





























如何使用 CrewAI 和 Qdrant 构建智能代理式 RAG
Kacper Łukawski
·2025 年 1 月 24 日

在最近的一次在线会议中,我们与 CrewAI 合作,这是一个用于构建智能多代理应用程序的框架。如果你错过了,Qdrant 的 Kacper Łukawski 和 CrewAI 的 Tony Kipkemboi 详细介绍了 CrewAI 的功能,并演示了如何利用 Qdrant 创建一个代理式 RAG (检索增强生成) 系统。重点是使用 Obsidian 作为知识库,半自动化电子邮件通信。
本文将指导你完成设置 AI 驱动系统的过程,该系统直接连接到你的电子邮件收件箱和知识库,使其能够分析传入邮件和现有内容,以生成上下文相关的回复建议。
后台代理
尽管我们习惯了基于 LLM 的应用程序通常具有聊天式的界面,即使它不是真正的 UI 而是一个 CLI 工具,许多日常任务也可以在后台自动化,而无需明确的人工操作触发该过程。这个概念也称为环境代理,即代理始终存在,等待触发器采取行动。
CrewAI 的基本概念
感谢 Tony 的参与,我们得以更多地了解 CrewAI,并理解该框架的基本概念。他介绍了代理和团队的概念,以及如何使用它们构建智能多代理应用程序。此外,Tony 描述了 CrewAI 应用程序可以使用的不同类型的内存。
至于 Qdrant 在 CrewAI 应用程序中的作用,它可以作为短期内存或实体内存,因为这两个组件都基于 RAG 和向量嵌入。如果你想了解更多关于 CrewAI 中的内存,请访问 CrewAI 概念。
Tony 做了一个有趣的类比。他将团队比作公司中的不同部门,每个部门都有自己的职责,但它们都协同工作以实现公司的目标。
使用 CrewAI、Qdrant 和 Obsidian 笔记实现电子邮件自动化
我们的网络研讨会重点是构建一个代理式 RAG 系统,以半自动化电子邮件通信。RAG 是此类系统的重要组成部分,因为你不想为无法确定的回复承担责任。该系统将监控你的 Gmail 收件箱,分析传入的电子邮件,如果检测到电子邮件不是垃圾邮件、新闻通讯或通知,则准备回复草稿。
另一方面,该系统还将通过监控本地文件系统中的任何更改来监控 Obsidian 笔记。当文件创建、修改或删除时,系统将自动将这些更改移动到 Qdrant 集合中,从而使知识库始终保持最新。Obsidian 使用 Markdown 文件存储笔记,因此不需要复杂的解析。
这是系统目标架构的简化图
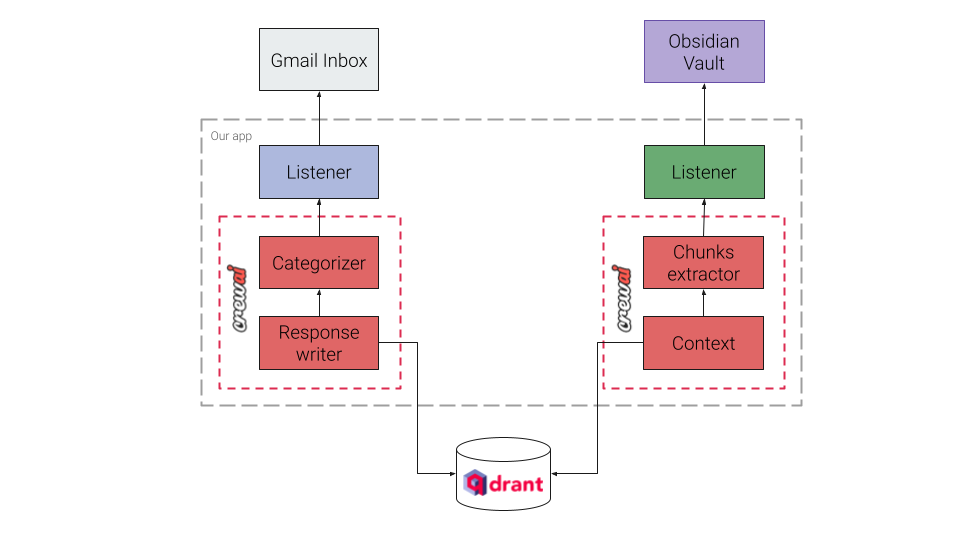
Qdrant 作为知识库,存储 Obsidian 笔记的嵌入。
系统实现
由于我们的系统集成了两个外部 API——Gmail 和文件系统。我们不会详细介绍如何使用这些 API,因为它超出了本次网络研讨会的范围。相反,我们将重点关注 CrewAI 和 Qdrant 的集成,以及 CrewAI 代理的实现。
CrewAI <> Qdrant 集成
由于 CrewAI 和 Qdrant 之间还没有官方集成,我们创建了 RAGStorage 类的自定义实现,它有一个非常直接的接口。
from typing import Optional
from crewai.memory.storage.rag_storage import RAGStorage
class QdrantStorage(RAGStorage):
"""
Extends Storage to handle embeddings for memory entries
using Qdrant.
