





























TrustGraph 如何使用 Qdrant 构建企业级智能代理 AI
Daniel Azoulai
·2025 年 10 月 10 日


TrustGraph + Qdrant:技术深度解析
当团队首次尝试智能代理 AI 时,旅程通常始于一个精巧的演示:将几个 API 拼接在一起,一个大型语言模型回答问题,以及足以打动利益相关者的少量虚假修饰。
但一旦这些演示面临企业要求(持续数据摄取、合规性、数千用户、24x7 正常运行时间),幻想就会破灭。服务在第一次故障时就会停滞,查询可靠性急剧下降,监管护栏无处可寻。在五分钟的演示中奏效的方案在生产中变得无法维护。
 故障模式图:“从 POC 到生产。”
故障模式图:“从 POC 到生产。”
这正是 TrustGraph 旨在弥合的差距。从第一天起,他们就以 Qdrant 作为架构的核心组成部分,设计他们的平台以实现可用性、确定性和规模化。
为生产而非演示构建
TrustGraph 的架构是完全容器化的、模块化的,并且可以部署在云、虚拟化或裸机环境中。
其核心是三大支柱
一个基于 Apache Pulsar 的流式主干。持久队列、模式演进和可回放性提供了弹性。如果进程失败,它会自动重启并恢复,而不会丢失数据。
图原生语义。知识以资源描述框架 (RDF) 建模,并以 SPARQL 模板指导检索。这减少了对脆弱的、模型生成的查询的依赖,并确保答案精确且可审计。
Qdrant 向量搜索。实体被嵌入并存储在 Qdrant 中,实现快速、可靠的相似性搜索,并集成到图驱动的工作流中。
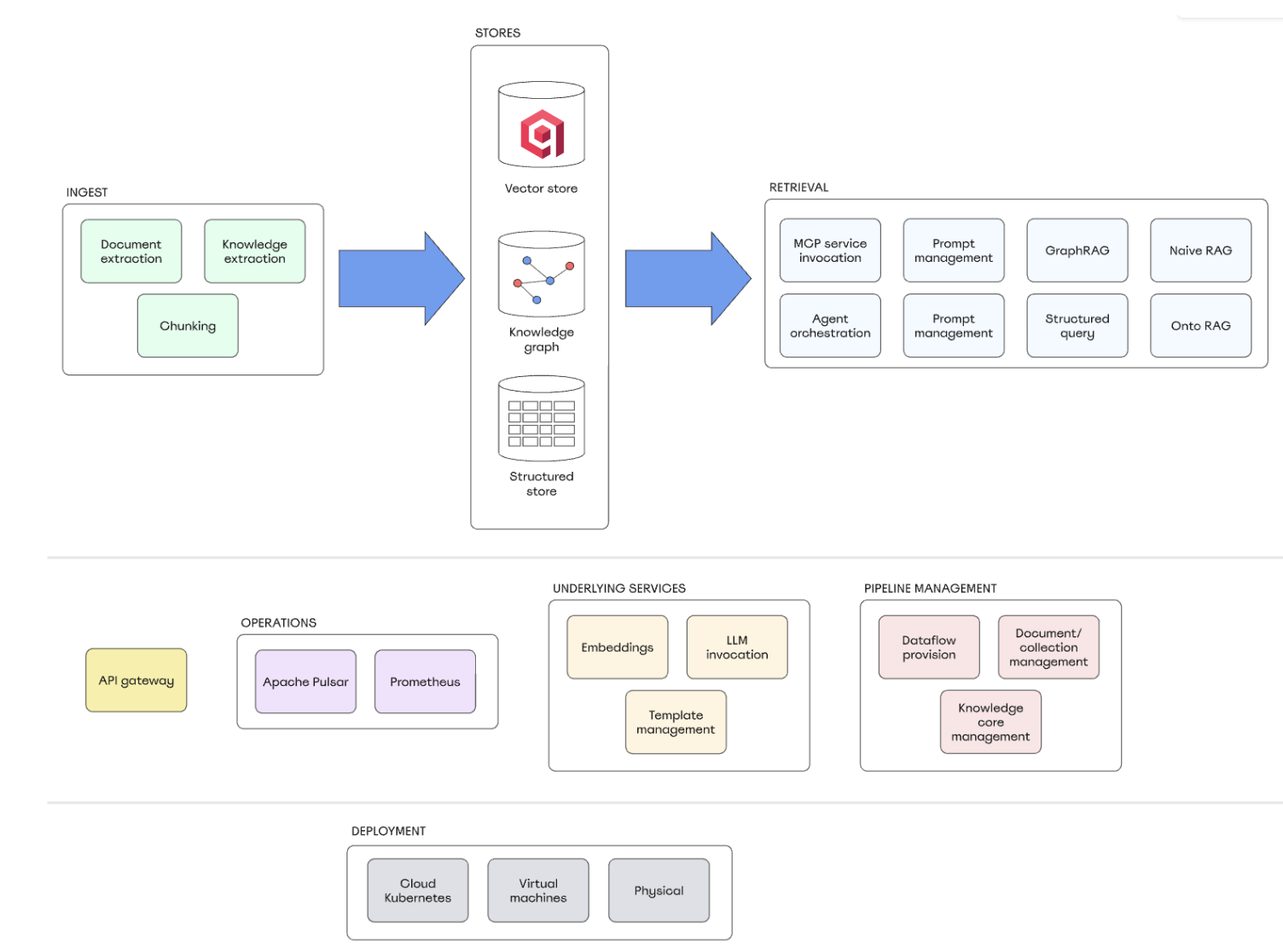 架构概述
架构概述
从文档到知识
