
























使用 Qdrant 和 n8n 自动化业务流程:超越简单相似性搜索的应用案例
Evgeniya Sukhodolskaya
·2025年4月4日

低代码自动化工具可轻松快速地将想法变为现实。随着 AI 成为现代业务的核心,具备内置 AI 功能的低代码平台不再是可选项,而是必需品。n8n 就是一个很好的例子,它将强大的 AI 集成与灵活的自动化结合在一起。
向量搜索已成为现代 AI 系统的关键组成部分。虽然它常被用作生成式 AI 的记忆或知识库,但其潜力远不止于此。
在这篇博客中,我们将探讨如何将 Qdrant 这样的专用向量搜索引擎与 n8n 这样的 AI 自动化平台相结合,超越基本的检索增强生成 (RAG) 应用案例。我们将向您展示如何使用向量搜索进行推荐和大数据分析,使用现成的 n8n 工作流程。
在 n8n 中设置 Qdrant
要开始使用 Qdrant 和 n8n,您需要在凭据选项卡中提供您的 Qdrant 实例凭据。从列表中选择 QdrantApi。
Qdrant 云
将 Qdrant 云 连接到 n8n
- 打开云仪表板并选择一个集群。
- 从集群详情中,复制
Endpoint地址——这将在 n8n 中用作Qdrant URL。 - 导航到 API 密钥选项卡并复制您的 API 密钥——这将在 n8n 中用作
API Key。
有关演练,请参阅此分步视频指南。
本地模式
对于完全本地化设置,一个有价值的选择是 n8n 的自托管 AI 入门工具包。这是一个用于本地 AI 和低代码开发环境的开源 Docker Compose 模板。
此工具包包含一个本地 Qdrant 实例。要开始使用
- 按照仓库中的说明安装 AI 入门工具包。
- 使用
docker-compose.yml文件中的值填写连接详情。
AI 入门工具包中 docker-compose.yml 的默认 Qdrant 配置如下所示
qdrant:
image: qdrant/qdrant
hostname: qdrant
container_name: qdrant
networks: ['demo']
restart: unless-stopped
ports:
- 6333:6333
volumes:
- qdrant_storage:/qdrant/storage
在此配置中,n8n Qdrant 凭据中的 Qdrant URL 是 http://qdrant:6333/。要设置本地 Qdrant API 密钥,请将以下行添加到 YAML 文件中
qdrant:
...
volumes:
- qdrant_storage:/qdrant/storage
environment:
- QDRANT_API_KEY=test
保存配置并运行入门工具包后,使用 QDRANT_API_KEY 值(例如 test)作为 API Key,使用 http://qdrant:6333/ 作为 Qdrant URL。
超越简单的相似性搜索
向量搜索确定对象之间语义相似性的能力常用于解决模型的幻觉问题,为基于检索增强生成 (Retrieval-Augmented Generation) 的应用提供内存。
然而,向量搜索不仅仅是充当“知识库”。通过探索“非相似性”的概念,我们开启了新的可能性。通过衡量数据点在语义向量空间中的相似程度,我们也可以分析它们的差异。
相似性和非相似性的结合将向量搜索扩展到推荐、发现搜索和大规模非结构化数据分析。
推荐
在搜索新音乐、电影、书籍或食物时,很难准确地表达我们想要什么。相反,我们常常通过与我们喜欢或不喜欢的例子进行比较来发现新内容。
Qdrant 推荐 API 的构建旨在通过使用正面和负面示例作为锚点来实现这些发现搜索。它有助于根据您的偏好找到新的相关结果。
电影推荐
想象一下家庭影院之夜——你已经看了哈利波特 666 遍了,渴望一部以年轻巫师为主角的新系列。你最喜欢的流媒体服务反复推荐千禧年传奇的所有七部。沮丧之余,你转向 n8n 创建一个智能电影推荐工具。
设置
- 数据集:我们使用来自IMDB Top 1000 Kaggle 数据集的电影描述。
- Embedding 模型:我们将使用 OpenAI
text-embedding-3-small,但您也可以选择任何其他合适的 embedding 模型。
工作流程
一个智能电影推荐工作流程模板由三部分组成
- 电影数据上传器:使用Qdrant Vector Store 节点嵌入电影描述并将其上传到 Qdrant。在模板工作流程中,数据集是从 GitHub 获取的,但您可以使用任何支持的存储,例如Google Cloud Storage 节点。
- AI Agent:使用AI Agent 节点根据您的自然语言请求构建推荐 API 调用。选择一个 LLM 作为“大脑”,并为由 Qdrant 支持的推荐工具定义一个JSON schema。此 schema 允许 LLM 将您的请求映射到工具输入格式。
- 推荐工具:一个子工作流程,使用HTTP Request 节点调用 Qdrant 推荐 API。Agent 从您的聊天消息中提取相关和不相关的电影描述,并将它们传递给工具。该工具使用
text-embedding-3-small嵌入这些描述,并使用 Qdrant 推荐 API 获取电影推荐,然后将结果传回 Agent。
设置好后,运行聊天并询问“一些关于巫师但不是哈利波特的内容”。你得到了什么结果?
