





























超越多模态向量:使用 Superlinked 和 Qdrant 进行酒店搜索
Filip Makraduli, David Myriel
·2025 年 4 月 24 日

不仅仅是多模态搜索?
AI 改变了我们寻找产品、服务和内容的方式。现在用户用自然语言表达需求,并期望获得精确、量身定制的结果。
例如,您可能会搜索符合特定条件的巴黎酒店

“埃菲尔铁塔附近价格实惠的豪华酒店,好评如潮,并提供免费停车。” 这不仅仅是一个搜索查询,它还是一组复杂的相互关联的偏好,涵盖了多种数据类型。
在这篇博客中,我们将向您展示我们是如何构建 酒店搜索演示 的。
图 1: Superlinked 生成不同模态的向量,这些向量由 Qdrant 索引和提供,以实现快速、准确的酒店搜索。
此应用程序特别强大之处在于它如何将您的自然语言查询分解为精确的参数。当您在顶部输入问题时,您可以观察左侧边栏中查询参数的动态更新。
在这篇博客中,我们将向您展示 Qdrant 和 Superlinked 如何结合文本理解、数值推理和分类过滤,以创建无缝的搜索体验,满足现代用户期望。
核心组件
图 2: 在典型的搜索或 RAG 应用程序中,嵌入框架 (Superlinked) 将您的数据及其元数据组合成向量。它们被摄取到 Qdrant 集合中并进行索引。

Superlinked 通过将数据嵌入到为每种属性类型设计的专门“空间”中,而不是对所有内容使用单一的嵌入方法,从而使搜索更加智能。
当用户查询“埃菲尔铁塔附近价格实惠的豪华酒店,好评如潮,并提供免费停车”时,Superlinked 使用 LLM 进行自然查询理解并设置权重。这些权重决定了
- 偏好方向(负值表示较低的值,正值表示较高的值)。
- 偏好强度(较高的数字具有较强的影响)。
- 不同属性之间的平衡(例如,price_weight: -1.0 和 rating_weight: 1.0 是平衡的)。
这种权重的灵活性允许用户快速迭代、实验和实现业务逻辑或上下文,比从头开始重建整个搜索系统快得多。然后,Superlinked 应用强制的硬过滤器来缩小结果范围,然后使用加权最近邻搜索对它们进行排名,提供根据用户偏好量身定制的细致、准确的结果。所有向量都存储在 Qdrant 中。
SuperLinked 框架设置: 一旦您设置了 Superlinked 服务器,大部分原型工作就可以直接从示例笔记本中完成。准备就绪后,您可以从 GitHub 存储库托管并通过 Actions 进行部署。
Qdrant 向量数据库: 存储向量最简单的方法是创建一个免费的 Qdrant 云集群。我们有简单的文档向您展示如何获取 API 密钥并更新您的新向量以及运行一些基本搜索。对于此演示,我们已部署了一个实时 Qdrant 云集群。
OpenAI API 密钥: 对于自然语言查询和生成权重,您将需要一个 OpenAI API 密钥
1. 向量空间:智能搜索的基石

Superlinked 创新的核心是空间——专门用于不同数据类型的向量嵌入环境。与将所有数据强制转换为单一嵌入格式的传统方法不同,这些空间尊重不同数据类型的固有特征。