TrustGraph 不会将文档分解成块,而是提取事实。LLM 识别实体和关系,并将它们组装成一个知识图谱。同时,实体的嵌入存储在 Qdrant 中。
这种双重表示允许查询基于语义相似性和图结构进行自我定位。例如,询问“告诉我关于爱丽丝的事”会通过 Qdrant 检索“爱丽丝”实体,并将其映射到她在图中的连接,而不是仅仅显示包含她姓名的句子。
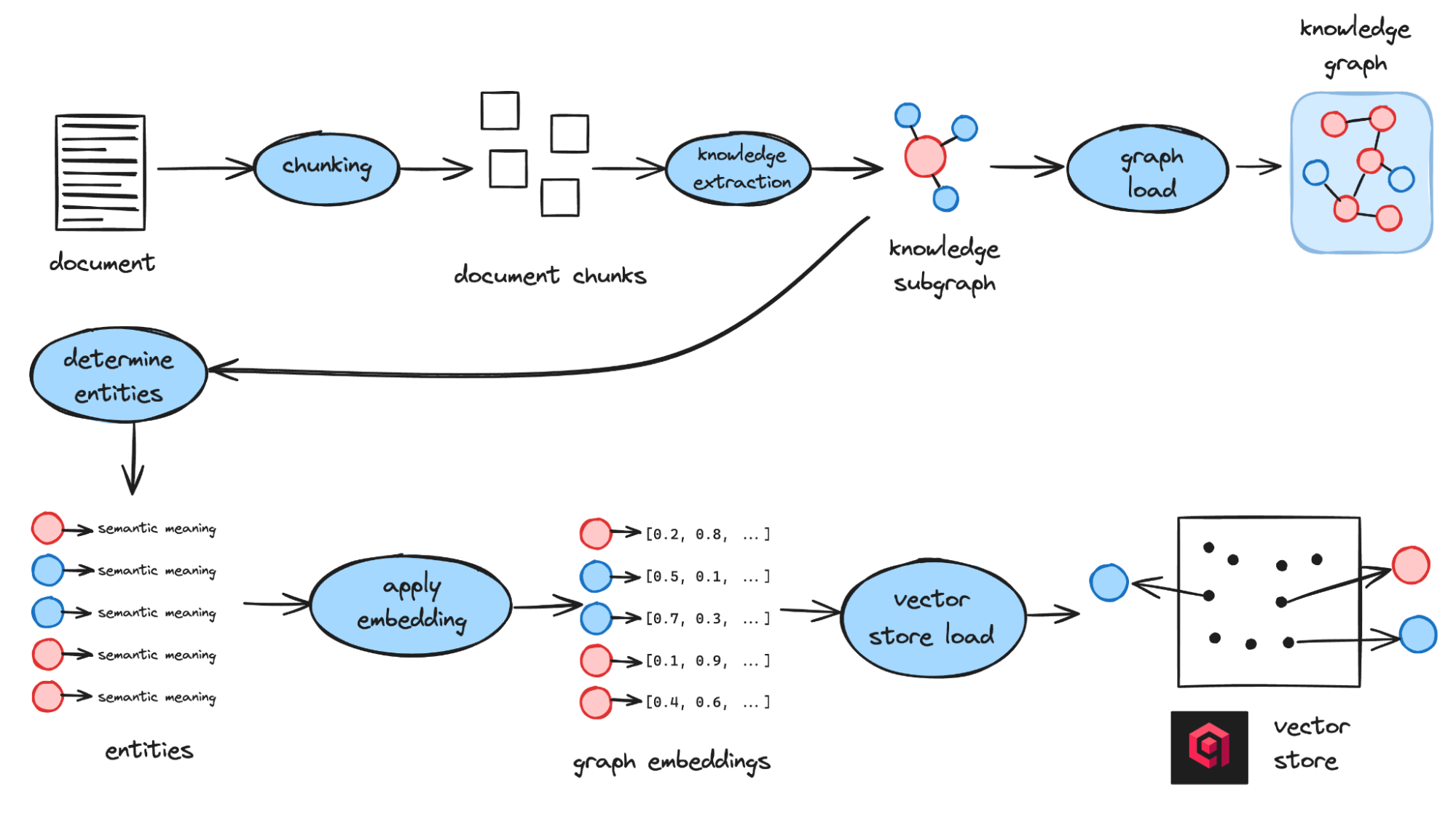 摄取过程
摄取过程
超越 RAG 的检索
当查询进入系统时,它会遵循一个确定性路径
查询被嵌入到向量中。
Qdrant 检索最接近的实体。
这些实体扩展成相关事实的子图。
子图被传递给 LLM,LLM 严格根据该精选上下文进行回答。
这种方法超越了传统的 RAG,后者只停留在语义相似的块。以图为锚点的检索允许 TrustGraph 揭示因果或相关知识。例如,“发动机为何故障?”不仅会找到“发动机”和“故障”的提及,还会通过图连接发现相关的原因,如金属疲劳或冷却液泄漏。