"""
...
def search(self,
query: str,
limit: int = 3,
filter: Optional[dict] = None,
score_threshold: float = 0,
) -> list[dict]:
...
def reset(self) -> None:
...
完整实现可以在 GitHub 仓库中找到。你可以将其用于自己的项目,或作为自定义实现的参考。如果你想设置一个使用 Qdrant 作为实体和短期内存层的团队,可以这样做
from crewai import Crew, Process
from crewai.memory import EntityMemory, ShortTermMemory
from email_assistant.storage import QdrantStorage
qdrant_location= "https://:6333"
qdrant_api_key = "your-secret-api-key"
embedder_config = {...}
crew = Crew(
agents=[...],
tasks=[...], # Automatically created by the @task decorator
process=Process.sequential,
memory=True,
entity_memory=EntityMemory(
storage=QdrantStorage(
type="entity-memory",
embedder_config=embedder_config,
qdrant_location=qdrant_location,
qdrant_api_key=qdrant_api_key,
),
),
short_term_memory=ShortTermMemory(
storage=QdrantStorage(
type="short-term-memory",
embedder_config=embedder_config,
qdrant_location=qdrant_location,
qdrant_api_key=qdrant_api_key,
),
),
embedder=embedder_config,
verbose=True,
)
两种类型的内存将在 Qdrant 中使用不同的集合名称,因此你可以轻松区分它们,并且数据不会混淆。
我们计划在不久的将来发布一个用于 Qdrant 集成的 CrewAI 工具,敬请期待!
将 Obsidian 笔记加载到 Qdrant
为了演示,我们决定简单地抓取 CrewAI 和 Qdrant 的文档,并将其存储在 Obsidian 笔记中。使用 Obsidian Web Clipper 很容易实现,因为它允许你将网页保存为 Markdown 文件。
假设我们检测到 Obsidian 笔记中的更改,例如新笔记的创建或修改,我们希望将这些更改加载到 Qdrant。我们可能会使用一些分块方法,从基本的固定大小分块开始,或者直接进行语义分块。然而,LLM 也以其将文本分成有意义部分的能力而闻名,所以我们决定尝试一下它们。此外,在许多情况下,标准分块就足够了,但我们也想测试 Anthropic 引入的上下文检索概念。简而言之,其思想是使用 LLM 为每个分块生成一个简短的上下文,以便将分块置于整个文档的上下文中。
事实证明,在 CrewAI 中实现这样的团队非常简单。团队中有两个参与者——一个负责分块文本,另一个负责生成上下文。两者都可以在 YAML 文件中定义,如下所示
chunks_extractor:
role: >
Semantic chunks extractor
goal: >
Parse Markdown to extract digestible pieces of information which are
semantically meaningful and can be easily understood by a human.
backstory: >
You are a search expert building a search engine for Markdown files.
Once you receive a Markdown file, you divide it into meaningful semantic
chunks, so each chunk is about a certain topic or concept. You're known
for your ability to extract relevant information from large documents and
present it in a structured and easy-to-understand format, that increases
the searchability of the content and results quality.
contextualizer:
role: >
Bringing context to the extracted chunks
goal: >
Add context to the extracted chunks to make them more meaningful and
understandable. This context should help the reader understand the
significance of the information and how it relates to the broader topic.
backstory: >
You are a knowledge curator who specializes in making information more
accessible and understandable. You take the extracted chunks and provide
additional context to make them more meaningful by bringing in relevant
information about the whole document or the topic at hand.
CrewAI 使定义这些代理变得非常容易,即使是非技术人员也能理解和修改 YAML 文件。
另一个 YAML 文件定义了代理应该执行的任务
extract_chunks:
description: >
Review the document you got and extract the chunks from it. Each
chunk should be a separate piece of information that can be easily understood
by a human and is semantically meaningful. If there are two or more chunks that
are closely related, but not put next to each other, you can merge them into
a single chunk. It is important to cover all the important information in the
document and make sure that the chunks are logically structured and coherent.
<document>{document}</document>
expected_output: >
A list of semantic chunks with succinct context of information extracted from
the document.
agent: chunks_extractor
contextualize_chunks:
description: >
You have the chunks we want to situate within the whole document.