在我们的演示中,四个不同的空间协同工作:描述、评级、价格和评级计数。它们定义如下
# Text data is embedded using a specialized language model
description_space = sl.TextSimilaritySpace(
text=hotel_schema.description,
model=settings.text_embedder_name # all-mpnet-base-v2
)
# Numerical data uses dedicated numerical embeddings with appropriate scaling
rating_space = sl.NumberSpace(
hotel_schema.rating,
min_value=0,
max_value=10,
mode=sl.Mode.MAXIMUM # Linear scale for bounded ratings
)
price_space = sl.NumberSpace(
hotel_schema.price,
min_value=0,
max_value=1000,
mode=sl.Mode.MAXIMUM,
scale=sl.LogarithmicScale() # Log scale for prices that vary widely
)
rating_count_space = sl.NumberSpace(
hotel_schema.rating_count,
min_value=0,
max_value=22500,
mode=sl.Mode.MAXIMUM,
scale=sl.LogarithmicScale() # Log scale for wide-ranging review counts
)
这之所以强大,是因为每个空间都恰当地保留了其领域内的语义关系——同时允许将这些不同的空间组合成一个内聚的搜索体验。
价格经过嵌入以保持其比例关系,文本嵌入捕获语义含义,评级保留其相对质量指标,而评级计数使用对数标度来适当地加权评论数量的重要性。
2. 超越多模态向量搜索:全景图
Qdrant 和 Superlinked 都支持丰富的多模态搜索环境,其中不同的数据类型协同工作而不是相互竞争。对于我们的酒店演示,这意味着
- 文本描述使用理解语义的最新语言模型进行嵌入。
- 价格使用对数标度来正确处理广泛的值。
- 评级以线性方式嵌入以保留其质量指标。
- 评论计数使用对数标度来解释额外评论的边际收益递减。
与将所有数据字符串化为文本再进行嵌入(导致数字之间出现不可预测的非单调关系)或为不同属性维护单独索引的系统不同,Superlinked 创建了一个统一的搜索空间,其中可以同时考虑多个属性,并保留适当的语义关系。
此统一索引的声明异常简单
index = sl.Index(
spaces=[
description_space,
price_space,
rating_space,
rating_count_space,
],
