





























数据驱动的 RAG 评估:使用 Relari AI 测试 Qdrant 应用
Thierry Damiba, David Myriel & Yi Zhang
·2024 年 9 月 16 日

使用性能指标评估 RAG 系统
评估检索增强生成 (RAG) 应用程序的性能对于开发人员来说可能是一项复杂的任务。
为了简化这一过程,Qdrant 与 Relari 合作,提供深入的 RAG 评估流程。
作为 向量数据库,Qdrant 负责数据存储和检索,而 Relari 使您能够运行实验来评估您的 RAG 应用在实际场景中的表现。它们共同实现了快速、迭代的测试和评估,从而更容易跟上您应用程序的开发进度。

Qdrant 和 Relari 合作开展了一个联合项目,使用合成数据测试 RAG 性能。
您将学到什么
在最近的一次网络研讨会中,我们讨论了构建和评估 RAG 系统的最佳方法。Relari 提供工具,可以使用内在和外在方法评估 大型语言模型 (LLM) 应用程序。结合 Qdrant 强大的 数据存储,它创建了一个坚实的评估框架。
在这篇文章中,我们将介绍您可以与 Qdrant 和 Relari 一起使用的两种评估方法,以及实际用例。具体来说,我们将通过一个分析 GitLab 法律政策数据集的示例来引导您。您可以跟着这个 Google Colab Notebook 中的代码进行操作。
RAG 评估的关键指标:Top-K 和自动提示优化
为了确保您的 RAG 系统在实际条件下良好运行,关注性能优化至关重要。虽然精度、召回率和基于排名的传统指标很有帮助,但它们并不总是足够。评估 RAG 系统的两种高级策略是 Top-K 参数优化和自动提示优化。这些技术有助于提高您的模型为实际用户提供最佳体验的可能性。
Top-K 参数优化
Top-K 参数控制向用户显示多少个热门结果。想象一下使用一个 搜索引擎,每次查询只显示一个结果——这可能是一个好的结果,但大多数用户更喜欢有更多选择。另一方面,显示太多结果可能会让用户不知所措。
例如,在 产品推荐系统 中,Top-K 设置决定用户是看到前 3 个最畅销产品还是 10 个不同的选项。调整此参数可确保用户有足够的相关选择而不会感到迷失。
使用 Relari 和 Qdrant,测试不同的 Top-K 值非常容易。首先,我们将使用 Qdrant 构建一个简单的 RAG 应用,然后我们将使用 Relari 评估其性能。
如何开始
前往 Qdrant Cloud 和 Relari 创建帐户并获取您的 API 密钥。获取密钥后,将它们添加到您的 Google Colab 密钥中,然后就可以开始了!
安装依赖
在这种情况下,我们将使用 Qdrant、FastEmbed、Relari 和 LangChain**
!pip install relari langchain_community langchain_qdrant
!pip install unstructured rank_bm25
!pip install --upgrade nltk
设置环境
from google.colab import userdata
import os
os.environ['RELARI_API_KEY'] = userdata.get('RELARI_API_KEY')
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
设置 Relari
from relari import RelariClient
client = RelariClient()
创建一个新的 Relari 项目
proj = client.projects.create(name="Gitlab Employee Assistant")
定义黄金数据集
在本案例研究中,我们将使用 GitLab 法律政策数据集,但您可以轻松地替换为您自己的数据集。数据集在 Relari 评估和改进 LLM 应用程序 的方法中至关重要。数据集充当“真实情况”或参考点,用于测试 LLM 管道的准确性和性能。
Relari 的数据驱动方法确保评估可靠且彻底。您可以在 此处 了解更多关于 Relari 如何处理数据集的信息。
!wget https://ceevaldata.blob.core.windows.net/examples/gitlab/gitlab_legal_policies.zip
!unzip gitlab_legal_policies.zip -d gitlab_legal_policies
创建数据集
数据下载完成后,您可以通过运行以下命令创建黄金数据集。此数据集将作为您的测试或评估的真实情况,提供衡量 RAG 应用程序准确性的基准。
from pathlib import Path
dir = Path("gitlab_legal_policies")
task_id = client.synth.new(
project_id=proj["id"],
name="Gitlab Legal Policies",
samples=30,
files=list(dir.glob("*.txt")),
)
这将准备好数据集以供 Relari 使用,允许您根据已知参考评估您的应用程序。
构建一个简单的 RAG 应用
现在项目已经设置好,让我们继续构建用于评估的检索增强生成 (RAG) 应用程序。我们将使用 Qdrant 进行 向量搜索,FastEmbed 进行嵌入,以及 LangChain 进行文档工作流管理。
导入所有库
from langchain_community.document_loaders.directory import DirectoryLoader
from langchain_qdrant import Qdrant
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from relari.core.types import DatasetDatum