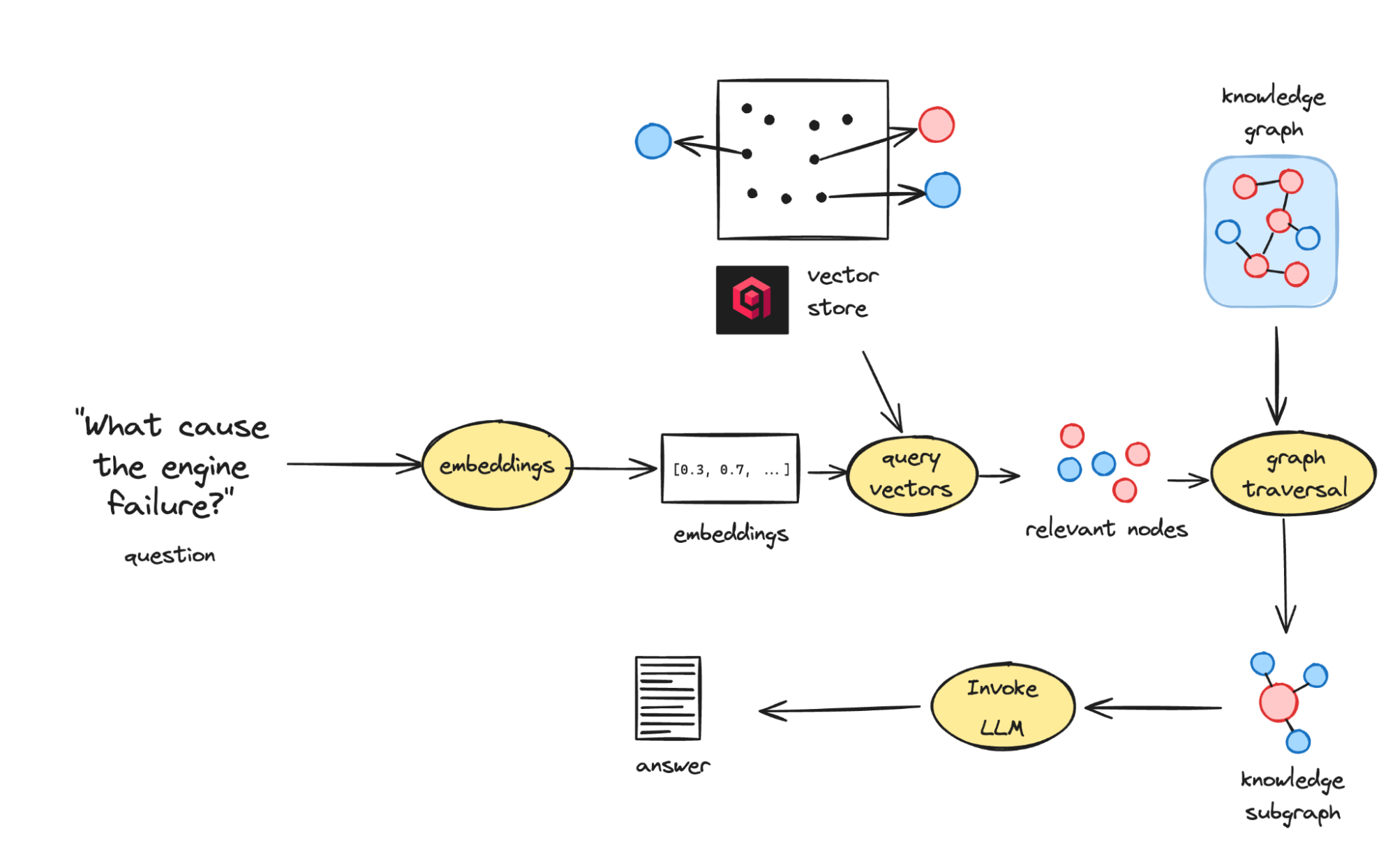 查询过程
查询过程
大规模智能代理 AI
TrustGraph 的检索能力位于更广泛的智能代理 AI 框架内。开发人员可以协调结合以下功能的管道
用于结构化事实检索的 GraphRAG
用于确定性的模板驱动查询
用于外部操作的 MCP 工具调用
NLPR - 自然语言精确检索(实验性),它使用本体驱动专业提取
这使得企业能够构建将内部知识图与外部数据源集成的检索管道,同时保持可靠性和控制。
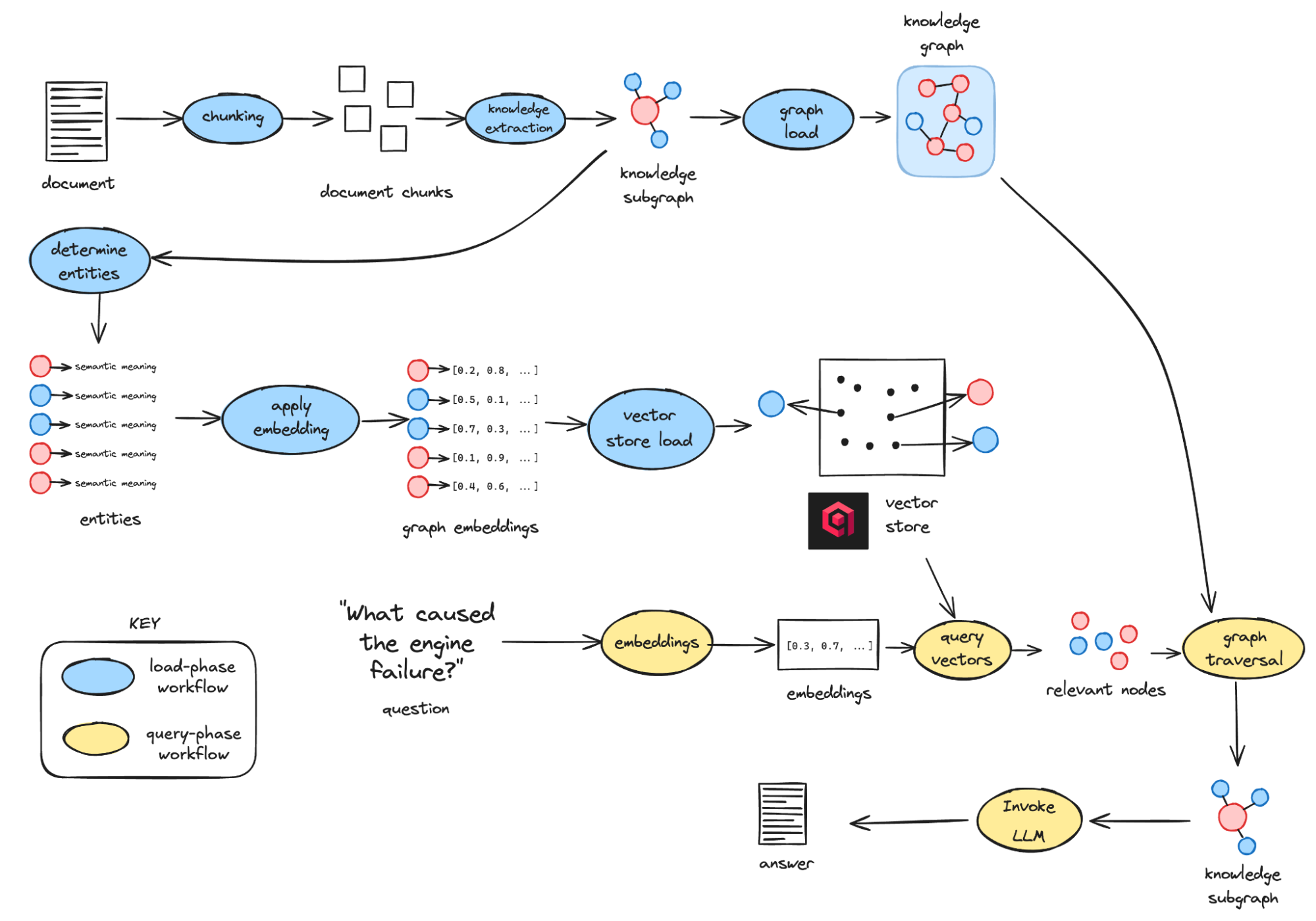 摄取和查询过程
摄取和查询过程
生产中重要的成果
通过结合弹性流式骨干、图原生语义和 Qdrant 驱动的检索,TrustGraph 提供了生产级的架构成果
确定性 — 模板驱动的 SPARQL 和 Qdrant 相似性搜索消除了脆弱的查询合成。
弹性 — Pulsar 管道自动重放和恢复,在故障或滚动更新期间保持系统响应。
可扩展性与主权 — 该平台可在各种硬件堆栈上运行,包括非 NVIDIA GPU,并支持严格的欧洲数据主权要求。
开发人员简易性 — Qdrant 的开源、容器化设计使扩展变得简单,并减少了操作摩擦。
“我们没有理由重新考虑替代方案。Qdrant 满足了速度、可靠性和简单性的要求——并且它将继续如此。”
— Daniel Davis,TrustGraph 联合创始人
从演示到持久基础设施
TrustGraph 展示了智能代理 AI 如何从华丽的演示演变为关键任务企业软件。通过将检索基于图语义和 Qdrant 的向量引擎,他们将不确定性推向边缘,同时保持正常运行时间、可审计性和主权。