如果您想详细了解如何一步步构建此工作流程,请观看下方视频
此推荐场景可轻松适用于任何语言或数据类型(图像、音频、视频)。
大数据分析
将数据映射到反映项目相似性和非相似性关系的向量空间的能力,为数据分析提供了一系列数学工具。
向量搜索专用解决方案旨在处理数十亿个数据点并快速计算它们之间的距离,从而在大规模应用中简化聚类、分类、非相似性采样、去重、插值和异常检测。
将此向量搜索功能与 n8n 等自动化工具相结合,可以创建生产级解决方案,能够监控数据的时间变化、管理数据漂移以及发现看似非结构化数据中的模式。
一个实用的例子胜过千言万语。让我们看看基于 Qdrant 的异常检测和分类工具,这些工具旨在由 n8n AI Agent 节点 用于数据分析自动化。
为了更有趣,这次我们将重点关注图像数据。
异常检测工具
“异常”的一种定义在将数据点的向量表示投影到二维空间后会很直观——Qdrant webUI 提供了此功能。不属于任何聚类的数据点更有可能是异常的。
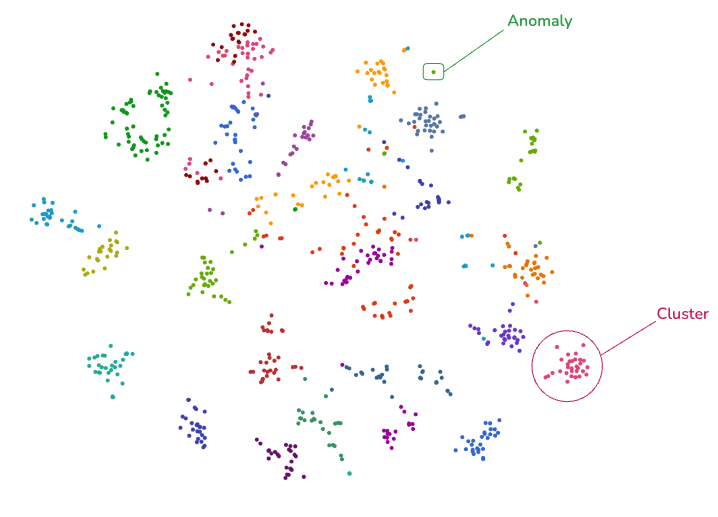
基于此直觉,我们有了构建异常检测工具的方法。我们将以农作物异常检测为例进行演示。Qdrant 将用于
- 存储向量化图像。
- 识别每个作物聚类的“中心”(代表性点)。
- 定义每个聚类的边界。
- 检查新图像是否落在此边界内。如果图像不适合任何聚类,则将其标记为异常。或者,您可以检查图像是否相对于特定聚类异常。
设置
- 数据集:我们使用农作物图像分类数据集。
- Embedding 模型:Voyage AI 多模态 embedding 模型。它可以将图像和文本数据投影到共享的向量空间。
1. 将图像上传到 Qdrant
由于Qdrant Vector Store 节点 不支持预定义列表之外的 embedding 模型(不包括 Voyage AI),我们通过在HTTP Request 节点 中直接调用 API 来嵌入数据并上传到 Qdrant。
工作流程
共有三个工作流程:(1)将图像上传到 Qdrant(2)设置聚类中心和阈值(3)异常检测工具本身。