加载并分块数据
我们将使用 LangChain 准备我们的数据。
# load the document and split it into chunks
loader = DirectoryLoader("gitlab_legal_policies/")
documents = loader.load_and_split()
现在我们将使用 Qdrant 的内置嵌入提供程序 FastEmbed 来嵌入我们的分块。
# Initialize FastEmbedEmbeddings
embeddings = FastEmbedEmbeddings(
model_name="BAAI/bge-small-en-v1.5", # specify the model
)
将数据存储在 Qdrant 中
最后,我们将分块上传到 Qdrant 集合中。
# Load chunks into a Qdrant Cloud vectorstore using FastEmbedEmbeddings
db = Qdrant.from_documents(
documents,
embedding=embeddings,
url=os.environ['QDRANT_URL'], # Qdrant Cloud URL
api_key=os.environ['QDRANT_API_KEY'], # Qdrant Cloud API Key
collection_name="gitlab_legal_policies",
)
print(f"{len(documents)} chunks loaded into Qdrant Cloud vector database.")
开始记录结果
现在数据已上传到 Qdrant,我们可以构建一个函数来在数据集上运行不同的 RAG 管道并记录结果以供评估。这将允许我们跟踪各种配置(例如不同的 Top-K 值)的性能,并将结果反馈给 Relari 进行进一步分析。
这是一个记录不同检索器配置结果的函数
# Prepare a function to run different RAG pipelines over the dataset and log the results
def log_retriever_results(retriever, dataset):
log = list()
for datum in dataset.data:
# First compute the result
retrieved_docs = retriever.invoke(datum["question"])
# Now log the result in Relari format
result = DatasetDatum(
label=datum["uid"],
data={"retrieved_context": [doc.page_content for doc in retrieved_docs]},
)
log.append(result)
return log
这就是结合 Qdrant 和 Relari 的强大之处。您无需构建多个应用程序,慢慢地插入和检索数据,而是可以使用两者快速测试不同的参数并立即获得结果。此评估系统专为快速、有用的迭代而构建。
评估结果
RAG 应用程序构建完成后,是时候通过尝试不同的 Top-K 值来评估其性能了。Top-K 参数控制在检索过程中返回给用户的热门结果数量,优化此参数可以改善用户体验和结果的相关性。
首次尝试:使用 top-K 进行实验
在此实验中,我们将测试各种 Top-K 值(3、5、7 和 9),以了解它们如何影响检索性能。
k_values = [3, 5, 7, 9] # Define the different values of top k to experiment
semantic_retrievers = {}
semantic_logs = {}
# Run the retrievers on the dataset and log retrieved chunks
for k in k_values:
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
log = log_retriever_results(retriever, dataset)
semantic_retrievers[f"k_{k}"] = retriever
semantic_logs[f"k_{k}"] = log
print(f"Results on {dataset.name} by Semantic Retriever with k={k} saved!")
将结果发送到 Relari
记录不同 Top-K 实验的结果后,您可以将它们提交给 Relari 进行评估。Relari 将使用精度/召回率和排名感知方法等指标分析您的结果,从而您可以比较每种配置的性能。以下是如何将结果发送到 Relari
对于每个 Top-K 配置,我们将结果提交给 Relari,并使用适当的指标运行评估。这将帮助您根据不同的 K 值对 RAG 系统的性能进行基准测试。
from relari import Metric
for k in k_values:
eval_name = f"Semantic Retriever Evaluation k={k}"
eval_data = semantic_logs[f"k_{k}"]
eval_info = client.evaluations.submit(
project_id=proj["id"],
dataset=dataset_info["id"],
name=eval_name,
pipeline=[Metric.PrecisionRecallF1, Metric.RankedRetrievalMetrics],
data=eval_data,
)
print(f"{eval_name} submitted!")