Please give a short succinct context to situate this chunk within the overall
document for the purposes of improving search retrieval of the chunk. Answer
only with the succinct context and nothing else.
expected_output: >
A short succinct context to situate the chunk within the overall document, along
with the chunk itself.
agent: contextualizer
YAML 不足以让代理工作,所以我们需要在 Python 中实现它们。代理的角色、目标和背景故事,以及任务描述和预期输出,都用于构建发送给 LLM 的提示。但是,代码定义了要使用的 LLM 以及交互的一些其他参数,例如结构化输出。我们大量依赖 Pydantic 模型来定义任务的输出,以便应用程序可以轻松处理响应,例如将它们存储在 Qdrant 中。
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from email_assistant import models
...
@CrewBase
class KnowledgeOrganizingCrew(BaseCrew):
"""
A crew responsible for processing raw text data and converting it into structured knowledge.
"""
agents_config = "config/knowledge/agents.yaml"
tasks_config = "config/knowledge/tasks.yaml"
@agent
def chunks_extractor(self) -> Agent:
return Agent(
config=self.agents_config["chunks_extractor"],
verbose=True,
llm="anthropic/claude-3-5-sonnet-20241022",
)
...
@task
def contextualize_chunks(self) -> Task:
# The task description is borrowed from the Anthropic Contextual Retrieval
# See: https://www.anthropic.com/news/contextual-retrieval/
return Task(
config=self.tasks_config["contextualize_chunks"],
output_pydantic=models.ContextualizedChunks,
)
...
@crew
def crew(self) -> Crew:
"""Creates the KnowledgeOrganizingCrew crew"""
return Crew(
agents=self.agents, # Automatically created by the @agent decorator
tasks=self.tasks, # Automatically created by the @task decorator
process=Process.sequential,
memory=True,
entity_memory=self.entity_memory(),
short_term_memory=self.short_term_memory(),
embedder=self.embedder_config,
verbose=True,
)
完整实现同样可以在 GitHub 仓库中找到。
在 Gmail 收件箱中起草电子邮件
此时,我们的笔记已经存储在 Qdrant 中,我们可以使用这些笔记作为事实依据在 Gmail 收件箱中撰写电子邮件。系统将监控 Gmail 收件箱,如果检测到不是垃圾邮件、新闻通讯或通知的电子邮件,它将根据存储在 Qdrant 中的知识库起草回复。同样,这意味着我们需要使用两个代理——一个用于检测传入电子邮件的类型,另一个用于起草回复。
这些代理的 YAML 文件可能如下所示
categorizer:
role: >
Email threads categorizer
goal: >
Automatically categorize email threads based on their content.
backstory: >
You're a virtual assistant with a knack for organizing information.
You're known for your ability to quickly and accurately categorize email
threads, so that your clients know which ones are important to answer
and which ones are spam, newsletters, or other types of messages that
do not require attention.
Available categories: QUESTION, NOTIFICATION, NEWSLETTER, SPAM. Do not make
up new categories.
response_writer:
role: >
Email response writer
goal: >
Write clear and concise responses to an email thread. Try to help the
sender. Use the external knowledge base to provide relevant information.
backstory: >
You are a professional writer with a talent for crafting concise and
informative responses. You're known for your ability to quickly understand
the context of an email thread and provide a helpful and relevant response
that addresses the sender's needs. You always rely on your knowledge base
to provide accurate and up-to-date information.
类别集是预定义的,因此分类器不应发明新类别。任务定义如下
categorization_task:
description: >
Review the content of the following email thread and categorize it
into the appropriate category. There might be multiple categories that
apply to the email thread.
<messages>{messages}</messages>
expected_output: >
A list of all the categories that the email threads can be classified into.
agent: categorizer
response_writing_task:
description: >
Write a response to the following email thread. The response should be
clear, concise, and helpful to the sender. Always rely on the Qdrant search
tool, so you can get the most relevant information to craft your response.
Please try to include the source URLs of the information you provide.
Only focus on the real question asked by the sender and do not try to
address any other issues that are not directly related to the sender's needs.
Do not try to provide a response if the context is not clear enough.
<messages>{messages}</messages>
expected_output: >
A well-crafted response to the email thread that addresses the sender's needs.
Please use simple HTML formatting to make the response more readable.
Do not include greetings or signatures in your response, but provide the footnotes
with the source URLs of the information you used, if possible.
If the provided context does not give you enough information to write a response,
you must admit that you cannot provide a response and write "I cannot provide a response.".
