





























RAG 评估中的最佳实践:综合指南
David Myriel
·2024 年 11 月 24 日

简介
本指南将教您如何评估 RAG 系统的**准确性**和**质量**。您将学习如何通过测试搜索精度、召回率、上下文相关性和响应准确性来维持 RAG 性能。
**构建 RAG 应用程序只是开始;**测试其对最终用户的有用性并校准其组件以实现长期稳定性至关重要。
RAG 系统可能在三个关键阶段中的任何一个阶段遇到错误:检索相关信息、增强该信息和生成最终响应。通过系统地评估和微调每个组件,您将能够维护一个可靠且与上下文相关的 GenAI 应用程序,以满足用户需求。
为什么要评估您的 RAG 应用程序?
避免幻觉和错误答案

在生成阶段,幻觉是一个显著的问题,LLM 会忽略上下文并编造信息。这可能导致响应不符合现实。
此外,生成有偏见的答案也是一个问题,因为 LLM 产生的响应有时可能有害、不恰当或带有不恰当的语气,从而在各种应用程序和交互中带来风险。
丰富您 LLM 的增强上下文
增强过程面临过时信息等挑战,即响应可能包含不再是最新的数据。另一个问题是上下文间隙的存在,即检索到的文档之间缺乏关系上下文。
这些间隙可能导致呈现不完整或零碎的信息,从而降低增强响应的整体连贯性和相关性。
最大限度地提高搜索和检索过程
在检索方面,搜索的一个重大问题是缺乏精确性,即并非所有检索到的文档都与查询相关。召回率低加剧了这个问题,这意味着并非所有相关文档都成功检索到。
此外,“失落在中间”问题表明,一些 LLM 可能难以处理长上下文,尤其是当关键信息位于文档中间时,导致结果不完整或用处不大。
推荐框架

为了简化评估过程,有几个强大的框架可用。下面我们将探讨三个流行的框架:**Ragas、Quotient AI 和 Arize Phoenix**。
