高成本效益地上传和搜索大型 Collection
| 时间:2 天 | 级别:高级 |
|---|
在本教程中,我们将介绍一种方法,以便高成本效益地上传、索引和搜索大量数据,并以真实世界数据集 LAION-400M 为例。
本教程的目标是演示索引和搜索大型数据集所需的最低资源量,同时仍然保持合理的搜索延迟和准确性。
所有相关的代码片段都可以在 GitHub 仓库 中找到。
本教程推荐的 Qdrant 版本是 v1.13.5 及更高版本。
数据集
我们将使用的数据集是 LAION-400M,这是一个包含约 4 亿个向量的集合,这些向量是从 Common Crawl 数据集中提取的图像中获得的。每个向量是 512 维的,并使用 CLIP 模型生成。
向量关联了许多元数据字段,例如 url、caption、LICENSE 等。
总载荷大小约为 200 GB,向量大小为 400 GB。
数据集以 409 个分块的形式提供,每个分块包含约 100 万个向量。我们将使用以下 python 脚本 逐个上传数据集分块。
硬件
经过一些初步实验,我们确定了完成此任务所需的最低硬件配置
- 8 个 CPU 核心
- 64GB 内存
- 650GB 磁盘空间

硬件配置
此配置足以在单用户模式下索引和探索数据集;延迟足够合理,可以构建交互式图表并在仪表板中导航。
当然,对于生产级配置,您可能需要更多 CPU 核心和内存。
对于此实验,确保高网络带宽非常重要,因此请将客户端和服务器部署在同一区域。
上传和索引
我们将使用以下 python 脚本 逐个上传数据集分块。
export QDRANT_URL="https://xxxx-xxxx.xxxx.cloud.qdrant.io"
export QDRANT_API_KEY="xxxx-xxxx-xxxx-xxxx"
python upload.py
该脚本将逐个下载 LAION 数据集的分块,并将其上传到 Qdrant。中间数据不会持久化到磁盘,因此该脚本不需要客户端有太多磁盘空间。
让我们看看我们使用的 Collection 配置
client.create_collection(
QDRANT_COLLECTION_NAME,
vectors_config=models.VectorParams(
size=512, # CLIP model output size
distance=models.Distance.COSINE, # CLIP model uses cosine distance
datatype=models.Datatype.FLOAT16, # We only need 16 bits for float, otherwise disk usage would be 800Gb instead of 400Gb
on_disk=True # We don't need original vectors in RAM
),
# Even though CLIP vectors don't work well with binary quantization, out of the box,
# we can rely on query-time oversampling to get more accurate results
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
)
),
optimizers_config=models.OptimizersConfigDiff(
# Bigger size of segments are desired for faster search
# However it might be slower for indexing
max_segment_size=5_000_000,
),
# Having larger M value is desirable for higher accuracy,
# but in our case we care more about memory usage
# We could still achieve reasonable accuracy even with M=6 + oversampling
hnsw_config=models.HnswConfigDiff(
m=6, # decrease M for lower memory usage
on_disk=False
),
)
有几个重要点需要注意
- 我们对向量使用
FLOAT16数据类型,这使我们能够以FLOAT32一半的大小存储向量。对于此数据集,准确性没有显著损失。 - 我们使用带有