# Additional fields for hard filtering
fields=[hotel_schema.city, hotel_schema.amenities, ...]
)
如果您想更深入地了解算法以及多向量嵌入的工作原理,可以阅读我们的文章。
3. 智能查询处理:从自然语言到结果
Superlinked 中的查询处理系统简化了搜索查询的构建和执行方式。该系统允许用户使用自然语言进行交互,然后将其转换为多维向量操作,从而摆脱了僵化的查询结构。
酒店演示中的查询构建展示了这种能力
query = (
sl.Query(
index,
weights={
price_space: sl.Param("price_weight", description=price_description),
rating_space: sl.Param("rating_weight", description=rating_description),
# Additional space weights...
},
)
.find(hotel_schema)
.similar(description_space.text, sl.Param("description"))
.filter(hotel_schema.city.in_(sl.Param("city")))
# Additional filters...
.with_natural_query(natural_query=sl.Param("natural_query"))
)
分解查询

这种设置使得像“埃菲尔铁塔附近价格实惠的豪华酒店,好评如潮,并提供免费停车”这样的查询能够自动翻译为
- 针对“豪华”和“埃菲尔铁塔”概念的文本相似性搜索
- 针对“价格实惠”(较低范围)的适当价格加权
- 对“免费停车”作为一项设施进行硬过滤
- 搜索“大量”(评分计数)+ 好评(评分)
与依赖检索后重新排名(如果初始检索过于严格可能会错过相关结果)或元数据过滤器(将“价格实惠”等模糊偏好转换为严格边界)的系统不同,此方法在整个过程中保持了搜索的细微差别。
4. 混合搜索的再构想:解决现代搜索问题
当今的搜索领域主要讨论混合搜索——结合关键词匹配以实现精确性,以及向量搜索以实现语义理解。酒店搜索演示通过实现一种多模态混合搜索方法,将这一概念进一步扩展,该方法不仅涵盖文本检索方法,还涵盖整个数据领域。
在酒店搜索演示中,我们看到混合搜索在多个维度上得到了重新构想
- 文本混合搜索:结合精确匹配(针对城市名称、设施关键词)与语义相似性(针对“豪华”或“家庭友好”等概念)
- 数值混合搜索:融合精确范围过滤器(最低/最高价格)与基于偏好的向量相似性(针对“价格实惠”或“高评分”等概念)
- 分类混合搜索:整合硬性分类约束(必须在巴黎)与软性偏好(偏爱具有特定设施的酒店)
这种多维混合方法解决了传统搜索系统面临的挑战
- 当查询跨越多种数据类型时,单模态向量搜索会失败
- 传统混合搜索仍然将关键词和向量组件分开,这意味着它们必须进行适当加权
- 每个属性单独存储会导致复杂的查询结果调和,从而失去语义细微之处