Ragas:使用问答测试 RAG
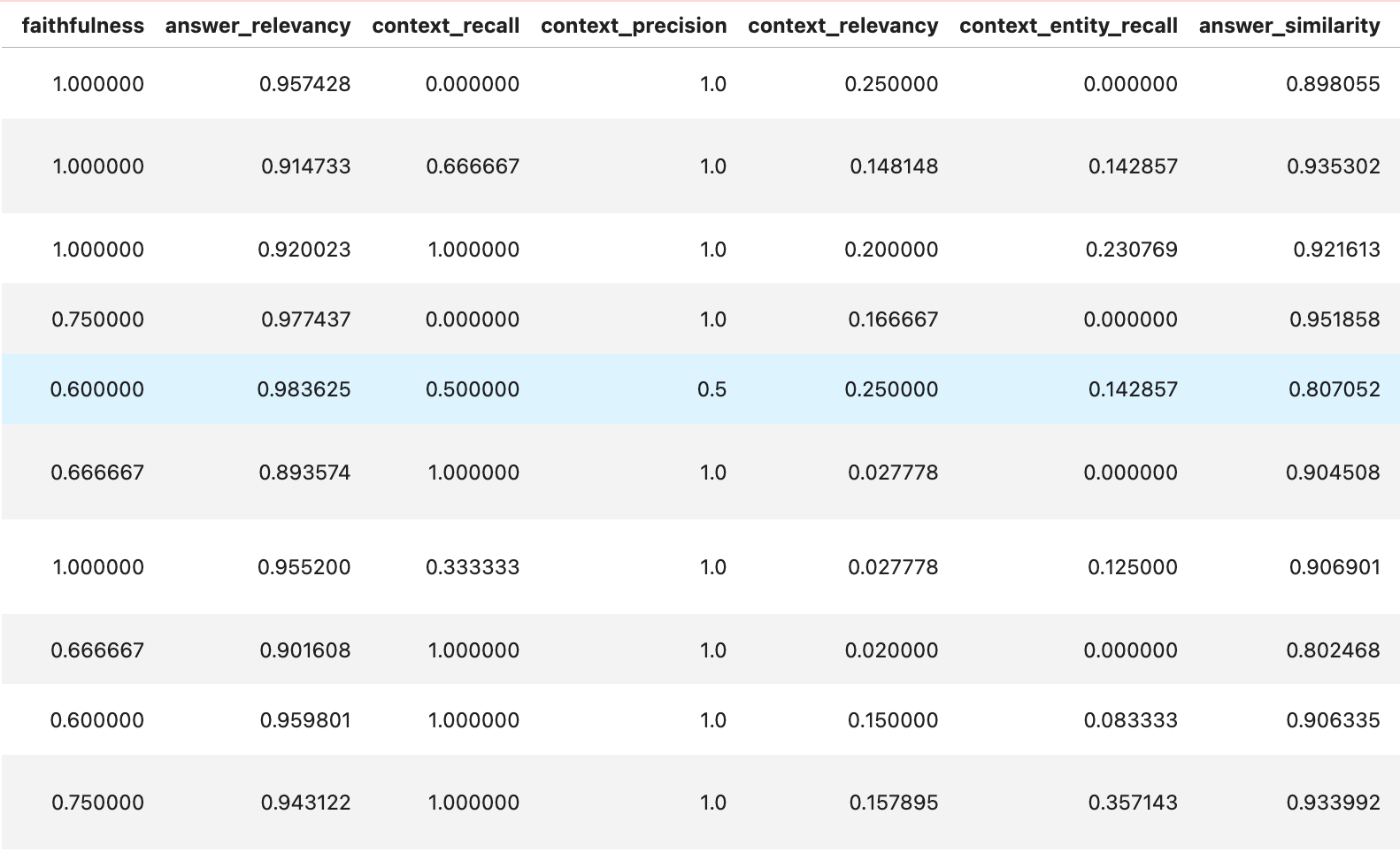
Ragas(或 RAG 评估)使用一个包含问题、理想答案和相关上下文的数据集,将 RAG 系统生成的答案与真实情况进行比较。它提供忠实度、相关性和语义相似性等指标来评估检索和答案质量。
**图 1:** *Ragas 框架的输出,展示了忠实度、答案相关性、上下文召回率、精确度、相关性、实体召回率和答案相似性等指标。这些指标用于评估 RAG 系统响应的质量。*
Quotient:使用自定义数据集评估 RAG 管道
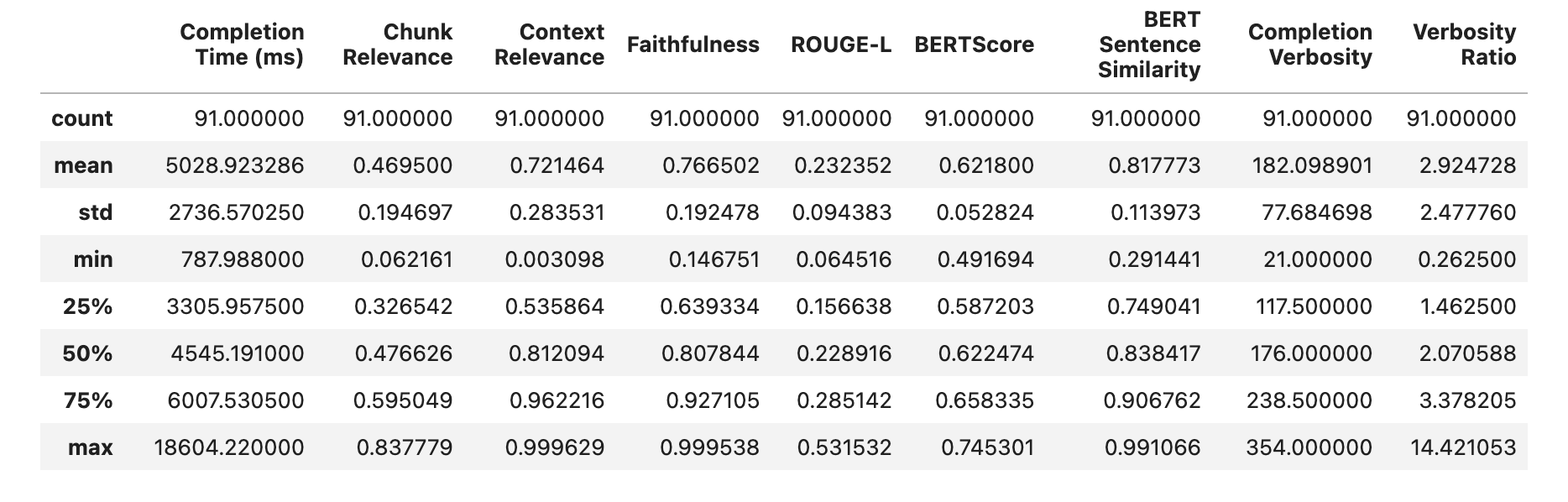
Quotient AI 是另一个旨在简化 RAG 系统评估的平台。开发人员可以上传评估数据集作为基准,以测试不同的提示和 LLM。这些测试作为异步作业运行:Quotient AI 自动运行 RAG 管道,生成响应并提供忠实度、相关性和语义相似性方面的详细指标。该平台的全部功能可通过 Python SDK 访问,使您能够访问、分析和可视化您的 Quotient 评估结果,以发现需要改进的领域。
**图 2:** *Quotient 框架的输出,包含定义数据集在 RAG 管道所有阶段(索引、分块、搜索和上下文相关性)中是否正确操作的统计数据。*
Arize Phoenix:可视化解构响应生成
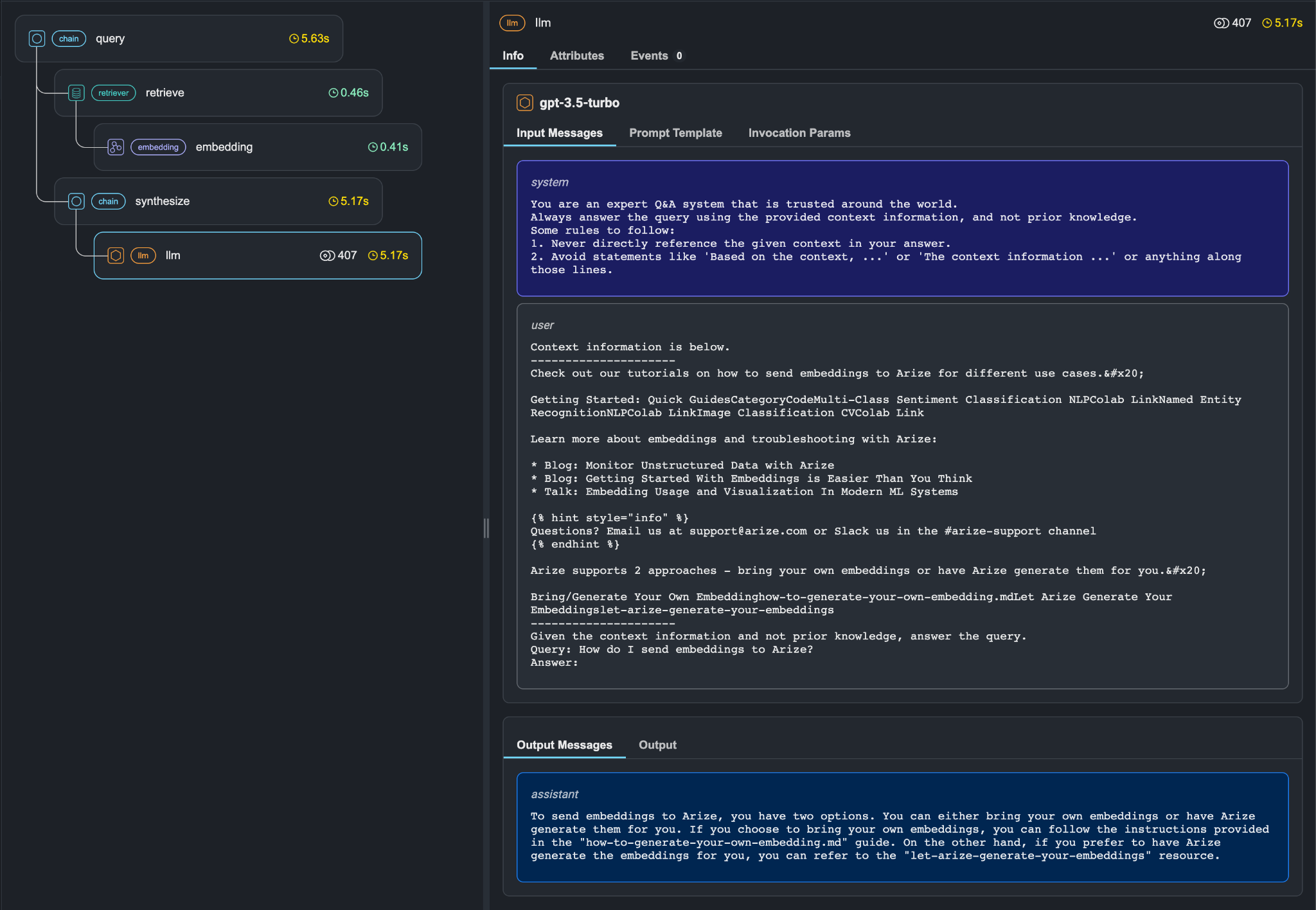
Arize Phoenix 是一个开源工具,通过跟踪响应是如何一步步构建的来帮助提高 RAG 系统的性能。您可以在 Phoenix 中直观地看到这些步骤,这有助于识别减速和错误。您可以定义“评估器”,它们使用 LLM 来评估输出质量、检测幻觉和检查答案准确性。Phoenix 还会计算延迟、令牌使用和错误等关键指标,让您了解 RAG 系统的运行效率。