一个1/3 将图像上传到 Qdrant 模板工作流程包含以下模块
- 检查集合:验证 Qdrant 中是否存在指定名称的集合。如果不存在,则创建一个。
- Payload 索引:在
crop_namepayload(元数据)字段上添加一个payload 索引。此字段存储作物类别标签,对其进行索引可提高 Qdrant 中可过滤搜索的速度。它改变了向量索引的构建方式,使其适应过滤约束下的快速向量搜索。有关更多详情,请参阅此Qdrant 过滤指南。 - 获取图像:使用Google Cloud Storage 节点从 Google Cloud Storage 获取图像。
- 生成 ID:为每个数据点分配 UUID。
- 嵌入图像:使用 Voyage API 嵌入图像。
- 批量上传:将 embedding 分批上传到 Qdrant。
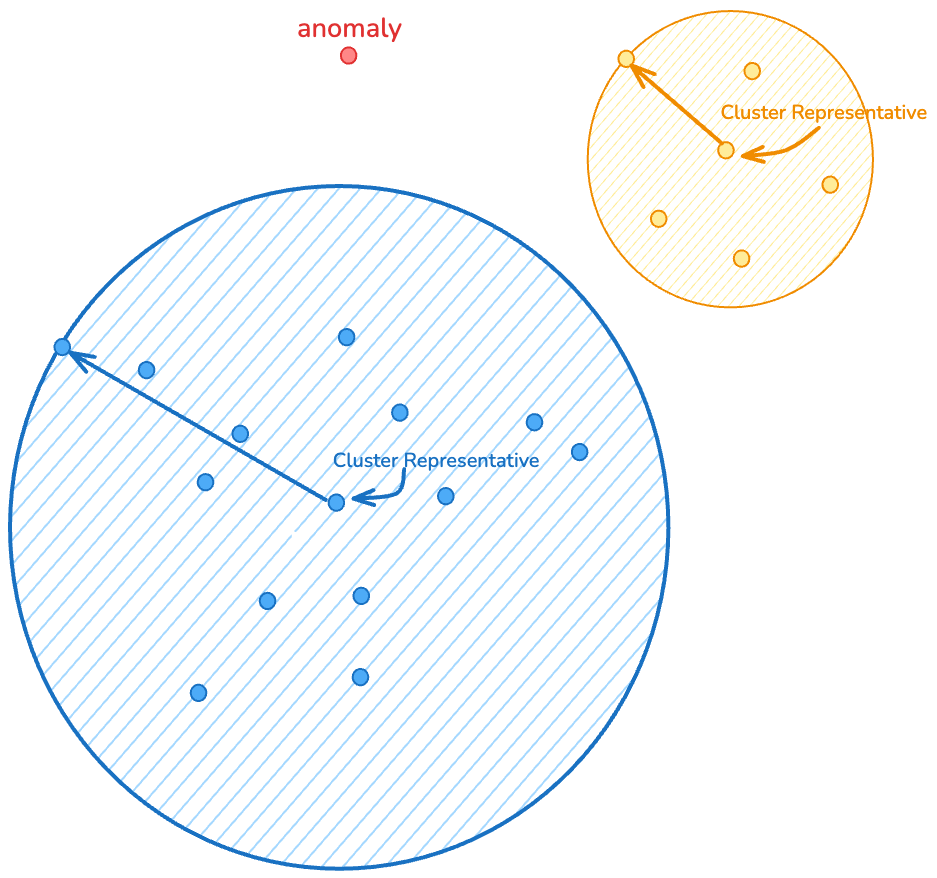
2. 定义聚类代表性点
我们使用了两种方法(这不是一个详尽的列表)来定义聚类代表性点,具体取决于标记数据的可用性
| 方法 | 描述 |
|---|---|
| 中心点 (Medoids) | 聚类中与所有其他聚类点总距离最小的点。此方法需要每个聚类的标记数据。 |
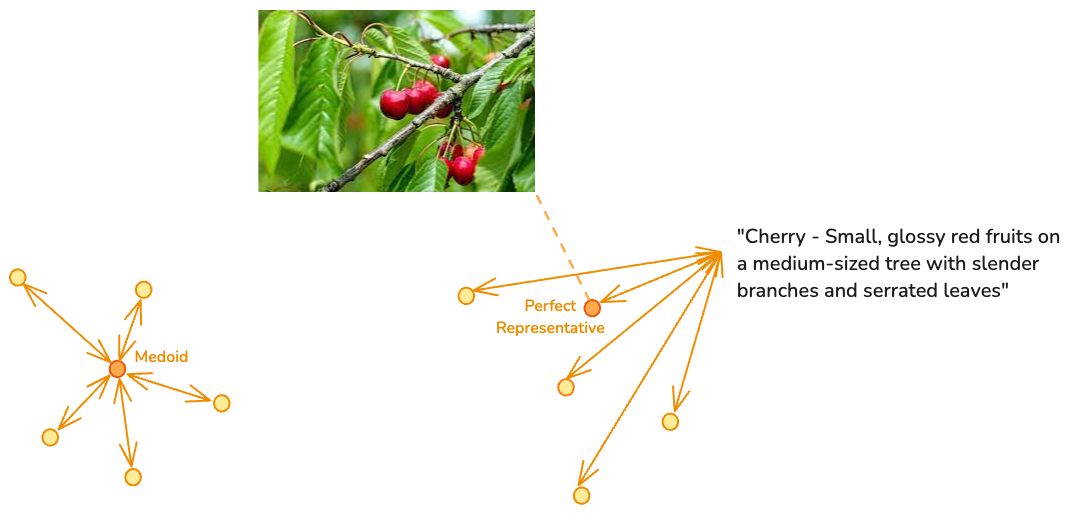
| 完美代表性点 | 由理想聚类成员的文本描述定义的代表性点——Voyage AI embedding 的多模态特性使得这一技巧成为可能。例如,对于樱桃:“生长在中等大小的树上,细长的枝条和锯齿状的叶子,结有小巧、光亮的红色果实。” 向量空间中最接近此描述的图像被选为代表性点。此方法需要通过实验将描述与实际数据对齐。 |
工作流程
这两种方法都在2/3 异常检测模板工作流程中进行了演示。
| 方法 | 步骤 |
|---|---|
| 中心点 (Medoids) | 1. 从 Qdrant 中抽取标记的聚类点。 2. 使用 Qdrant 的距离矩阵 API 计算聚类的成对距离矩阵。此 API 有助于进行可伸缩的聚类分析和数据点关系探索。在此文章中了解更多信息。 3. 对于每个点,计算其与所有其他点的距离总和。总距离最小的点(或者对于 COSINE 距离度量来说相似度最高的点)就是中心点(medoid)。 4. 将此点标记为聚类代表性点。 |