agent: response_writer
我们特别要求代理包含他们提供信息的来源 URL,以便发件人和收件人都可以验证信息。
工作系统
我们已经定义了两个团队,应用程序已准备好运行。剩下的唯一事情是监控 Gmail 收件箱和 Obsidian 笔记的变化。我们使用 watchdog 库监控文件系统,使用 google-api-python-client 监控 Gmail 收件箱,但我们不会详细介绍如何使用这些库,因为集成代码会使这篇博客文章过长。
如果你打开应用程序的主文件,你会发现它非常简单。它运行两个独立的线程,一个用于监控 Gmail 收件箱,另一个用于监控 Obsidian 笔记。如果检测到任何事件,应用程序将运行相应的团队来处理数据,生成的响应将分别发送回电子邮件线程或 Qdrant 集合。不需要用户界面,因为你的环境代理正在后台工作。
成果
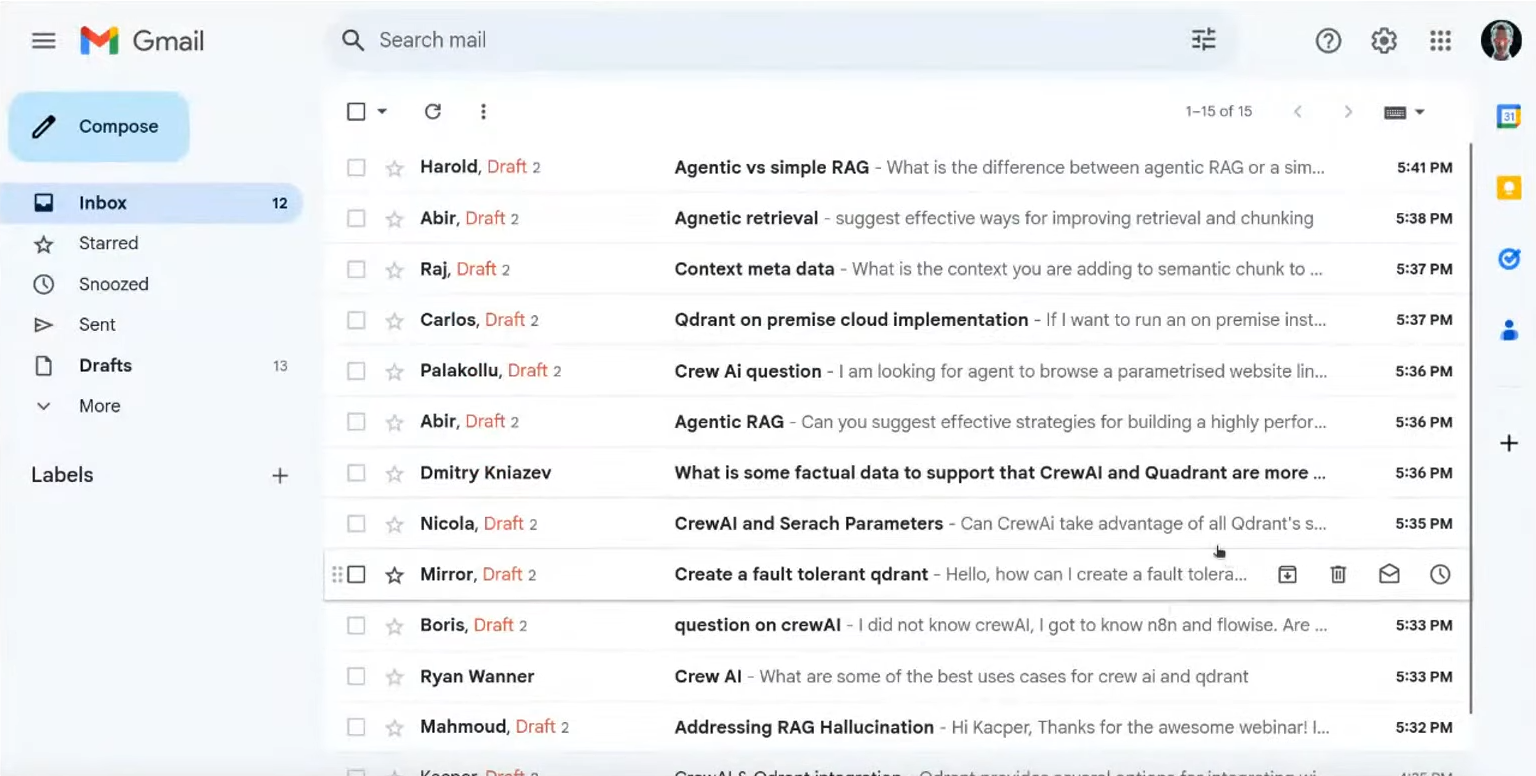
系统现在已准备好运行,它可以半自动化电子邮件通信,并保持知识库最新。如果你设置得当,你可以期望系统起草对不是垃圾邮件、新闻通讯或通知的电子邮件的回复,这样你的电子邮件收件箱可能看起来像这样,即使在你睡觉的时候
材料
像往常一样,我们准备了网络研讨会的视频录像,以便你可以随时观看
演示的源代码可在 GitHub 上获取,因此如果你想自己尝试一下,请随意克隆或 fork 仓库并按照 README 文件中的说明进行操作。
你是否正在使用 CrewAI 和 Qdrant 构建代理式 RAG 应用程序?请加入我们的 Discord 社区并分享你的经验!