always_ram=True的BinaryQuantization来启用查询时过采样 (oversampling)。这使我们能够获得准确且资源高效的搜索,尽管 512 维的 CLIP 向量开箱即用时与二进制量化配合不佳。 - 我们使用带有
m=6的HnswConfig来减少内存使用。我们将在下一节深入探讨内存使用情况。
此配置的目标是确保搜索的预取 (prefetch) 组件永远不需要从磁盘加载数据,并且至少有最小版本的向量和向量索引始终驻留在内存 (RAM) 中。搜索的第二阶段可以明确确定我们可以承受多少次从磁盘加载数据。
在我们的实验中,上传过程的速度为每秒 5000 个点。索引过程与上传并行进行,速度约为每秒 4000 个点。
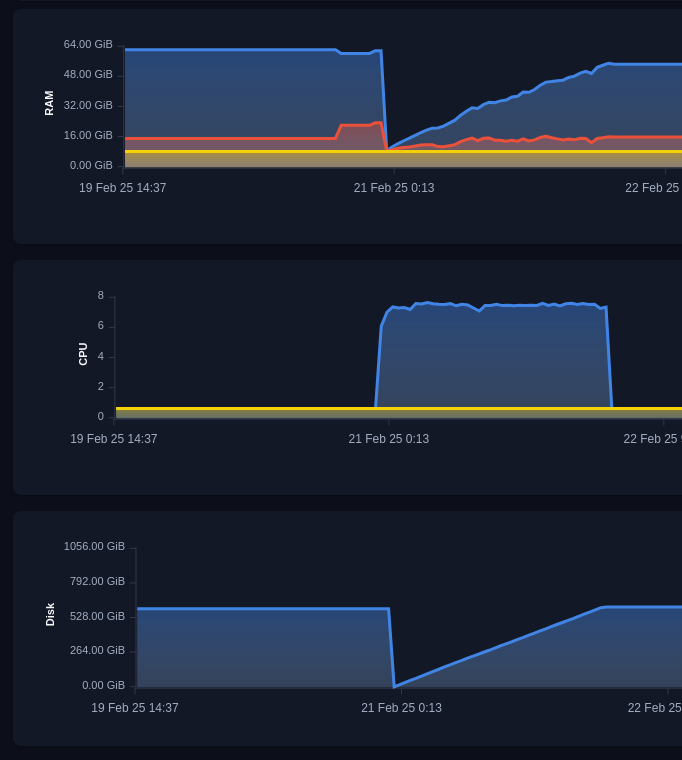
上传和索引过程
内存使用
上传和索引过程完成后,让我们详细看看 Qdrant 服务器的内存使用情况。
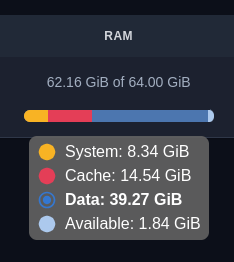
内存使用情况
宏观上看,内存使用由 3 个组件组成
- 系统内存 - 8.34GB - 这是为内部系统和操作系统保留的内存,它不取决于数据集大小。
- 数据内存 - 39.27GB - 这是 qdrant 进程的常驻内存,它不能被驱逐,如果超出限制,qdrant 进程将崩溃。
- 缓存内存 - 14.54GB - 这是 qdrant 使用的磁盘缓存。它对于快速搜索是必需的,但如果需要可以被驱逐。
我们最感兴趣的是数据内存和缓存内存。让我们看看这些组件中具体存储了什么。
在我们的场景中,Qdrant 使用内存存储以下组件
- 存储向量
- 存储向量索引
- 存储点(Point)的 ID 和版本信息
向量的大小
在我们的场景中,我们只在内存 (RAM) 中存储量化后的向量,因此计算所需大小相对容易
400_000_000 * 512d / 8 bits / 1024 (Kb) / 1024 (Mb) / 1024 (Gb) = 23.84Gb
向量索引的大小
向量索引稍微复杂一些,因为它不是一个简单的矩阵。
在内部,它以图中的连接列表形式存储,每个连接是一个 4 字节的整数。
连接数由 HNSW 索引的 M 参数定义,在我们的例子中,顶层是 6,第 0 层是 2 x M。
这给我们以下估算
400_000_000 * (6 * 2) * 4 bytes / 1024 (Kb) / 1024 (Mb) / 1024 (Gb) = 17.881Gb
实际上,由于我们在 Qdrant v1.13.0 中实现的 压缩,索引的大小会稍微小一些,但这仍然是一个很好的估算值。
Qdrant 中的 HNSW 索引作为 mmap 存储,如果需要,可以从内存 (RAM) 中驱逐。因此,HNSW 的内存消耗属于 缓存内存 的类别。
ID 和版本的大小
Qdrant 必须存储有关每个点(Point)的附加信息,例如 ID 和版本。此信息在每个请求中都需要,因此将其保留在内存 (RAM) 中以便快速访问非常重要。
让我们看看 Qdrant 的内部结构,了解存储这些信息需要多少内存。
// This is s simplified version of the IdTracker struct
// It omits all optimizations and small details,
// but gives a good estimation of memory usage
IdTracker {
// Mapping of internal id to version (u64), compressed to 4 bytes
// Required for versioning and conflict resolution between segments
internal_to_version, // 400M x 4 = 1.5Gb
// Mapping of external id to internal id, 4 bytes per point.
// Required to determine original point ID after search inside the segment
internal_to_external: Vec<u128>, // 400M x 16 = 6.4Gb
// Mapping of external id to internal id. For numeric ids it uses 8 bytes,
// UUIDs are stored as 16 bytes.