- 纯过滤方法将偏好转换为二元决策,错失了偏好的“强度”
- 重新排名策略可能导致初始检索较弱,尤其是在广义查询的情况下
这种统一的方法在多维搜索空间中保持了所有属性的语义关系,其中偏好成为权重而非过滤器,并且硬约束和软偏好在同一查询中无缝共存。
结果是一种直观且“开箱即用”的搜索体验——无论用户是在寻找“市中心附近拥有良好评价的宠物友好精品酒店”还是“度假区内带泳池的经济型家庭套房”——因为系统理解用户所寻求内容的语义和不同属性之间的关系。
酒店搜索演示展示了这一愿景的实际应用,它预示着未来搜索不仅能理解我们使用的词语,还能理解这些词语所代表的复杂、细致的偏好。
如何构建应用程序
有关更多详细信息,请查看存储库。
否则,您可以克隆应用程序
git clone https://github.com/superlinked/hotel-search-recipe-qdrant.git
后端位于 superlinked_app 下,而前端必须从 frontend_app 构建。
部署后端
使用 superlinked_app/.env-example 作为模板,创建 superlinked_app/.env 并设置自然查询接口所需的 OPENAI_API_KEY,以及 Qdrant 向量数据库所需的 QDRANT_URL 和 QDRANT_API_KEY。
python3.11 -m venv .venv
. .venv/bin/activate
pip install -r requirements.txt
APP_MODULE_PATH=superlinked_app python -m superlinked.server
首次下载 sentence-transformers 模型需要一些时间(取决于网络)。
API 文档将在 localhost:8080/docs 提供。
要摄取数据集,请在您的终端中运行此命令
curl -X 'POST' \
'https://:8080/data-loader/hotel/run' \
-H 'accept: application/json' \
-d ''
请等待摄取完成。您将看到消息。
检查 Qdrant 云仪表盘中的集合
Superlinked 向量摄取完成后,登录 Qdrant 云仪表盘,导航到集合并选择您的默认酒店集合。
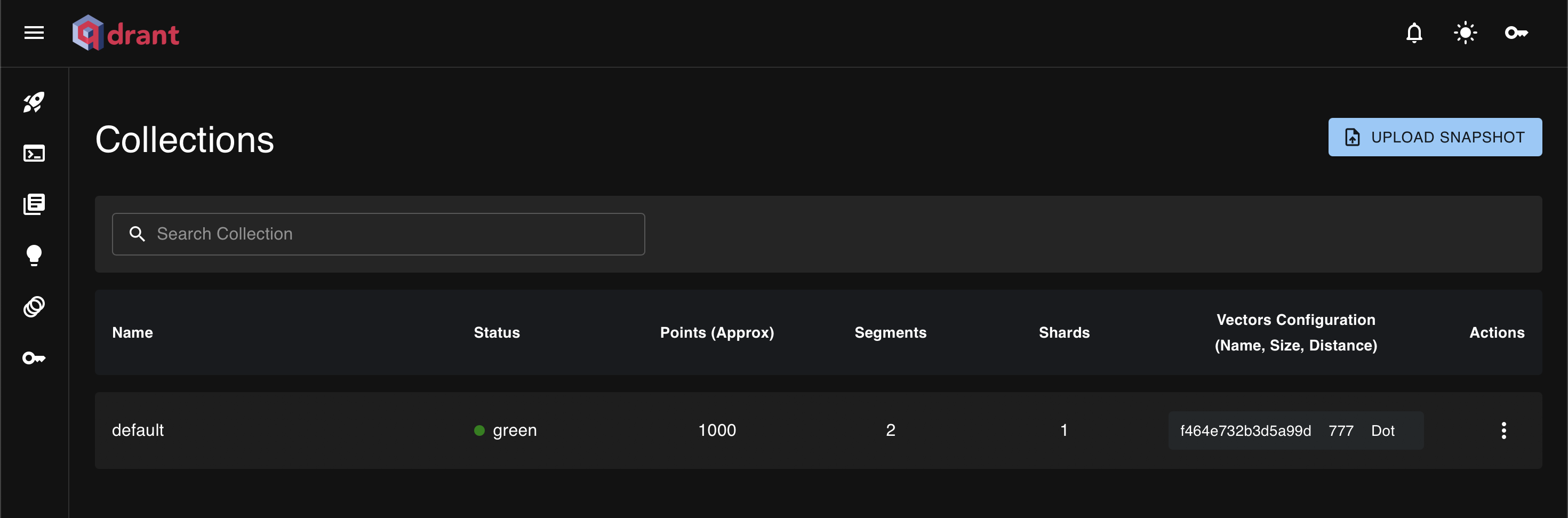
您可以在数据选项卡下浏览单个点,查看有效负载元数据(价格、评级、设施)及其原始向量嵌入。
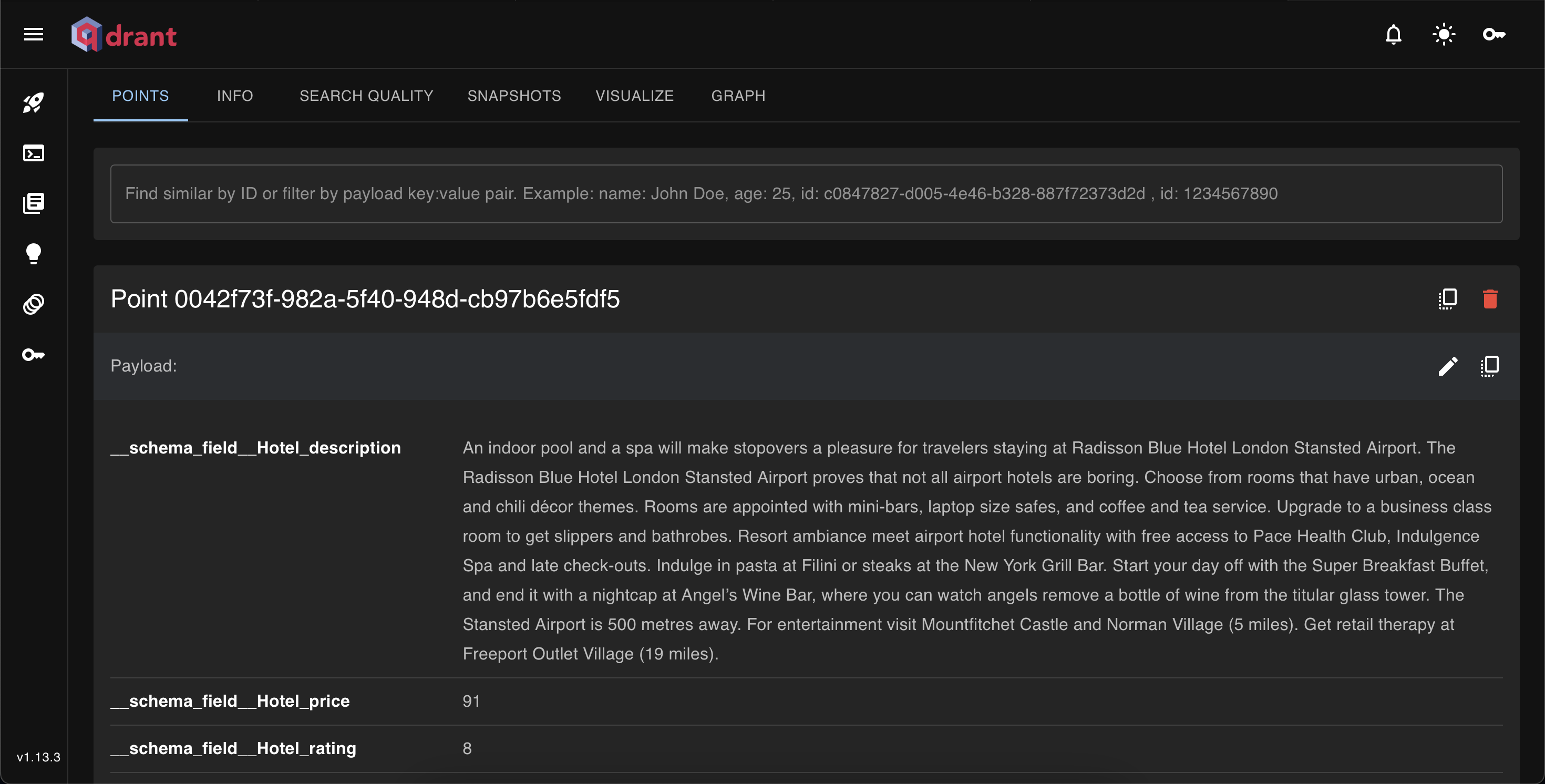
在集合信息部分,您可以使用搜索选项卡应用元数据过滤器或按向量搜索。在搜索质量部分,您还可以监控性能指标(吞吐量、延迟)。
当您的应用程序需要扩展时,请返回 Qdrant 云仪表盘配置自动缩放、备份和快照。这些选项将使您的服务保持可靠且经济高效。
构建前端
cd frontend_app
python3.11 -m venv .venv-frontend
. .venv-frontend/bin/activate
pip install -e .