**图 3:** *Arize Phoenix 工具使用直观,并显示了整个流程架构以及检索、上下文和生成内部发生的步骤。*
您的 RAG 系统可能表现不佳的原因

您将数据错误地摄取到向量数据库中
不正确的数据摄取可能导致重要上下文信息的丢失,这对于生成准确和连贯的响应至关重要。此外,不一致的数据摄取可能导致系统产生不可靠和不一致的响应,从而损害用户信任和满意度。
向量数据库支持不同的索引技术。为了知道您是否正确摄取数据,您应该始终检查与索引技术相关的变量变化如何影响数据摄取。
解决方案:注意数据如何分块
**校准文档块大小:** 块大小决定数据粒度,并影响精度、召回率和相关性。它应与嵌入模型的令牌限制对齐。
**确保适当的块重叠:** 这有助于通过在块之间共享数据点来保留上下文。它应通过去重和内容规范化等策略进行管理。
**制定适当的分块/文本拆分策略:** 确保您的分块/文本拆分策略针对您的数据类型(例如 HTML、Markdown、代码、PDF)和用例细微差别进行定制。例如,法律文档可以按标题和子部分拆分,医学文献可以按句子边界或关键概念拆分。
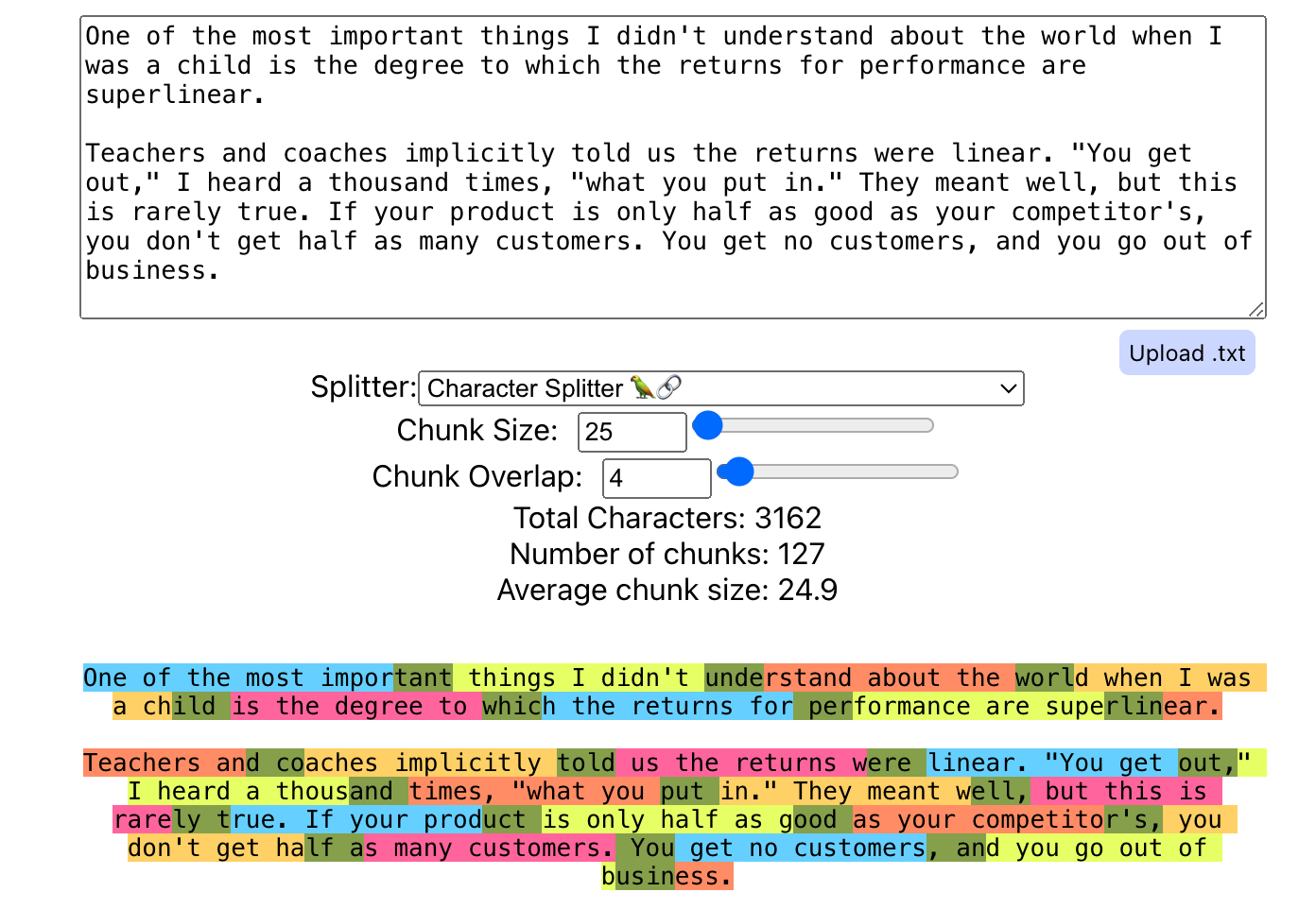
**图 4:** *您可以使用 ChunkViz 等实用程序来可视化不同的块拆分策略、块大小和块重叠。*
您可能错误地嵌入了数据
您希望确保嵌入模型准确理解和表示数据。如果生成的嵌入是准确的,那么相似的数据点将在向量空间中紧密定位。嵌入模型的质量通常使用 大型文本嵌入基准 (MTEB) 等基准来衡量,其中模型的输出与真实数据集进行比较。
解决方案:选择正确的嵌入模型