// Required to determine sequential point ID inside the segment
external_to_internal: Vec<u64, u32>, // 400M x (8 + 4) = 4.5Gb
}
在 v1.13.5 版本中,我们引入了一项 重要的优化,将 IdTracker 的内存使用量减少了大约一半。因此,在我们的例子中,IdTracker 的总内存使用量约为 12.4GB。
因此,在我们的例子中,Qdrant 服务器的总预期内存 (RAM) 使用量约为 23.84GB + 17.881GB + 12.4GB = 54.121GB,这与我们观察到的实际内存使用量非常接近:39.27GB + 14.54GB = 53.81GB。
我们不得不对估算进行了一些简化,但这足以理解 Qdrant 服务器的内存使用情况。
搜索
数据集上传和索引完成后,我们可以开始搜索相似向量。
我们可以先在 Web 用户界面 中探索数据集。这样您就可以直观感受搜索性能,而不仅仅是表格中的数字。
Web 用户界面 中的熊图片
Web 用户界面 中的相似熊图片
Web 用户界面 的默认请求不使用过采样,但观察到的结果仍然足以看出图像之间的相似性。
真实数据(Ground truth)
然而,要更准确地评估搜索性能,我们需要将搜索结果与真实数据进行比较。不幸的是,LAION 数据集不包含可用的真实数据,因此我们不得不自己生成。
为此,我们需要对数据集中的每个向量执行全量扫描搜索,并将结果存储在单独的文件中。不幸的是,这个过程非常耗时且需要大量资源,因此我们不得不将查询数量限制在 100 个。我们提供了现成的 真实数据文件 和生成它的 脚本 (需要 512GB 内存的机器和大约 20 小时的执行时间)。
我们的真实数据文件包含 100 个查询,每个查询有 50 个结果。数据集本身的前 100 个向量被用于生成查询。
搜索查询
为了精确控制过采样量,我们将使用以下搜索查询
limit = 50
rescore_limit = 1000 # oversampling factor is 20
query = vectors[query_id] # One of existing vectors
response = client.query_points(
collection_name=QDRANT_COLLECTION_NAME,
query=query,
limit=limit,
# Go to disk
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
rescore=True,
),
),
# Prefetch is performed using only in-RAM data,
# so querying even large amount of data is fast
prefetch=models.Prefetch(
query=query,
limit=rescore_limit,
params=models.SearchParams(
quantization=models.QuantizationSearchParams(
# Avoid rescoring in prefetch
# We should do it explicitly on the second stage
rescore=False,
),
)
)
)
如您所见,此查询包含两个阶段
- 第一阶段是预取 (prefetch),仅使用内存 (RAM) 中的数据执行。它非常快速,使我们能够获得大量候选结果。
- 第二阶段是重新评分 (rescore),使用存储在磁盘上的完整大小向量执行。
通过使用两阶段搜索,我们可以精确控制从磁盘加载的数据量,并确保搜索速度和准确性之间的平衡。
您可以在 eval.py 中找到完整的搜索过程代码。
性能调整
对于此数据集,我们发现一个重要的性能调整是启用 Qdrant 中的 异步 IO。
默认情况下,Qdrant 使用同步 IO,这对于内存中的数据集来说是好的,但当我们需要从磁盘读取大量数据时,这可能会成为瓶颈。
异步 IO(使用 io_uring 实现)允许向磁盘发送并行请求,并充分利用磁盘带宽。
这正是我们在使用原始向量执行大规模重新评分时所寻找的。
我们不必一次读取一个向量并等待磁盘响应 1000 次,而是可以向磁盘发送 1000 个请求并等待它们全部完成。这使我们能够充分利用磁盘带宽并获得更快的结果。
要在 Qdrant 中启用异步 IO,您需要设置以下环境变量
QDRANT__STORAGE__PERFORMANCE__ASYNC_SCORER=true
或在配置文件中设置参数
storage:
performance:
async_scorer: true
在 Qdrant Managed 云中,可以在集群的 配置 选项卡中的 高级优化 部分启用异步 IO。

云中的异步 IO 配置
运行搜索请求
准备工作完成后,我们可以运行搜索请求并评估结果。
您可以在 eval.py 中找到完整的搜索过程代码。
该脚本将运行 100 个带有配置的过采样因子 (oversampling factor) 的搜索请求,并将结果与真实数据进行比较。
python eval.py --rescore_limit 1000
在我们的请求中,我们取得了以下结果
| 重新评分限制 (Rescore Limit) | Precision@50 | 每个请求的时间 |
|---|---|---|
| 1000 | 75.2% | 0.7 秒 |
| 5000 | 81.0% | 2.2 秒 |
使用 m=16 进行的其他实验表明,在使用 rescore_limit=1000 时,我们可以达到 85% 的精确度,但这需要稍微更多的内存。
搜索评估日志
结论
在本教程中,我们演示了如何高成本效益地在 Qdrant 中上传、索引和搜索大型数据集。如果结合查询时过采样,即使是 512 维的向量也可以应用二进制量化。
Qdrant 允许精确控制存储的每个部分位于何处,从而可以在搜索速度和内存使用之间实现良好的平衡。
潜在的改进
在本实验中,我们详细研究了存储的哪些部分负责内存使用以及如何控制它们。
其中一个特别有趣的部分是 VectorIndex 组件,它负责存储向量之间的连接图。
在我们进一步的研究中,我们将探索使 HNSW 对磁盘更友好,以便在不显著损失性能的情况下将其卸载到磁盘的可能性。