python -m streamlit run app/frontend/main.py
前端 UI 将在 localhost:8501 提供。
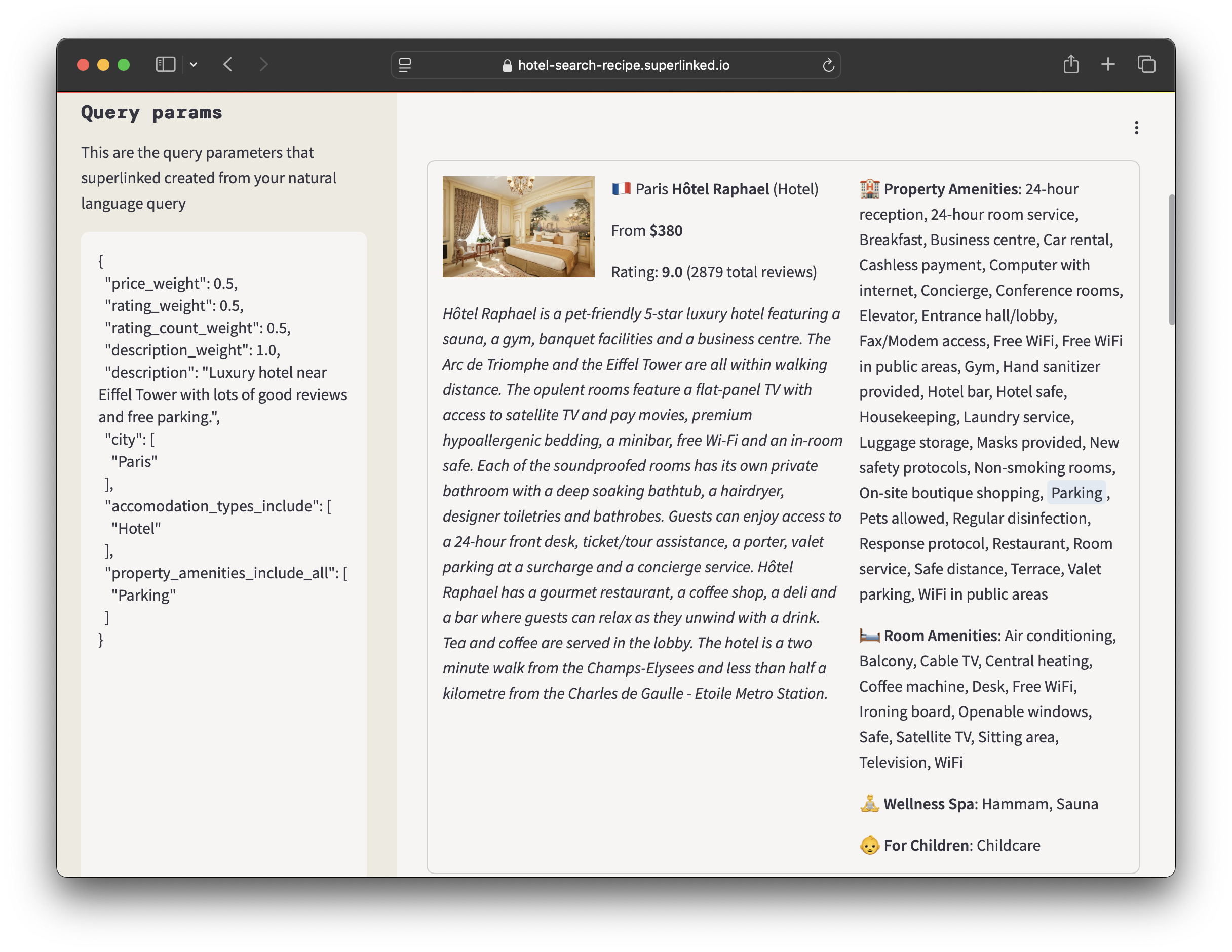
Superlinked CLI
注意: 如果您需要 Superlinked 用于大型项目,您可以使用 Superlinked Cloud。
通过“superlinked cli”,您将能够以批处理引擎、日志记录等组件大规模运行 Superlinked 应用程序。欲了解更多详情,请联系 Superlinked 团队:superlinked.com。