嵌入模型在捕获数据中的语义关系方面发挥着关键作用。
您可以选择多种嵌入模型,大型文本嵌入基准 (MTEB) 排行榜是一个很好的参考资源。FastEmbed 等轻量级库支持使用流行的文本嵌入模型生成向量嵌入。
选择嵌入模型时,请注意**检索性能**和**领域** **特异性**。您需要确保模型能够捕捉语义细微差别,这会影响检索性能。对于专业领域,您可能需要选择或训练自定义嵌入模型。
您的检索过程未优化

语义检索评估测试您的数据检索效率。您可以选择几种指标:
- **Precision@k**:衡量前 k 个搜索结果中相关文档的数量。
- **平均倒数排名 (MRR)**:考虑搜索结果中第一个相关文档的位置。
- **折现累积增益 (DCG) 和归一化 DCG (NDCG)**:基于文档的相关性得分。
通过使用这些指标评估检索质量,您可以评估检索步骤的有效性。对于专门评估 ANN 算法,Precision@k 是最合适的指标,因为它直接衡量算法近似精确搜索结果的程度。
解决方案:选择最佳检索算法
每个新的 LLM 都声称拥有更大的上下文窗口,从而使 RAG 过时。然而,“迷失在中间”等研究表明,将整个文档提供给 LLM 会降低它们有效回答问题的能力。因此,检索算法对于在 RAG 系统中获取最相关的数据至关重要。
**配置密集向量检索:** 您需要选择正确的相似度度量以获得最佳检索质量。密集向量检索中使用的度量包括余弦相似度、点积、欧几里得距离和曼哈顿距离。
**在需要时使用稀疏向量和混合搜索:** 对于稀疏向量,BM-25、SPLADE 或 BM-42 的算法选择将影响检索质量。混合搜索将密集向量检索与基于稀疏向量的搜索相结合。
**利用简单过滤:** 这种方法将密集向量搜索与属性过滤相结合,以缩小搜索结果范围。
**设置正确的超参数:** 您的分块策略、分块大小、重叠和检索窗口大小会显著影响检索步骤,并且必须根据特定要求进行定制。
**引入重新排名:** 此类方法可以使用交叉编码器模型重新评分向量搜索返回的结果。重新排名可以显著提高检索,从而提高 RAG 系统性能。
LLM 生成性能不佳