对于我们的数据集,如果希望召回率大于 85%,我们应该选择 K 值至少为 7。
我们甚至可以在 UI 中查看单个案例以获得更多见解。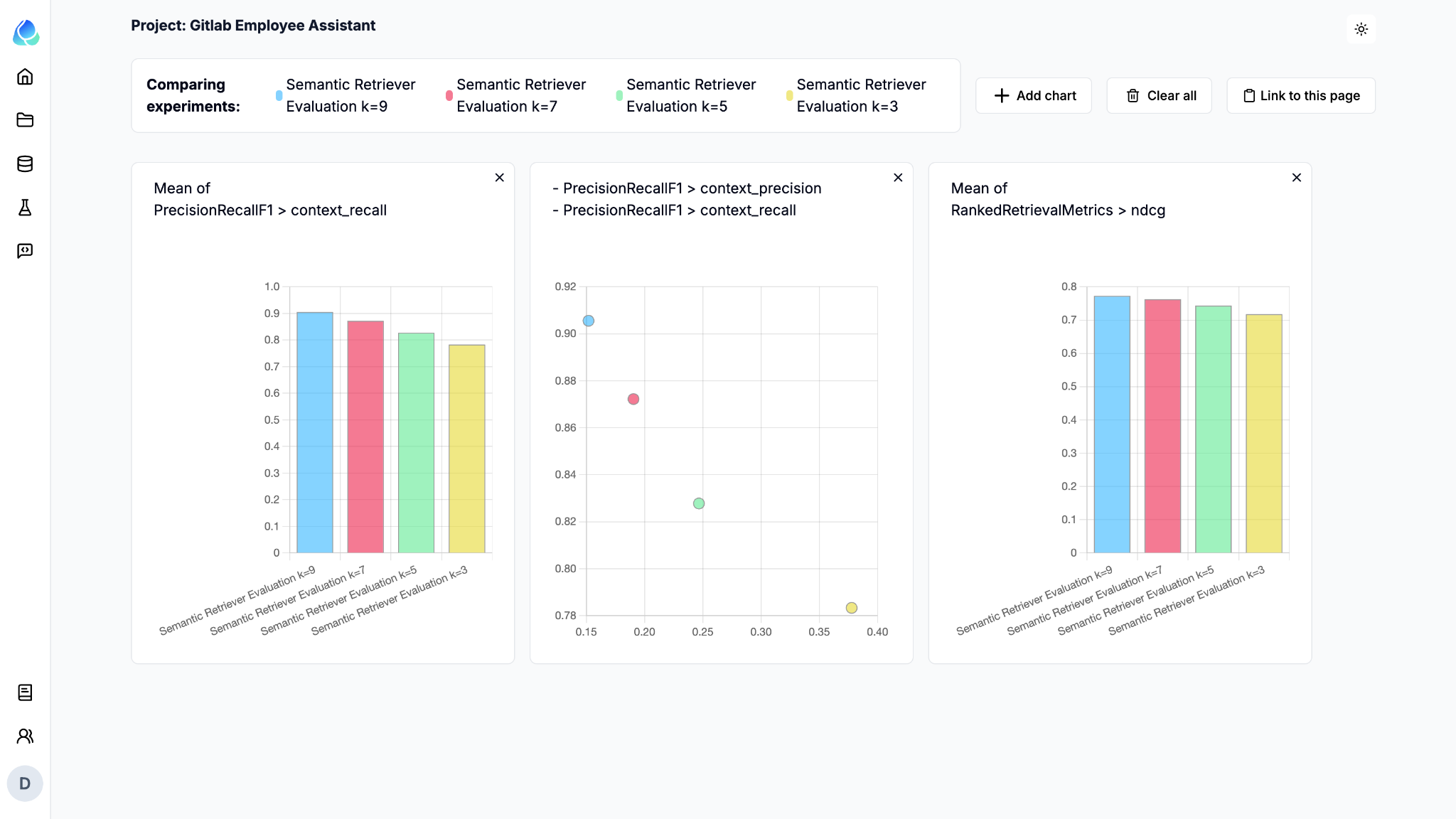
Relari 和 Qdrant 也可以集成以评估 混合搜索系统,该系统结合了稀疏(传统基于关键字)和密集(基于向量)搜索方法。这种组合允许您利用两种方法的优势,从而可能提高搜索结果的相关性和准确性。
通过将 Relari 的评估框架与 Qdrant 的 向量搜索 功能结合使用,您可以尝试混合搜索的不同配置。例如,您可以测试改变稀疏到密集搜索结果的比例,或调整每个组件对整体检索得分的贡献方式。
自动提示优化
在像 聊天机器人 这样的对话应用程序中,自动提示优化 (APO) 通过持续优化聊天机器人与用户互动的方式来增强其沟通效率。APO 从之前的互动中学习,调整和改进响应的措辞,从而实现更准确、更具吸引力且用户友好的对话。
例如,在 客户服务聊天机器人 中,问题的措辞方式会极大地影响用户满意度。虽然传达的信息可能相同,但表达方式很重要。想想在巴黎咖啡馆点餐:用法文点餐可能会比用英文点餐带来更愉快的互动,即使请求是相同的。同样,APO 帮助聊天机器人找到最佳的问题或响应方式,以确保用户感到被理解和参与,从而增强整体体验。
随着时间的推移,APO 会微调聊天机器人使用的提示,以优化互动,使系统更响应用户需求和上下文,提高生成答案的质量,并最终提高用户满意度。
自动提示优化不断完善聊天机器人的回复,以改善用户互动。以下是如何使用 Relari 实施 APO
设置基本提示
通过自动提示优化,您可以定义一个系统提示并在每次交互迭代中检查结果。
from relari.core.types import Prompt, UserPrompt
base_prompt = Prompt(
system="You are a GitLab legal policy Q&A bot. Answer the following question given the context.",
user=UserPrompt(
prompt="Question: $question\n\nContext:\n$ground_truth_context",
description="Question and context to answer the question.",
),
)
该提示使用变量 question 和 ground_truth_context。这些变量有助于衡量生成答案与真实上下文的忠实程度(即,它没有出现幻觉)。
有关其他指标的更多详细信息,请访问 Relari 文档网站
设置任务 ID
task_id = client.prompts.optimize(
