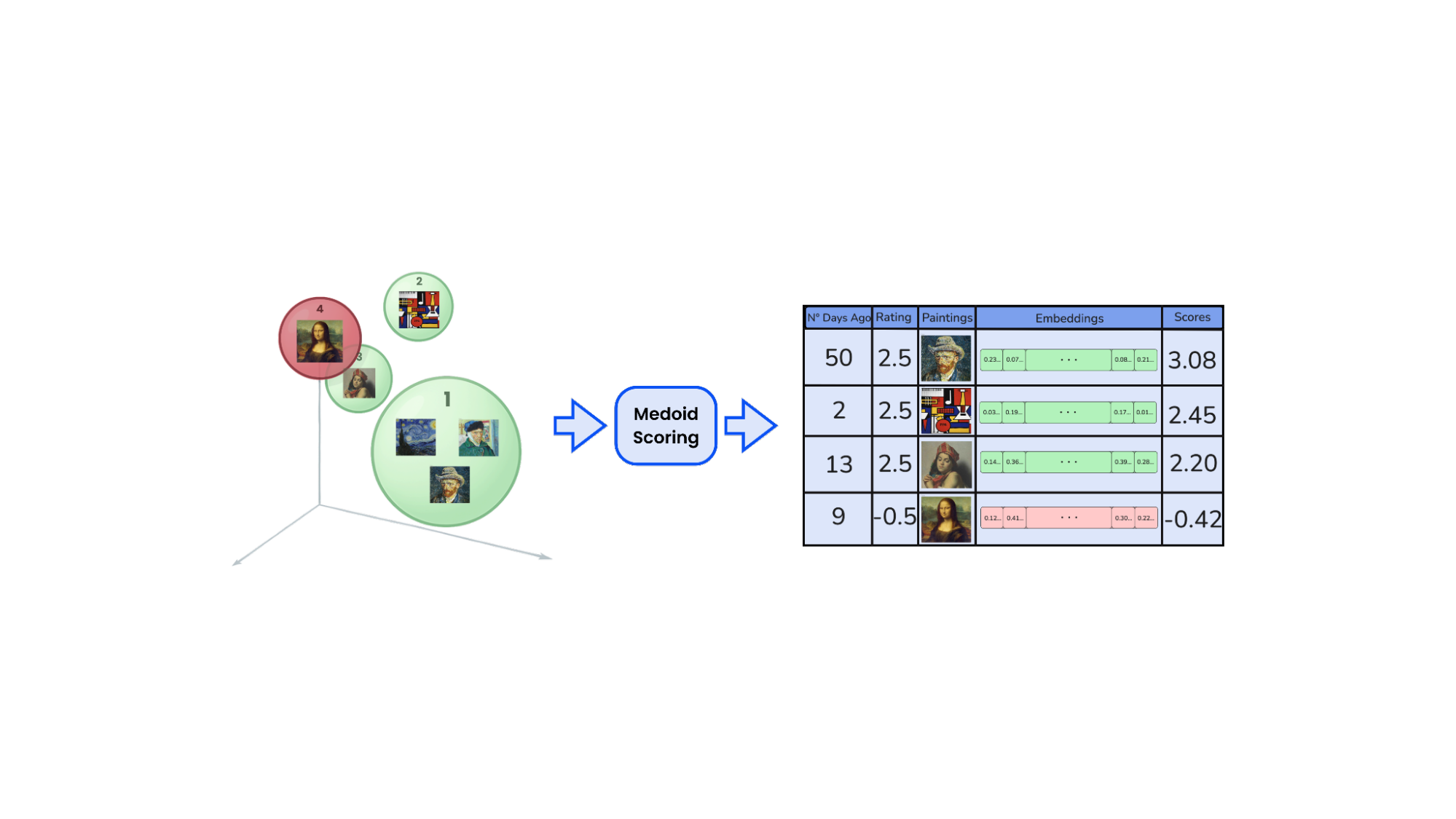
结果是对品味进行动态优先级排序。代表短暂兴趣的集群自然会消退。与长期参与相关的集群仍然突出。
为了保持系统的灵活性并避免每个用户有过多的喜欢,我们仅保留 50% 的分组,依据其根据远近加权的得分 |Sc|。这样做是为了用用户的主要品味来代表他们,而 50% 纯粹是业务决策。通过丢弃较小或过时的集群,我们专注于最强和最新的兴趣信号,确保推荐的准确性和有意义。虽然这种权衡可能会因为遗漏一些较弱的匹配而降低召回率,但通过优先考虑真正引起用户共鸣的内容,它显著提高了准确率。
用户表示为多向量
一旦聚类被识别并评分,我们就会将用户的品味提炼成一种紧凑、富有表现力且可供检索的形式:多向量表示 了解 Qdrant 中多向量表示的更多信息。
每个正向评分的聚类都贡献其中心点向量,这是一个单一的嵌入,代表了该审美偏好的核心。我们对负向评分的聚类也这样做,将它们视为用户倾向于避免的区域。
这为每个用户提供了两组向量
- 正向多向量: 用户最重要的品味聚类,按时间远近加权重要性排序
- 负向多向量: 被拒绝内容的聚类
这些集合共同描述了用户喜欢什么,以及他们倾向于拒绝什么。这是一种更细致、对比鲜明的偏好视图,与 Qdrant 的向量搜索结合使用时尤其强大。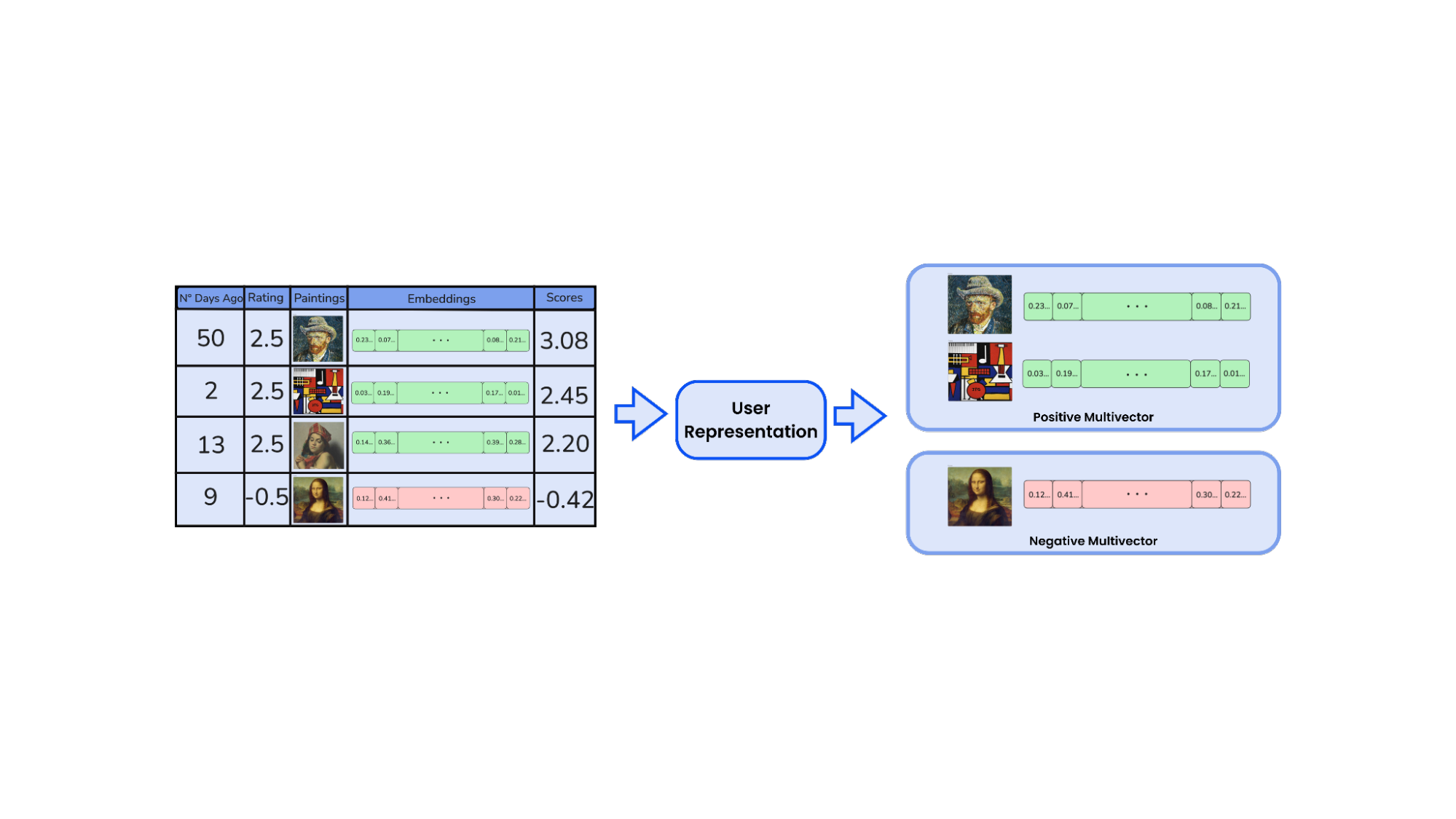
通过 Qdrant 的推荐 API 进行检索