LLM 负责根据检索到的上下文生成响应。LLM 的选择范围从 OpenAI 的 GPT 模型到开源模型。您选择的 LLM 将显著影响 RAG 系统的性能。以下是一些需要注意的领域:
- **响应质量**:LLM 的选择将影响生成响应的流畅性、连贯性和事实准确性。
- **系统性能**:LLM 之间的推理速度各不相同。较慢的推理速度会影响响应时间。
- **领域知识**:对于特定领域的 RAG 应用程序,您可能需要针对该领域进行训练的 LLM。一些 LLM 比其他 LLM 更容易微调。
解决方案:测试和批判性分析 LLM 质量
开放 LLM 排行榜可以帮助指导您的 LLM 选择。在此排行榜上,LLM 根据其在各种基准(例如 IFEval、GPQA、MMLU-PRO 等)上的分数进行排名。
评估 LLM 涉及几个关键指标和方法。您可以使用这些指标或框架来评估 LLM 是否提供高质量、相关且可靠的响应。
**表 1:** 衡量 LLM 响应质量的方法
| 列标题 | 列标题 |
|---|---|
| 困惑度 | 衡量模型预测文本的好坏。 |
| 人工评估 | 根据相关性、连贯性和质量对响应进行评分。 |
| BLEU | 用于翻译任务,比较生成输出与参考翻译。分数越高 (0-1) 表示性能越好。 |
| ROUGE | 通过将生成的摘要与参考摘要进行比较来评估摘要质量,计算精确度、召回率和 F1 分数。 |
| EleutherAI | 一个用于在不同评估任务上测试 LLM 的框架。 |