name="GitLab Legal Policy RAG Prompt",
project_id=proj["id"],
dataset_id=dataset_info["id"],
prompt=base_prompt,
llm="gpt-4o-mini",
task_description="Answer the question using the provided context.",
metric=client.prompts.Metrics.CORRECTNESS,
)
print(f"Optimization task submitted with ID: {task_id}")
正确性 (CORRECTNESS) 指标衡量生成的答案与真实参考答案的接近程度。
分析提示
设置自动提示优化后,您可以开始在 Relari UI 中分析提示在每次迭代中如何演变。这使您能够了解系统如何根据之前的交互和用户反馈进行调整和完善其响应。
在 Relari UI 中,您可以
跟踪更改:查看提示如何随时间变化,并查看导致性能改进的迭代。例如,您可以分析不同的措辞如何影响聊天机器人响应的准确性和相关性。
评估有效性:检查每个提示在正确性、流畅性和用户满意度等关键指标方面的表现。您可以查看哪些迭代带来了更好的结果,哪些需要进一步调整。
比较迭代:并排可视化不同提示迭代的比较,帮助您了解哪些具体更改会带来更准确或更具吸引力的响应。
识别模式:查找用户交互中的模式以及聊天机器人如何适应不同的场景,从而深入了解最适合您的目标受众的方法。
这种提示迭代分析有助于确保您的聊天机器人的对话流程持续改进,从而实现更自然、更有效的用户交互。

从自动提示优化 (APO) 生成的最佳系统提示和少量示例可以显著提高您的检索增强生成 (RAG) 系统的性能。
系统提示:这是指导聊天机器人或应用程序如何响应用户查询的基础指令。APO 有助于完善此提示,以确保响应符合用户期望和应用程序目标,从而产生更清晰、更准确的输出。
少量示例:这些是提供给模型的示例,用于演示如何回答问题或解决问题。通过优化这些示例,您的 RAG 系统可以更好地理解上下文并提供更相关和连贯的响应。例如,使用精心设计的少量示例可以大大减少语言模型输出中的幻觉,并导致更具上下文准确性的结果。
通过 APO 识别出最佳系统提示和少量示例后,您可以将它们集成到您的 RAG 系统中。这将确保模型在不同场景中始终提供高质量的结果,从而改善整体用户体验和系统性能。
结论
结合 Relari 和 Qdrant,您可以创建一个迭代的、数据驱动的评估框架,从而优化您的 RAG 系统以实现最佳的实际性能。这些方法有助于确保您的应用程序既响应迅速又有效,尤其是在处理用户查询或推荐时。
如果您想开始使用,请在 Qdrant Cloud 和 Relari 上免费注册。