| 完美代表性点 | 1. 为每个聚类定义文本描述(例如,由 AI 生成)。 2. 使用 Voyage 嵌入这些描述。 3. 找到与描述 embedding 最接近的图像 embedding。 4. 将此图像标记为聚类代表性点。 |
3. 定义聚类边界
工作流程
2/3 异常检测模板工作流程中演示的方法对于两种类型的聚类代表性点都适用。
- 在一个聚类中,确定距离聚类代表性点最远的数据点(也可以是距离第 2 或第 X 远的点;定义它的最佳方法是通过实验——对我们来说,距离第 5 远的点效果很好)。由于我们使用 COSINE 相似性,这相当于与聚类代表性点的相反方向最相似的点(其向量乘以 -1)。
- 将代表性点与相应最远点之间的距离保存为聚类边界(阈值)。
4. 异常检测工具
工作流程
完成准备步骤后,您可以设置异常检测工具,如3/3 异常检测模板工作流程中所示。
步骤
- 选择聚类代表性点的定义方法。
- 获取所有聚类以与候选图像进行比较。
- 使用 Voyage AI,在相同的向量空间中嵌入候选图像。
- 计算候选图像与每个聚类代表性点的相似度。如果相似度低于所有聚类的阈值(在聚类边界之外),则该图像被标记为异常。或者,您可以检查它是否对特定聚类(例如樱桃聚类)异常。
图像数据中的异常检测具有多种应用,包括
- 广告审核。
- 垂直农业中的异常检测。
- 食品工业中的质量控制,例如检测咖啡豆异常。
- 在地图瓦片中识别异常,用于自动化地图更新或生态监测等任务。
此工具可适用于这些应用案例,并且与 n8n 集成相结合后,有潜力成为生产级的业务解决方案。
分类工具
异常检测工具也可用于分类,但有一个更简单的方法:K 近邻 (KNN) 分类。
“告诉我你的朋友是谁,我就知道你是谁。”
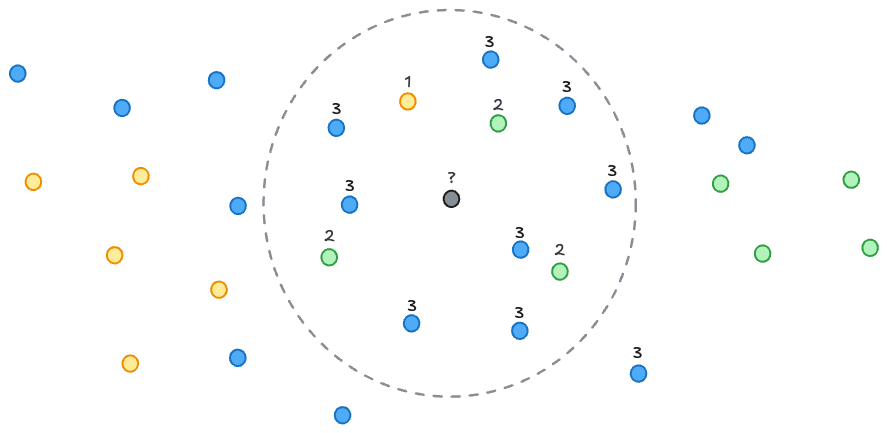