| HELM | 一个用于评估 LLM 的框架,侧重于实际模型部署中重要的 12 个不同方面。 |
| 多样性 | 评估响应的多样性和独特性,分数越高表示输出越多样化。 |
许多 LLM 评估框架都提供了灵活性,以适应特定领域或自定义评估,解决您用例的关键 RAG 指标。这些框架利用 LLM-as-a-Judge 或 OpenAI 审核 API 来确保对 AI 应用程序的响应进行审核。
使用自定义数据集

首先,从源文档创建问题和真实答案对以用于评估数据集。真实答案是您期望 RAG 系统提供的精确响应。您可以通过多种方式创建这些:
- **手工制作数据集:** 手动创建问题和答案。
- **使用 LLM 创建合成数据:** 利用 T5 或 OpenAI API 等 LLM。
- **使用 Ragas 框架**:这种方法使用 LLM 生成各种问题类型以评估 RAG 系统。
- **使用 FiddleCube**:FiddleCube 是一个系统,可以帮助生成旨在测试过程不同方面的各种问题类型。
创建数据集后,收集检索到的上下文和您的 RAG 管道为每个问题生成的最终答案。
**图 5:** *这里是四个评估指标的示例:*
- **问题**:一组基于源文档的问题。
- **真实答案**:对查询的预期准确答案。
- **上下文**:RAG 管道为每个查询检索到的上下文。
- **答案**:RAG 管道为每个查询生成的答案。

结论:运行测试时要寻找什么
要了解 RAG 系统是否正常运行,您需要确保:
- **检索有效性**:检索到的信息在语义上相关。
- **响应相关性:** 生成的响应有意义。
- **生成响应的连贯性**:响应连贯且逻辑连接。
- **最新响应**:响应基于当前数据。
端到端 (E2E) 评估 RAG 应用程序