每个用户都由一组浓缩成多向量的正向和负向聚类表示,我们现在可以从建模转向发现。
为了推荐可能与用户当前审美偏好相符的艺术家,我们求助于 Qdrant 推荐 API。与标准的向量搜索不同,Qdrant 的此功能允许我们提供我们正在寻找的内容(由正向多向量表示)以及我们希望避免的内容(由负向多向量表示)。
逻辑很简单:找到那些正向品味与目标用户的偏好高度重叠,同时最大程度地减少与用户倾向于拒绝的聚类的相似性的艺术家。
为此,我们利用 Qdrant 的评分策略,这是一种专门用于处理每个点多个向量的搜索方法。该策略单独评估每个向量。它计算与任何正向聚类的最高相似度,以及与任何负向聚类的最强冲突。
候选者的最终得分计算如下
if best_positive_score > best_negative_score:
score = best_positive_score
else:
score = -(best_negative_score * best_negative_score)
这确保了只有当候选艺术家与用户的核心偏好之一产生共鸣,并且同时不类似于用户倾向于拒绝的内容时,才被视为匹配。
此外,我们通过将这种向量逻辑与元数据过滤相结合来强制执行地理位置和年龄偏好等约束。例如,我们可以使用 Qdrant 的有效负载过滤器将候选人限制在特定区域或特定年龄范围内。