KNN 方法通过分析数据点的已分类邻居来为其打标签,并将该点分配到邻域中的多数类别。此方法不需要标记所有数据点——一小部分标记示例即可作为锚点在整个数据集中传播标签。Qdrant 非常适合此任务,提供具有过滤功能的快速邻居搜索。
让我们构建一个基于 KNN 的图像分类工具。
设置
- 数据集:我们将使用土地利用场景分类数据集。卫星图像分析在生态学、救援行动和地图更新方面都有应用。
- Embedding 模型:与异常检测一样,我们将使用Voyage AI 多模态 embedding 模型。
此外,最好准备测试和验证数据,以确定适合您数据集的最佳 K 值。
工作流程
将图像上传到 Qdrant 可以使用相同的工作流程——1/3 将图像上传到 Qdrant 模板工作流程,只需更换数据集即可。
KNN 分类工具模板包含以下步骤
- 嵌入图像:使用 Voyage 嵌入待分类的候选图像。
- 获取邻居:从 Qdrant 中检索 K 个最接近的标记邻居。
- 多数投票:通过简单的多数投票确定邻域中的主要类别。
- 可选:平局处理:如果出现平局,扩大邻域半径。
当然,这是一个简单的解决方案,还有更高级的方法可以提供更高的精度,且无需标记数据——例如,您可以尝试使用 Qdrant 进行度量学习。
虽然分类在几十年前的机器学习中似乎已得到解决,但在生产环境中处理起来并不简单。数据漂移、类别定义变化、标记错误的数据以及类别之间模糊的差异等问题会带来意想不到的困难,需要对分类器进行持续调整。向量搜索可能是一个不寻常但有效的解决方案,其可伸缩性使其引人注目。
现场演练
要了解 n8n agent 如何在实践中使用这些工具,并回顾“大数据分析”部分的主要思想,请观看我们的集成网络研讨会
接下来做什么?
向量搜索不仅限于相似性搜索或基本 RAG。当与 n8n 等自动化平台结合时,它将成为构建更智能系统的强大工具。可以想想客户支持中的动态路由、基于用户行为的内容审核或数据监控仪表板中的 AI 驱动警报。
本博客展示了如何使用 Qdrant 和 n8n 进行 AI 支持的推荐、分类和异常检测。但这只是一个开始——尝试向量搜索用于
- 去重
- 非相似性搜索
- 多样性采样
结合 Qdrant 和 n8n,您可以创造出许多独特的东西!