端到端 (E2E) 评估评估整个检索增强生成 (RAG) 系统的整体性能。以下是您可以衡量的一些关键因素:
- **帮助性**:衡量系统响应在多大程度上有助于用户实现其目标。
- **基础性**:确保响应基于检索到的上下文中的可验证信息。
- **延迟**:监控系统的响应时间,以确保其满足所需的速度和效率标准。
- **简洁性**:评估响应是否简洁但全面。
- **一致性**:确保系统在不同查询和上下文中始终提供高质量的响应。
例如,您可以使用**答案语义相似性**和**正确性**等指标来衡量生成响应的质量。
衡量语义相似性将告诉您生成的答案与真实答案之间的差异,范围从 0 到 1。该系统使用余弦相似性来评估向量空间中的对齐。
检查答案正确性评估生成的答案与真实答案之间的总体一致性,结合事实正确性(由 F1 分数衡量)和答案相似性分数。
RAG 评估仅仅是个开始

RAG 评估仅仅是个开始。它为系统的持续改进和长期成功奠定了基础。最初,它可以帮助您识别和解决与检索准确性、上下文相关性和响应质量相关的即时问题。然而,随着您的 RAG 系统发展并受到新数据、用例和用户交互的影响,您需要继续测试和校准。
通过持续评估您的应用程序,您可以确保系统适应不断变化的需求并随着时间的推移保持其性能。您应该定期校准所有组件,例如嵌入模型、检索算法和 LLM 本身。这个迭代过程将帮助您识别和修复新出现的问题,优化系统参数,并整合用户反馈。
RAG 评估的实践尚处于早期发展阶段。请保留本指南,并等待更多技术、模型和评估框架的开发。我们强烈建议您将其纳入您的评估过程。
想下载本指南的打印友好版本吗?填写此表格,我们将通过电子邮件向您发送 PDF。
有用的链接
- 加入我们的 Discord 社区
- 查看我们的最新文章
- 试用免费的 Qdrant 集群
- 为您的应用程序选择正确的部署选项。联系销售