这种行为对于我们的用例来说是直观的。两位艺术家无需在所有审美维度上都兼容。在一个维度上的强烈联系,一种在色彩、纹理或构图上的共同感,可能就足以暗示一种有意义的契合。最佳评分策略尊重这一点,它允许每个聚类表达其自身。
为了比较多向量本身,Qdrant 使用 MaxSim 函数。它通过将一个矩阵中每个向量与另一个矩阵中最佳匹配向量之间的最大相似度相加来计算两个多向量之间的相似度
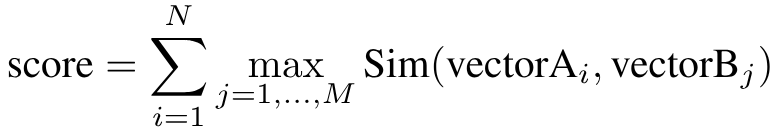
解决冷启动问题
每个推荐系统在面对新用户或新项目时都会遇到障碍,这就是所谓的冷启动问题。如果没有互动数据,你如何知道该推荐什么?
我们的解决方案是一种无摩擦的入职流程,其中我们展示了一系列精心策划的艺术品,涵盖了不同的审美主题。每一次早期互动都会立即反馈到他们的品味集群中。在几次互动后,系统就已经看到了他们风格的粗略轮廓,并可以开始返回真正相关的推荐,无需漫长的预热,也无需猜测。
最终思考
在本次演练中,我们从原始互动日志转向了一个活生生的推荐系统
- 建立了动态用户画像,捕捉了吸引和厌恶。
- 使用编码器将每段内容都放入相同的向量空间。
- 使用 HDBSCAN 对这些向量进行聚类,选择中位点作为锚点,并让指数衰减函数显示哪些聚类更相关。
- 查询 Qdrant 的推荐 API 以检索与用户正向多向量紧密对齐的候选者,同时主动疏远与负向不兼容信号相关的候选者。
这就是整个堆栈,一气呵成,它就是您部署一个可应用于各个领域的生产级推荐引擎所需的全部!
